
ML Interview Q Series: Efficient Deep Learning on Edge Devices via Pruning, Quantization, and Distillation.

📚 Browse the full ML Interview series here.
Deploying Models to Edge Devices: You need to deploy a trained deep learning model to a mobile app or an IoT device with limited computation and memory. What techniques can help you reduce the model’s size or computational load so it can run on the edge device? Discuss options like model pruning (removing unnecessary weights), quantization (using lower precision like int8 instead of float32), knowledge distillation into a smaller model, or architecting a smaller network suitable for the device.
A common concern when deploying deep learning models on mobile apps or IoT devices is constrained hardware resources. This usually translates to restricted memory, CPU/GPU horsepower, and sometimes limited battery power. Below are detailed explorations of techniques that help address these constraints, reduce computational cost, and shrink model sizes so that they can run on edge devices without sacrificing too much accuracy.
Model Pruning
Model pruning involves removing weights (or neurons) that contribute minimally to the final output. It is often done in one of two primary ways: unstructured pruning or structured pruning.
Unstructured pruning refers to zeroing out individual weights in a layer that have very small magnitudes, under the assumption they are not critical for the model’s predictive performance. After unstructured pruning, frameworks can often leverage sparse matrix representations to speed up computation, though hardware acceleration support for sparse operations might not always be optimal.
Structured pruning removes entire filters or channels. That leads to simpler computations because entire sub-components of a layer become pruned away, and standard hardware can often realize real speedups with such structured model reductions. However, it can occasionally cause bigger accuracy drops compared to unstructured pruning at a similar pruning ratio.
A standard procedure includes training a model to convergence, measuring the magnitude of weights or some other criterion for importance, pruning the less important ones, then optionally fine-tuning. This iterative approach can be repeated multiple times to maximize compression with minimal accuracy loss.
Pruning can be combined with other compression methods. For instance, you can prune a model, quantize it, and possibly also distill knowledge from it. The synergy of these approaches can achieve larger reductions in storage while preserving accuracy.
Potential pitfalls with pruning include the possibility that an unstructured pruning might not offer significant speedups unless your hardware or inference engine is optimized for sparse computations. Another subtlety is that extremely high pruning levels can degrade accuracy unless carefully done with iterative fine-tuning and hyperparameter tuning (for example, adjusting learning rates or regularization).
Quantization
Quantization transforms network weights (and, in some approaches, activations) from full-precision floating-point (commonly float32 or float16) to lower precision integer types (for example, int8). This significantly decreases the memory footprint of the model and may also provide notable speedups, especially on hardware that has specialized instructions for integer arithmetic.
There are multiple flavors of quantization:
Post-training quantization is the simplest approach, where after training a floating-point model, you convert weights (and possibly activations) to int8 (or a similarly reduced precision). This may yield some accuracy drop if the model is very sensitive to representational precision.
Quantization-aware training integrates quantization operations into the training loop, simulating lower-precision arithmetic during forward passes. This often reduces accuracy loss because the model “learns” to accommodate quantized representations.
Dynamic quantization often applies mainly to activations at inference time, and is frequently used for RNNs or Transformer-like architectures. It dynamically adjusts scale factors, and typically the overhead is lower than full quantization-aware training. However, dynamic quantization might be less accurate than a fully quantization-aware approach.
An example snippet in PyTorch (post-training quantization) might look like:
import torch
from torch.quantization import quantize_dynamic
# Assume 'model' is a trained PyTorch model
quantized_model = quantize_dynamic(
model,
{torch.nn.Linear}, # which modules to quantize dynamically
dtype=torch.qint8 # the desired quantized data type
)
Lower numerical precision can sometimes introduce unexpected numerical instability in layers sensitive to small changes, such as batch normalization or attention modules. One must validate the model’s performance after quantization on representative data.
Knowledge Distillation
Knowledge distillation transfers knowledge from a larger teacher model to a smaller student model. The teacher model is typically a high-capacity network that achieves strong accuracy. The student model is a compact network with fewer parameters. During distillation, the student attempts to mimic not just the hard labels but also the logits (or softened class probabilities) from the teacher. By matching these teacher outputs (often using a Kullback-Leibler divergence term), the student model can learn to generalize more effectively than if it were trained on the dataset labels alone.
A simplified objective for knowledge distillation might include a term like
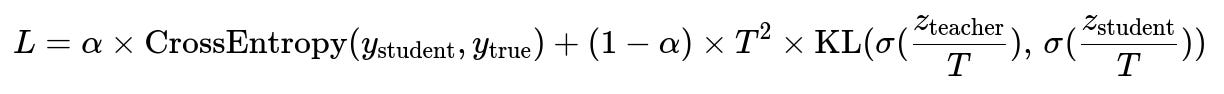
where ( z_\text{teacher} ) and ( z_\text{student} ) are the logits of the teacher and student networks, ( T ) is the temperature scaling factor, and ( \alpha ) is a hyperparameter that balances the hard-label loss with the teacher-based soft-label loss. When ( T > 1), the probabilities in the softmax distribution are “softened,” often making it easier for the student to learn subtle data patterns.
The power of knowledge distillation is that you can achieve an accuracy for the smaller model that surpasses what you would get by training that smaller model from scratch. However, the success depends on architectural compatibility, careful tuning of temperature ( T ), and balancing the loss terms.
Pitfalls to watch out for include ensuring the teacher is significantly more accurate than the student, or else the improvement from distillation may be small. Also, if the student’s capacity is too limited, it might not be able to capture the teacher’s “dark knowledge” adequately.
Architecting a Smaller Network
Rather than starting with a large model architecture, a design from the ground up can be targeted for the edge device. Approaches include using networks like MobileNet, ShuffleNet, or SqueezeNet, which are specifically built to be resource-friendly while retaining accuracy. These architectures often use depthwise separable convolutions or grouped convolutions, along with other architectural tricks, to significantly reduce parameter counts and operations.
For example, MobileNet employs depthwise separable convolutions, which break a standard convolution into two steps: a depthwise convolution that operates on each input channel independently, and a pointwise 1x1 convolution that combines the outputs of the depthwise step. This can drastically cut down the number of parameters and the FLOPs needed compared to standard convolution. Such purposeful architectural designs also often come with built-in heuristics or hyperparameters (like the width multiplier or resolution multiplier in MobileNet) that let you trade off model size and accuracy.
Pitfalls often revolve around ensuring these smaller architectures are truly optimal for your target hardware. Some specialized designs might still be suboptimal for certain chips. Another subtlety is that reducing the network capacity too drastically can cause large accuracy degradation unless there is enough data augmentation or specialized training strategies.
Possible Follow-up Questions
How do you decide which technique to try first if you have extremely strict latency constraints?
If latency is the main concern, you should look at which approach yields the biggest gains in throughput for your hardware. Often, quantization or carefully choosing a smaller architecture yields immediate speedups on embedded devices with specialized integer instructions. Pruning can help, but if your hardware or framework does not exploit sparsity, you might not see the desired latency improvement in practice. Knowledge distillation can be used in combination with a small architecture to preserve accuracy. The best approach is typically to experiment with different compression methods, measure actual speedups on your device, and see which method best meets your latency budget.
Is there a risk of cumulative accuracy loss if you combine these techniques, such as pruning plus quantization plus distillation?
Yes. Combining multiple compression methods can compound accuracy degradations if each step in the pipeline introduces its own error or bias. It is essential to carefully measure performance and run fine-tuning after each compression step. Sometimes the synergy of multiple approaches can be beneficial: prune first, quantize, then distill, or different permutations. However, you have to systematically evaluate the order of operations and do controlled experiments to ensure the final model still meets the application’s accuracy requirements.
How do you handle hardware support limitations when quantizing?
Hardware support is a major factor. For example, some devices have excellent support for 8-bit integer arithmetic but might not handle 16-bit or 4-bit as effectively. If the hardware provides accelerators or instructions for int8, you may see a big speed boost. Conversely, if your hardware lacks specialized integer units, you might see minimal gains or even slower performance from quantization. You also have to confirm the framework you use supports quantized kernels for the layers in your model architecture. If you have custom or exotic layers, you may need to write or configure specialized kernels to take advantage of lower precision.
What happens if you prune too aggressively and then fine-tuning does not recover accuracy?
Over-pruning can remove crucial weights or channels that are vital for capturing key features. In that scenario, even with fine-tuning, the accuracy may not bounce back. A common safeguard is iterative pruning: prune a small fraction of weights, fine-tune, prune again, and so forth. You can also adjust hyperparameters (like the learning rate) to help the model regain accuracy during fine-tuning. If the model cannot recover from heavy pruning, you might have to reduce the pruning ratio or combine it with knowledge distillation to guide fine-tuning.
Why might knowledge distillation fail to significantly reduce the size of the model?
Knowledge distillation does not inherently reduce the size of the teacher model—it just helps train a smaller student model. If the student architecture chosen is already at the limit of minimal size, it may not have enough capacity to absorb much knowledge from the teacher. In that case, the gains in accuracy from distillation might be marginal. Another reason is that you might not have chosen a well-structured approach for matching teacher and student distributions. Tuning the temperature or balancing the distillation loss with the classical loss is critical. If done incorrectly, knowledge distillation might not yield a performance benefit.
How do we measure success beyond raw accuracy?
It is crucial to look at memory footprint, model file size, inference latency (on real hardware, not just a simulator), battery consumption on mobile, peak memory usage, and possibly even metrics such as mean time to inference or QPS (queries per second) if you do batch processing. You should also measure how stable the model predictions are under various real-world conditions, especially if quantization or pruning might degrade numerical stability. Another important measure is how many compute cycles or operations (FLOPs) the model requires, which can impact cost if your application scales or if you pay for compute cycles (e.g., battery usage for IoT or device-heat constraints).
When should we consider building a new smaller architecture from scratch rather than compressing a big model?
If you know from the start that your use case is extremely resource-limited, it is often more effective to choose or design a specialized architecture (like MobileNet, SqueezeNet, etc.) that is inherently efficient. Compressing a large model might not be as optimal if it was originally designed for huge datasets and large GPU clusters. Additionally, if your domain has specific patterns or data structures, a smaller dedicated architecture can sometimes outperform a pruned/quantized large model. However, if you already have a very high-performing large model, methods like pruning, quantization, or distillation can be easier to apply than redesigning the entire architecture.
Are there tricks for deploying these compressed models efficiently in real apps?
It helps to use hardware-accelerated libraries or specialized runtimes, such as TensorFlow Lite for mobile, PyTorch Mobile, ONNX Runtime with optimization flags, or vendor-specific SDKs on certain IoT devices. These frameworks often have pre-built optimizations for integer arithmetic, or they can handle sparse matrices in some cases. Another trick is to keep the model fully quantized end to end to avoid overhead from repeatedly casting between float and integer. Furthermore, fusing operations (like combining convolution and batch normalization) into a single fused kernel can also reduce inference overhead. Tools that do graph-level optimizations can remove redundant operations and further shrink the computational graph.
Could you show an example of quantization-aware training in PyTorch?
Quantization-aware training in PyTorch typically proceeds by preparing the model with special quantization layers, training it, then converting it to an integer representation for deployment. A simplified example can look like this:
import torch
import torch.quantization
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class SmallModel(nn.Module):
def __init__(self):
super(SmallModel, self).__init__()
self.conv = nn.Conv2d(1, 8, kernel_size=3, stride=1, padding=1)
self.fc = nn.Linear(8*28*28, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.conv(x))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
model_fp32 = SmallModel()
# Specify quantization config
model_fp32.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
# Fuse layers if needed. Example: fuse conv+bn+relu
# model_fp32 = torch.quantization.fuse_modules(model_fp32, [])
# Prepare QAT
model_qat = torch.quantization.prepare_qat(model_fp32, inplace=False)
# Train with quantization aware training
optimizer = optim.SGD(model_qat.parameters(), lr=0.01)
for epoch in range(10):
# Your training loop
pass
# Convert to a quantized model
model_int8 = torch.quantization.convert(model_qat)
After this conversion, weights and activations during inference are int8 (except for layers that can’t be quantized). In practice, you would measure final accuracy, and compare it to the floating-point baseline.
Such approach helps the model remain robust under lower-precision representations.
Below are additional follow-up questions
How do you manage on-device updates or re-training when a model needs to adapt to new data distributions at the edge?
When a model is deployed on a resource-constrained edge device, it is common for data distributions to drift over time, or for new classes/events to emerge. Continuously updating or re-training on the device might be infeasible due to limited computational resources, memory, and battery constraints. One possible solution is to employ a “hybrid” strategy. Here are the detailed considerations:
Offloading Training to the Cloud Often, the device can collect a buffer of newly observed data, then periodically send that data to a server for retraining or fine-tuning. The server—having ample computational resources—updates the weights or re-trains a new model. It then sends a compressed version back to the device. This approach reduces on-device training overhead. However, it introduces latency in model updates and requires reliable connectivity.
On-Device Fine-Tuning In certain scenarios, limited on-device fine-tuning can be done with smaller subsets of parameters (such as only final classification layers). This is typically accompanied by careful memory budgeting. Approaches like incremental learning or parameter-efficient adapters (e.g., LoRA in the NLP domain) can reduce the number of parameters that must be updated, making on-device fine-tuning more viable. Still, you risk overfitting or catastrophic forgetting if the device’s training data is small or not representative.
Periodic Distillation A teacher-student paradigm can be used to push incremental knowledge to the edge. The teacher remains on the cloud, collecting or training on new data. The teacher’s updated knowledge is distilled into the on-device student model. This keeps the student model’s size small while gradually incorporating new knowledge.
Pitfalls and Edge Cases
If connectivity is poor or data is large, sending data back to the cloud might be impractical.
If the model update frequency is too high, battery constraints could be exceeded.
Over-the-air update processes should ensure integrity and security to prevent corrupt or malicious model updates.
Drastically shifting distributions (e.g., a camera feed in a new environment) may necessitate more frequent updates or a robust adaptation strategy.
How do you ensure that on-device quantization does not degrade model outputs for certain rare or edge-case inputs?
Quantization Calibration Post-training static quantization typically requires calibration, using a representative dataset to determine scaling factors that map floating-point values to lower-precision integers. If the calibration data does not adequately capture rare or extreme edge cases, the quantized model could exhibit large performance drops when encountering out-of-distribution or boundary inputs.
Dynamic Ranges Even with a representative calibration set, certain input channels or layers might have activation ranges that occasionally spike. If the range is not captured, the quantized results for those spikes could saturate or clip. This is especially problematic in tasks like object detection, where background or unusual lighting conditions can produce outliers.
Quantization-Aware Training Including potential outliers or specialized data augmentations in the training set for quantization-aware training can reduce unexpected errors. The model learns to handle low-precision representations, including those that affect outlier activation ranges.
Validation on Rare Scenarios Be sure to test thoroughly on corner cases—like extreme weather conditions for a camera-based model or unusual user interactions for a voice-based model. If performance degrades severely, you may want to revert those particular layers to float16 or consider an alternative quantization approach (e.g., mixed-precision or per-channel quantization).
Pitfalls
Overly aggressive range clipping can remove subtle features needed for correct classification.
If only a tiny portion of your validation set contains these rare cases, you might not detect a significant performance cliff until deployment in real-world usage.
Are there concerns with reliability and robustness when you compress a model, for example, sensitivity to noise in sensor data?
Compression and Noise Sensitivity When models are heavily pruned or quantized, they sometimes become more sensitive to input perturbations, especially if the compression process has left fewer “redundant” pathways. Sensor data on edge devices is often noisy due to environmental factors, cheap hardware, or physical conditions such as temperature or vibration.
Robust Training One mitigation approach is to incorporate noise augmentation during training or fine-tuning. If the network learns to handle artificially corrupted data (e.g., salt-and-pepper noise for images, random amplitude changes for audio), it can build more robust representations that do not degrade severely under real-world noise.
Error Correction Mechanisms Depending on the application, you might also implement small smoothing or filtering modules before data enters the compressed model. For instance, applying a median filter on sensor readings or a denoising autoencoder to pre-process signals can help.
Pitfalls
Overfitting to artificially created noise patterns that may differ from real-world noise.
If the device can’t afford pre-processing overhead due to resource constraints, you might not be able to apply advanced filtering.
Highly pruned networks might lose certain critical features and handle novel noise poorly.
When deploying a compressed model for a mission-critical system, how do you handle potential failure modes and fallback strategies?
Fallback to Cloud Inference In mission-critical situations (e.g., medical devices or autonomous drones), you might have a fallback pipeline that sends data to a robust cloud model if confidence is too low on the local, compressed model’s output. This requires checking the device’s network availability and maintaining a threshold for the local model’s confidence score.
Ensemble Approaches In some safety-critical contexts, you can keep a very lightweight “sanity-check” model that catches obvious anomalies or potential misclassifications. If the compressed model’s outputs conflict with the sanity-check model, the system might raise an alert or request additional compute from a more capable system.
Selective Layers Another strategy is partial execution on the device and partial on the cloud. For example, initial feature extraction might be done locally, but final classification is done remotely. This approach is limited by connectivity but can reduce the risk of wholly relying on a heavily compressed model.
Pitfalls
Storing or transferring intermediate feature maps might be large or bandwidth-intensive.
If the device is offline or experiences high latency, the fallback is not always guaranteed to be timely.
Maintaining multiple fallback mechanisms can complicate software engineering and device updates.
How does per-channel quantization differ from per-tensor quantization, and why does this matter for edge deployment?
Per-Tensor vs. Per-Channel
Per-tensor quantization uses a single scale and zero-point for the entire weight tensor or activation tensor.
Per-channel quantization uses different scales and zero-points for each channel (or filter) in a layer.
Accuracy vs. Complexity Trade-off Per-channel quantization typically provides better accuracy because each channel might have a different dynamic range. Compressing them all with one scale can cause some channels to lose finer distinctions. However, per-channel quantization can be more computationally or memory-intensive because the hardware or runtime must manage multiple scales and zero-points.
Hardware Implications Some edge hardware accelerators support per-tensor quantization more readily because it is simpler to implement. If your device cannot handle per-channel quantization efficiently, you might see minimal speedups or possibly no support at all. Conversely, if the accelerator does handle it, per-channel quantization may yield higher accuracy for the same bit width.
Pitfalls
If your edge device’s quantization engine only supports per-tensor quantization, you cannot easily leverage the accuracy benefits of per-channel quantization.
Migration from per-tensor to per-channel quantization might require a different calibration process and might break backward compatibility with older firmware.
What challenges arise if you attempt to prune recurrent or self-attention architectures compared to standard CNNs?
Recurrent Layers
LSTM or GRU networks have internal gating mechanisms that can be very sensitive to small weight changes. Naively pruning gates can cause significant accuracy degradation or even training instability upon fine-tuning.
Unstructured pruning might lead to random gating behavior that severely impacts the sequence modeling capability.
Attention Mechanisms
Transformers rely on multi-head attention, so pruning entire heads is a form of structured pruning that can reduce computation. However, removing too many heads or entire attention layers can break the model’s ability to capture certain contextual relationships.
If you prune tokens or hidden states, you risk discarding relevant context.
Sparsity Patterns
Many frameworks are optimized for 2D convolution-based pruning. But for recurrent or attention-based structures, the data flow is less amenable to standard sparse kernel optimizations. This can reduce the real-world speed benefits from pruning.
Pitfalls
Overly aggressive pruning of heads or gates can degrade interpretability (e.g., attention weights are used to visualize context).
Fine-tuning may require more epochs or specialized learning-rate schedules for stable convergence in recurrent/attention networks.
How does knowledge distillation help in edge scenarios beyond just reducing model size?
Improved Generalization By matching the teacher’s logits, the student can learn nuanced decision boundaries, which can lead to better generalization on real-world data compared to training the same small architecture from scratch.
Domain Adaptation If the teacher model was trained on a large, diverse dataset, it can provide “soft labels” that capture domain invariances or subtle category boundaries. The student inherits these, making it robust for edge scenarios that might have data variations not extensively covered by a smaller training set.
Enable Multi-Task or Multi-Domain Knowledge A powerful teacher might handle multiple tasks (e.g., classification + detection). You can distill only the relevant aspects for the student’s single-task function on the device. This leads to a more targeted, efficient model, but which still captures some multi-task insights from the teacher.
Pitfalls
If the teacher’s domain does not match the edge device’s operational domain, the distilled knowledge may not translate well.
Distillation can be time-consuming if the teacher is huge, especially if you need to generate teacher outputs for a large unlabeled dataset.
How can we detect if a compressed model has drifted in performance over time in an unsupervised setting?
Drift Detection Methods
Statistical Monitoring: Monitor activation or embedding distributions over time. If these distributions shift significantly from what was observed at deployment, it might indicate data drift.
Reconstruction Error: You could pair the compressed model with a lightweight autoencoder that reconstructs inputs. If reconstruction error trends upward, it might indicate that the data distribution is shifting.
Ensemble Comparison: Retain a smaller reference model (maybe a different architecture) and periodically compare its outputs with the compressed model. Significant divergence might signal a drift.
Pitfalls
Data drift might not always manifest in activation distributions if the input changes are subtle.
Interpreting monitoring signals can be difficult if you do not have ground-truth labels to confirm whether the model is truly underperforming.
Overly frequent or spurious alarms can cause unnecessary updates or reduced trust in the system.
What are practical considerations for on-device memory constraints when applying pruning and quantization?
Model Storage vs. Run-time Memory
Pruning and quantization reduce model storage size. However, run-time memory usage also includes intermediate feature maps. The shape and data type of these intermediate activations matter.
If the device uses float32 for activations, you still might have large memory usage even if the weights are quantized.
Layer-by-Layer Execution
Some on-device runtimes can unload intermediate outputs once they are no longer needed if the execution graph is carefully managed. This helps keep the memory footprint smaller.
Pruning can reduce weight memory but might not drastically reduce the memory of intermediate feature maps unless the pruning is structured at the filter/channel level.
Pitfalls
If quantizing weights to int8 but leaving activations at float32, you only get partial memory savings.
Overlapping memory usage for large feature maps can lead to out-of-memory errors despite heavy pruning.
Some frameworks do not fully support partial or dynamic memory clearing, which can limit memory savings.
How do you validate whether a smaller network architecture is truly more efficient for a given edge device than a compressed large model?
Profiling on Actual Hardware Benchmark the final model on the real device. Compare FLOPs, inference time, and peak memory usage. You may find that a well-designed small architecture outperforms a pruned/quantized large model in terms of real latency.
The Complexity of Hardware Acceleration If the device has specialized support for certain kernels (e.g., int8 convolution in a large model), it might ironically run faster than a custom smaller architecture that has unusual layer shapes or operations not optimized by the hardware.
Accuracy-Efficiency Trade-off Compare not just speed but the difference in accuracy. A compressed large model might retain slightly higher accuracy at a given latency than a purely smaller architecture. Ultimately, choose the approach that meets your threshold for both performance and accuracy requirements.
Pitfalls
Relying solely on theoretical FLOPs or parameter count does not always translate to real inference speed.
Some specialized operations (like depthwise separable convolutions) might not be well-optimized on certain older hardware.
A smaller architecture might converge more slowly or require new hyperparameter tuning from scratch, delaying deployment timelines.
When compressing a model for edge deployment, how do licensing or IP concerns come into play?
Pre-trained Models with Restricted Licenses Many state-of-the-art models are released under licenses that restrict commercial usage or derivative works. Compressing or modifying them might be subject to these same license terms.
Proprietary Compression Techniques Some compression methods are patented or have licensing conditions (especially in hardware-specific contexts). If your edge device solution uses a proprietary approach, you might face additional costs or restrictions.
Model Export and Distribution If you are distributing the compressed model as part of a software library to multiple devices, ensure that you comply with any open-source license obligations (for instance, distributing source code modifications if required by certain licenses).
Pitfalls
Ignoring these can result in legal liabilities, especially if you’re using third-party pretrained models.
Overlooking license clauses that disallow commercial usage can lead to non-compliance if your app is monetized.
Patent issues can arise if your compression approach uses patented methods without permission.
How does compression interact with interpretability frameworks, such as Grad-CAM or feature attribution methods?
Different Activation Patterns Pruned or quantized models may exhibit different internal feature maps, which can lead to different saliency or attribution results compared to the original full-precision model. This could affect how you explain decisions to stakeholders.
Loss of Granularity Quantized models have discrete steps in weights and activations. Grad-CAM or other gradient-based methods might show less fine-grained highlight regions, making them more “blocky” or less precise.
Potential Solutions One approach is to maintain an uncompressed teacher or reference model purely for interpretability. Another is to retrain or calibrate interpretability methods specifically for the compressed model.
Pitfalls
If you rely on interpretability for compliance or user trust, the mismatch between the original and compressed model’s explanation might cause confusion or reduce confidence.
Some interpretability libraries may not yet have robust support for quantized or pruned architectures, leading to incorrect or incomplete attributions.
How does multi-modal or multi-task compression differ from single-task compression?
Shared Representations In multi-modal or multi-task settings, some layers or encoders might be shared across different data modalities or tasks. Pruning or quantizing those shared layers could have a more pronounced effect, since you’re impacting multiple tasks at once.
Task Imbalance One task might be more sensitive to compression than others. For example, a classification task might remain relatively stable after pruning, but an object localization task might degrade dramatically.
Selective Compression You might selectively compress certain parts of the model that are less critical to performance on any particular task. For instance, heavily compressing fully connected layers that feed into multiple classification heads but leaving the shared feature extractor less compressed.
Pitfalls
Over-compressing shared layers can degrade all tasks, forcing a bigger overall accuracy compromise.
Task weighting during knowledge distillation or fine-tuning might need special balancing to avoid “forgetting” one task.
How do batch size and throughput requirements affect the choice of compression?
Batch Size Trade-offs On edge devices, batch size is often 1 due to real-time constraints. If your compression technique relies on batched operations for speed-ups (for instance, certain types of matrix multiplication optimizations), you might not see large performance gains at batch size 1.
Throughput vs. Latency If you have to process streams of data quickly (high throughput), structured pruning or quantization can help reduce the per-sample cost. But if you only need to respond to infrequent events, it might be acceptable to use a moderately sized model that yields better accuracy.
Pitfalls
Some quantized kernels are optimized for bigger batch sizes. If your application is strictly single-sample inference, the realized speed-up might be smaller.
When the device is parallelizing tasks, limited memory might still become a bottleneck even if the model is smaller.
What approaches ensure security and integrity of a compressed model on a potentially compromised edge device?
Encryption and Secure Boot You can encrypt the model weights and only decrypt them on-device in secure memory. A secure bootloader can ensure that the firmware (and thus the runtime environment) is not tampered with before loading the model.
Model Fingerprinting To verify that the correct (unmodified) compressed model is running, you can store a hash or fingerprint in a secure enclave on the device. At runtime, the system checks if the model’s hash matches the expected value.
Runtime Attestation Some hardware platforms provide attestation features that let you validate that your code (including compressed model code) is unaltered. This can be critical in IoT deployments where physical device compromise is possible.
Pitfalls
Additional cryptographic computations can add overhead, which might be significant on a low-power device.
If the device is fully compromised with root access, these protections may still be bypassed.
Secure enclaves often have limited memory, which can be challenging for larger models—even after compression.
How do you systematically compare the “degree” of compression vs. the resulting accuracy in order to find the optimal balance for an edge deployment?
Compression-Accuracy Pareto Curve You can plot model size (or FLOPs, or latency) against accuracy to generate a Pareto curve. Each point on the curve corresponds to a different compression ratio or technique combination. The goal is to pick a point where the drop in accuracy is acceptable given the memory and latency gains.
Iterative Grid Search In practice, you might do a grid search over different pruning thresholds, quantization bit-widths, or knowledge distillation settings. Each set is measured for accuracy, size, and latency on target hardware. This might be time-consuming but offers a systematic approach.
Automated Tools There are auto-ML or hyperparameter search frameworks that can be adapted to compression hyperparameters. They attempt to maximize a composite objective (accuracy, memory, and speed). The search, however, can become expensive in large design spaces.
Pitfalls
You might face diminishing returns: going from 90% compression to 95% compression can cause a large accuracy drop.
Overfitting to your validation set during repeated compression hyperparameter tuning.
Real hardware measurements can differ from your development environment or theoretical estimates, so you must test thoroughly.