
ML Interview Q Series: Efficient Hyperparameter Search: Comparing Grid, Random, Bayesian Optimization & Automated Tools.

📚 Browse the full ML Interview series here.
Hyperparameter Tuning: Your model’s performance is highly sensitive to certain hyperparameters (learning rate, max depth of a tree, number of clusters, etc.). How would you efficiently search for a good combination of hyperparameters? Compare methods like grid search vs. random search, and describe more advanced techniques such as Bayesian optimization or using libraries (Hyperopt, Optuna, etc.) to find hyperparameters. Mention considerations like computational budget and avoiding overfitting to the validation set during this process.
Efficient hyperparameter tuning involves systematically or adaptively searching the configuration space (e.g., learning rates, number of layers, max tree depth, or clustering parameters) to find a high-performance set of values under a given computational budget. There are multiple strategies to accomplish this, each with distinct strengths and weaknesses in terms of speed, coverage, and the risk of overfitting to the validation set.
Hyperparameter tuning techniques
Basic Search Strategies
Grid Search
A classical approach that enumerates all possible combinations over a predefined set of discrete hyperparameter values. While conceptually straightforward, it can be highly inefficient because we often spend large amounts of compute on unpromising regions. This method is feasible when the hyperparameter space is small (like a few integer parameters), or when there are strong prior assumptions about the best hyperparameter values. However, with many hyperparameters or large ranges, it quickly becomes intractable.
Random Search
Instead of exhaustively enumerating points over a grid, random search samples each hyperparameter from a given distribution (e.g., uniform, log-uniform) independently. In practice, random search is surprisingly effective because it covers the space more flexibly, often locating promising regions more quickly than grid search. It is also easier to implement and extend. One potential drawback is that it remains a blind search; it does not leverage knowledge from prior samples to choose the next points.
Advanced Search Strategies
Bayesian Optimization
Bayesian Optimization uses past observations to probabilistically model the performance function, aiming to “guess” the most promising new hyperparameter configuration to test. Instead of sampling blindly, it fits a surrogate model (commonly a Gaussian Process or a Tree-structured Parzen Estimator) to map from hyperparameters to performance metrics, then applies an acquisition function to determine the most informative point to sample next.
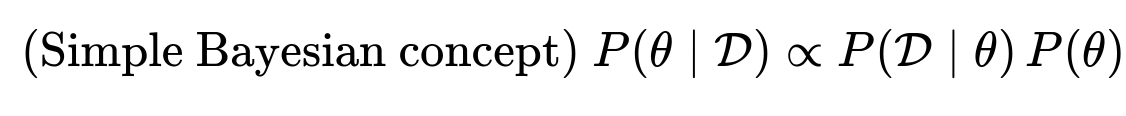
In practice, the algorithm keeps updating the posterior over the objective function based on observed performance. It is particularly useful when evaluations are expensive, since it tries to minimize the number of trials. For high-dimensional problems, more sophisticated surrogate models like random forest regressors or gradient boosted trees can be used.
Libraries such as Hyperopt and Optuna
These frameworks provide:
• Automated hyperparameter search (both random and Bayesian). • Flexible ways to define search spaces (e.g., discrete, continuous, conditional). • Parallelization capabilities. • Pruning methods (e.g., early stopping) to discard underperforming trials and save time.
In Python, a typical example of using Optuna might look like:
import optuna
import sklearn.datasets
import sklearn.ensemble
from sklearn.model_selection import cross_val_score
def objective(trial):
# Suggest hyperparameters
n_estimators = trial.suggest_int("n_estimators", 50, 300)
max_depth = trial.suggest_int("max_depth", 2, 20)
learning_rate = trial.suggest_loguniform("learning_rate", 1e-4, 1e-1)
# Define model
model = sklearn.ensemble.GradientBoostingClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
learning_rate=learning_rate
)
# Load data
data = sklearn.datasets.load_breast_cancer()
X, y = data.data, data.target
# Evaluate with cross-validation
score = cross_val_score(model, X, y, n_jobs=-1, cv=3).mean()
return score
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=50)
print("Best hyperparameters:", study.best_params)
print("Best CV score:", study.best_value)
This code snippet shows how to set up a search space and let Optuna adaptively pick hyperparameters. The “suggest_” methods define how to explore the space (integer, log-uniform, etc.). The library updates its model of the objective function based on prior evaluations, selecting new points to sample.
Considerations for Efficient Tuning
Computational Budget
Hyperparameter searches can be computationally expensive, especially with large datasets or models (e.g., deep neural networks). Budget management includes:
• Pruning or Early Stopping: Halting poor-performing trials early to avoid wasting resources. • Parallelization: Searching multiple configurations at once if hardware allows (multiple GPUs or distributed compute). • Approximation Methods: Using smaller models or subsets of data to quickly evaluate many configurations, then refining on full data once promising regions are found.
Avoiding Overfitting to the Validation Set
Repeatedly testing hyperparameters on a single validation set can inadvertently bias the model towards those validation examples. Best practices to mitigate this risk:
• Nested Cross-Validation: An outer loop splits the data into train/test folds, while an inner loop performs hyperparameter tuning. • Use Multiple Validation Splits or Cross-Validation: Instead of a single train-validation partition, average performance across folds to reduce variance in the estimate of your tuning objective. • Keep a Final Hold-Out Test Set: Evaluate only once at the end to measure true generalization.
Leveraging Cross-Validation
Cross-validation is especially useful when data is limited or performance metrics are noisy. It reduces the variance of performance estimates, thereby reducing the risk of picking suboptimal hyperparameters due to random fluctuations in a single split.
Follow-up Questions Appear Below
How do these methods scale to high-dimensional hyperparameter spaces, such as tuning many dozens of parameters?
When dealing with extremely high-dimensional spaces, grid search becomes nearly impossible because each additional parameter dimension exponentially increases the number of combinations. Random search can handle higher dimensions better than grid search, but it still does not adaptively focus on promising areas. Bayesian methods can also struggle if the dimensionality becomes too large, because the surrogate model becomes more challenging to train and the optimization can get stuck in local minima or waste many function evaluations.
Practical techniques include:
Using domain knowledge to narrow down which parameters truly matter the most. Many real systems have only a few critical hyperparameters, while others have minor effects. Adopting specialized high-dimensional optimization algorithms (e.g., using random embeddings, dimensionality reduction, or specialized Bayesian Optimization approaches that can handle large dimensional spaces). Applying hierarchical or conditional parameter search. For instance, if a certain parameter is only relevant if another parameter is active, that structure can be encoded in the search space.
How can we efficiently tune deep neural network hyperparameters when training is very expensive?
Deep neural networks can take hours to days to train. Consequently, searching across hundreds or thousands of trials becomes expensive. Approaches to mitigate these costs include:
Early Stopping or Pruning: Monitor intermediate metrics (like validation loss after a few epochs) and terminate underperforming trials early. Optuna’s median pruning strategy or Hyperopt’s early stopping heuristics are examples. Successive Halving or Hyperband: These scheduling algorithms iteratively allocate resources to top-performing configurations and prune the rest, maximizing the number of explored configurations while controlling total computations. Multi-fidelity Approaches: Start with smaller model sizes or subsets of data to screen out less promising hyperparameter settings, then scale up to larger configurations for more fine-grained search on top contenders.
Why might Bayesian Optimization be more suitable than random search if we have a strict time or computational budget?
Bayesian Optimization tries to use knowledge from previously evaluated points to model where the objective function is likely to be high or low. Consequently, it guides the search towards promising regions in a more informed way than random sampling. This can help converge to a good hyperparameter region using fewer total evaluations, which is especially valuable if each evaluation (model training) is very time-consuming or costly.
However, modeling overhead grows with the number of parameters and total trials. For extremely high dimensions or massive search spaces, the surrogate model may become complex to fit, so a hybrid or specialized approach might be used.
How do libraries like Hyperopt and Optuna handle conditional hyperparameters?
Frameworks like Hyperopt and Optuna typically allow you to define conditional logic in the search space. For example, you might say:
• If optimizer == 'Adam', then suggest a separate parameter range for learning_rate. • If a certain regularization method is turned on, then suggest a range of penalty strengths.
This ensures that invalid or non-applicable parameter combinations are skipped. It also provides a more faithful representation of how those hyperparameters truly interact in practice.
In a real-world scenario, how do we prevent ourselves from “tuning to the test set”?
It is crucial to keep a dedicated final test set that is never used for tuning decisions. One approach is:
Split the available data into training and final test subsets. Use cross-validation (or a separate validation subset) inside the training portion for hyperparameter tuning. Once the best hyperparameters are selected, train a final model on the entire training portion using these hyperparameters, and evaluate only once on the test set.
This way, the test set remains unbiased by any hyperparameter or modeling choices.
Is there a risk that repeated tuning cycles can overfit the model to the validation set, even when using cross-validation?
Yes, if you iteratively fine-tune hyperparameters and constantly refer to the same cross-validation metrics, you might effectively “peek” at these metrics too many times. To mitigate:
Use multiple runs of cross-validation to confirm stability. Adopt nested cross-validation, where the outer fold is only used to evaluate the final chosen hyperparameters, and never influences their selection. Perform “warm restarts” carefully. For example, if you do an initial search, gather a set of good hyperparameters, and refine further, be aware that repeated usage of the same validation scheme can bias outcomes.
How can we handle hyperparameters that are integer-valued, categorical, or continuous in these frameworks?
Most hyperparameter optimization frameworks let you define each parameter’s domain:
• Integer: Typical for parameters like number of units, tree depth, or number of estimators. • Categorical: For choosing among discrete options like optimizer type, activation function, or kernel type. • Continuous: For parameters like learning rate, regularization strength, or momentum factor.
Random search and Bayesian-based approaches can handle all these parameter types by sampling or modeling each parameter’s search space appropriately (e.g., uniform sampling, log-uniform sampling, or specialized sampling for categorical choices).
What if we only have a small dataset? Would we still do large hyperparameter sweeps?
When data is limited, large-scale sweeps can lead to overfitting or produce unstable estimates of performance. Common solutions:
More reliance on cross-validation to ensure robust estimates. Simplify the model or reduce hyperparameter ranges. Use domain knowledge to pick narrower prior ranges for Bayesian search, so we limit the search space to plausible intervals.
Are there scenarios where grid search might be preferable despite its drawbacks?
Grid search can be preferable when:
The hyperparameter space is very small or only a couple of parameters matter. We require interpretability in how performance changes with respect to each parameter, because grid search can produce a structured performance table or heatmap. We have strong prior knowledge of the best discrete points to test (e.g., we only want to try learning rates {0.001, 0.01, 0.1} and max_depth {5, 10}, etc.).
It is much less practical when scaling beyond a few parameters due to the combinatorial explosion in trial count.
Can you illustrate an example of early stopping or pruning in code?
Below is an example using Optuna’s pruning mechanism:
import optuna
import sklearn.datasets
import sklearn.linear_model
from sklearn.model_selection import train_test_split
def objective(trial):
data = sklearn.datasets.load_diabetes()
X_train, X_valid, y_train, y_valid = train_test_split(data.data, data.target, test_size=0.2)
alpha = trial.suggest_float("alpha", 1e-3, 1e2, log=True)
model = sklearn.linear_model.SGDRegressor(alpha=alpha, max_iter=1000, random_state=0)
partial_n_epochs = 10
for step in range(partial_n_epochs):
model.partial_fit(X_train, y_train)
y_pred = model.predict(X_valid)
loss = ((y_pred - y_valid) ** 2).mean() # MSE
trial.report(loss, step)
if trial.should_prune():
raise optuna.TrialPruned()
return loss
study = optuna.create_study(direction="minimize")
study.optimize(objective, n_trials=50)
print("Best parameters:", study.best_params)
print("Best value:", study.best_value)
Here, after each partial training step, we measure validation loss and report it to Optuna. If the loss is not improving sufficiently compared to other trials, Optuna will prune (stop) the trial early, saving computational resources.
How do real production environments manage large-scale hyperparameter tuning?
In large-scale production settings at major tech companies, hyperparameter tuning often happens in distributed clusters (Kubernetes, Spark, HPC). Techniques include:
• Distributed job scheduling: Many hyperparameter jobs run in parallel. • Automated resource management: Trials are dynamically scheduled. • Shared logs and dashboards: Observability in real-time to see intermediate metrics and prune trials or adapt the search. • Checkpointing: For expensive deep learning models, partial training results are saved so that trials can be resumed or examined for potential restarts.
This entire pipeline is often orchestrated through internal systems or open-source frameworks integrated with the cloud environment.
How can we ensure fairness and reproducibility when tuning hyperparameters?
To maintain fairness and replicability:
• Fix the random seeds and ensure the same software/library versions. • Document the exact hyperparameter ranges, search methods, and number of trials. • Use consistent data splits or random seeds for cross-validation across different runs. • Keep a record of each trial’s hyperparameters, validation scores, and any early stopping events.
This ensures that tuning results can be audited, repeated, and compared. When results are published or shared, providing these details helps others trust the reported performance.
Below are additional follow-up questions
When we have multi-objective requirements (e.g., accuracy and latency), how can we incorporate this into hyperparameter tuning?
Multi-objective hyperparameter tuning often aims to strike a balance between competing objectives, such as maximizing accuracy while minimizing inference time or memory consumption. A standard approach is to define multiple metrics and apply one of the following strategies:
• Weighted Objective: Combine the metrics into a single scalar objective using weights that reflect their relative importance. For instance, you might define an overall score as

where a higher score means better accuracy and lower latency. The tradeoff factor
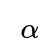
is chosen based on product constraints.
• Pareto Optimization: Search for a set of “Pareto optimal” solutions, each representing a different tradeoff between objectives. Bayesian optimization libraries sometimes include specialized acquisition functions (like Expected Hypervolume Improvement) for multi-objective settings. The result is a Pareto frontier, from which stakeholders can pick the preferred tradeoff.
• Practical Considerations:
If latency is non-negotiable (e.g., real-time constraints), treat it as a hard constraint. Filter out trials that exceed a threshold and optimize accuracy among the remaining feasible region.
Evaluate stability across multiple runs because multi-objective performance can vary significantly with data splits or random seeds.
Pitfall: In real-world settings, maximizing one objective (like accuracy) can inadvertently degrade another (like memory). A purely single-objective approach may produce un-deployable models. Explicit multi-objective methods address this problem.
How do we effectively inject prior domain knowledge into a Bayesian approach to hyperparameter tuning?
In Bayesian optimization, you can define prior distributions for your hyperparameters that reflect domain knowledge. This helps the algorithm start in a region more likely to contain good solutions. Possible methods:
• Initial Distribution Choice: If you know the typical range of acceptable learning rates for your domain, choose a narrower log-uniform distribution to focus the search. • Warm-Start Trials: Provide initial evaluations from known successful hyperparameter sets. This is called “warm starting” the optimizer. The surrogate model begins with some data points already mapping hyperparameters to performance. • Custom Surrogate Model: Instead of a basic Gaussian Process, you might use a specialized model that encodes domain-specific correlations. For instance, you might have a hierarchical structure that places similar hyperparameters in correlated groups (e.g., different forms of regularization being correlated).
Edge Case: Overly confident priors can cause the search algorithm to ignore other potentially better areas. Always balance prior knowledge with enough exploration so the optimization can escape suboptimal priors.
If the objective function itself is noisy or changes over time (e.g., in streaming data scenarios), how do we adapt the hyperparameter tuning process?
In streaming data or non-stationary settings, the optimal hyperparameters may shift over time. To address this:
• Periodic Re-Tuning: Perform hyperparameter search on newly available data at fixed intervals. This ensures the model adjusts to evolving distributions. • Online Bayesian Optimization: Adapt the surrogate model with a forgetting mechanism (where older data points have reduced weight) so that the optimizer focuses more on recent performance. • Rolling/Horizon Evaluation: Keep a rolling validation window to measure performance on the most recent data. • Resource Constraints: If data arrives continuously, re-tuning frequently might be computationally prohibitive. You might adopt simpler, faster strategies or rely on partial data sampling.
Pitfall: Overfitting to the latest chunk of data can degrade performance on the overall distribution. Always verify that the chosen approach balances responsiveness to changes with stability.
In extremely large datasets, cross-validation can be too costly. Can we still perform robust hyperparameter tuning without full cross-validation?
Yes, but you must be mindful of variance in performance estimates. Options include:
• Single Validation Split with Enough Data: Sometimes a single (or a couple of) train/validation split(s) is sufficient if each split is large enough that the estimate is stable. • Subsampling: Evaluate each hyperparameter setting on a subset of the dataset. Then, refine promising settings on the entire dataset. This two-stage approach helps screen out poor settings early. • Incremental Cross-Validation: Evaluate partial folds or fewer folds to reduce computational overhead. • Stratified or Balanced Splitting: If the data is highly imbalanced or has critical subpopulations, carefully sample your validation set to ensure it represents the distribution well.
Edge Case: If the single validation set is not representative, you might get suboptimal hyperparameters. Monitoring performance over time or rotating the validation set can mitigate this.
What if we have tight memory constraints that limit the size of certain models or certain hyperparameter configurations?
Memory constraints can invalidate some parameter ranges (e.g., very large batch sizes, extremely deep neural networks). To handle this:
• Define Feasibility Bounds: Exclude hyperparameter configurations that violate memory requirements (e.g., batch_size > 512 if the GPU can’t handle it). • Monitor Memory Usage in Real Time: When a trial runs, track GPU/CPU memory usage. If it exceeds a threshold, prune or halt that trial. • Use Smaller Data Subsets: If the entire dataset doesn’t fit in memory, consider iterative or streaming training methods, which also reduce memory usage. • Domain Knowledge: You might already know that extremely large hidden layer sizes are infeasible. This information can shape your search space or your prior distributions.
Pitfall: A naive search method might crash your process or job scheduler if memory usage is not checked. Automated pruning or validation of memory usage is crucial for stable experimentation.
What scenarios motivate meta-learning for hyperparameter tuning, and how does it differ from standard search?
Meta-learning (also known as “learning to learn”) uses knowledge gained from prior tasks or datasets to speed up hyperparameter search on new tasks. Instead of starting from scratch each time, the system can reuse patterns discovered in previous optimizations. Differences from standard search:
• Transfer of Hyperparameter Priors: Instead of random or uniform initial guesses, meta-learning might automatically propose hyperparameters that worked well for tasks with similar data characteristics. • Reduced Search Time: Because the system “remembers” good configurations from similar tasks, it can converge faster on the new task. • Complexity: Setting up a meta-learning pipeline is non-trivial. It typically requires a repository of tasks/datasets, each with logs of hyperparameter configurations and model performances.
Edge Case: If the new task is too dissimilar from the training tasks, the meta-learning strategy may be misleading. Always validate that tasks share relevant similarities (data distribution, model structure, etc.).
How do iteration-based search strategies refine their hyperparameter ranges?
Iteration-based or adaptive range refinement techniques look at results from an initial search (random or otherwise) to focus subsequent searches:
• Successive Interval Halving: After evaluating an initial uniform sample, the top-performing region is identified, and the next iteration focuses on a narrower range around that region. • Zooming: The search algorithm “zooms in” on a promising region of a parameter, discarding out-of-range or clearly underperforming values. • Practical Implementation: Some frameworks allow dynamic updates of search bounds. For example, after a first round with a large learning rate range, you might discover that high learning rates yield poor results, so you shrink the upper bound.
Pitfall: Overly aggressive narrowing might exclude truly optimal regions if the initial sampling was unlucky or if the model has complex behaviors (e.g., multiple peaks in the objective).
What additional nuances arise when tuning hyperparameters for unsupervised or semi-supervised tasks?
In unsupervised settings, you often rely on proxy metrics (like silhouette score for clustering or perplexity for language modeling). These metrics can be more ambiguous or less correlated with real downstream objectives. Likewise, for semi-supervised tasks, you might have partial labels:
• Metric Definition: Ensure your metric aligns well with the end goal. For clustering, is the internal metric (e.g., silhouette score) consistent with actual business or domain usage? • Stability Checks: Unsupervised methods can be sensitive to initialization. Evaluating multiple runs with different seeds can be crucial for stable performance estimation. • Semi-Supervised Edge Case: If the labeled portion is tiny, performance metrics might be noisy. Techniques like cross-validation become trickier to implement.
Pitfall: In unsupervised tasks, data transformations or feature engineering steps might drastically change performance. Hyperparameter search must also encompass these data transformation parameters for a thorough exploration.
Could tuning hyperparameters in an online or incremental learning scenario introduce data leakage or bias?
Yes. In online or incremental learning, new data arrives sequentially, and the model updates over time. Potential issues:
• Peeking: If you repeatedly evaluate on the incoming data to adjust hyperparameters on the fly, you risk overfitting to recent samples. • Drift Misalignment: Data drift might invalidate hyperparameters that worked previously. Continual tuning must carefully separate training and evaluation to avoid data leakage from future samples. • Rolling Window Validation: Typically, you’d define a rolling window for validation that mimics future data distribution, but do not repeatedly reuse that window once you adjust hyperparameters.
Edge Case: If you tune hyperparameters in real-time while data distribution drastically changes (e.g., concept drift), the system might chase ephemeral patterns. Designing robust, stable tuning intervals is critical.
Do hardware-specific hyperparameters (like GPU block sizes or multi-threading strategies) matter for hyperparameter tuning?
They can. While often overlooked, hardware configuration can significantly influence training speed and sometimes even final performance:
• GPU Utilization: Parameter choices such as the batch size may strongly interact with memory usage and GPU scheduling. • Parallelization Overhead: Some hyperparameters might hamper scaling across multiple GPUs if the model’s structure or the parallel processing overhead grows too large. • Mixed Precision vs. Full Precision: In deep learning, toggling between float16 and float32 can significantly change training speed and memory usage, sometimes requiring hyperparameter re-tuning (e.g., learning rate adjustments).
Pitfall: Blindly ignoring hardware hyperparameters can lead to suboptimal performance or out-of-memory errors. Tuning them manually might be necessary, but it requires careful instrumentation to measure their impacts.
When we have multiple objectives and want a set of solutions, how do we incorporate that into the optimization framework?
This is a multi-objective approach where the result is not a single “best” configuration, but a set of Pareto-optimal configurations:
• Multi-Objective Bayesian Optimization: Uses specialized acquisition functions (e.g., Expected Hypervolume Improvement) that select new points aiming to expand the Pareto frontier. • Weighted Summation with Varying Weights: You can run repeated single-objective searches with different weighted combinations of the objectives. Each run yields a different tradeoff. • Post-Processing of Solutions: Another approach is to gather all solutions from a standard single-objective search that logged the other metrics. Then, filter or rank them offline to identify Pareto front solutions.
Edge Case: Real deployments might require picking one final solution, so the multi-objective search yields a set of candidates, and domain experts or product constraints choose the solution with the best tradeoff.
What considerations arise for hyperparameters that drastically alter the model structure (e.g., changing the number of layers or the architecture entirely)?
Drastic architecture changes can cause training logic or memory demands to vary widely:
• Feasibility Checks: A 100-layer network might not fit on the available GPU if the batch size is also large. This must be validated before or during the trial. • Conditional Hyperparameters: If the user chooses a wide architecture, then other hyperparameters like dropout rates or certain layer-specific settings become relevant. Tuning frameworks must handle these conditionals. • Training Instability: Very deep networks or significantly altered architectures might fail to converge unless other hyperparameters (learning rate, weight initialization) are adjusted.
Pitfall: If the search method tries a drastically larger architecture, it might crash or run extremely slowly, stalling overall hyperparameter tuning. Setting resource or time limits per trial is essential.
Can we leverage knowledge from previously solved tasks or other datasets (transfer learning) to guide hyperparameter choices?
Yes. Transfer of hyperparameter knowledge across tasks is often beneficial, particularly in similar domains:
• Warm-Start with Known Good Settings: For example, if a certain learning rate or layer configuration worked on a similar dataset, start the search near those settings. • Meta-Learned Priors: If you systematically store the results of prior tuning runs on many tasks, you can train a meta-learner that predicts good hyperparameter choices for a new task (i.e., meta-learning). • Monitoring Domain Mismatch: If the new task is only loosely related, previous best hyperparameters might not help and can even mislead the optimization. Always confirm that the tasks are aligned in complexity, distribution, or model architecture.
Pitfall: Over-reliance on knowledge from dissimilar tasks may skip the truly optimal region. Always incorporate some element of exploration.
What are the main differences between black-box optimization methods vs. specialized gradient-based approaches for hyperparameter tuning?
• Black-Box Optimization: Methods like random search, Bayesian optimization, Hyperband, etc., do not assume the objective function has a known gradient with respect to hyperparameters. Each hyperparameter configuration is tested by fully training and evaluating the model. • Gradient-Based Hyperparameter Optimization: Approaches like differentiable hyperparameter optimization compute gradients of the validation loss with respect to hyperparameters (often via complex techniques like hypernetworks or implicit differentiation). In some frameworks, the entire training loop is made differentiable. • Advantages of Gradient-Based: Potentially faster convergence if the gradient is accurately computed. • Drawbacks: More complicated to implement, can be computationally heavy, and might require specialized architectures or training loops that are fully differentiable.
Pitfall: Gradient-based approaches can fail if the hyperparameter landscape is highly non-smooth or discontinuous (e.g., integer hyperparameters, conditional logic). Black-box methods remain more general and widely applicable.
How do we measure the stability or robustness of chosen hyperparameters under domain shifts or different data distributions?
To test robustness of hyperparameters:
• Out-of-Distribution Testing: Evaluate the final model on data that slightly differ from the training distribution (e.g., different time period, region, or user demographic). • Cross-Domain Validation: If you have multiple datasets from similar but not identical domains, train on one and validate on another. If the model still performs well, your hyperparameters might be robust. • Sensitivity Analysis: Perturb training or validation data slightly and see if the chosen hyperparameters still produce strong performance. If small shifts drastically degrade performance, the hyperparameters might be overfitted to the original distribution.
Pitfall: Even if the hyperparameter search was thorough, it could lock onto distribution-specific signals that do not generalize. Continuous monitoring and potential re-tuning become necessary in dynamic production environments.