
ML Interview Q Series: Expected Coin Flips for Two Consecutive Heads: A Markov Chain Approach.

Browse all the Probability Interview Questions here.
14. What is the expected number of coin flips needed to get two consecutive heads?
This problem was asked by Lyft.
To explore the expected number of flips required to observe two consecutive heads (HH) for a fair coin, we can approach the problem using the concept of Markov chains (or states) to track our progress. The main idea is to define states based on how many consecutive heads have been seen so far and then set up equations for the expected time to reach the goal state. We will also verify the result by an alternative reasoning and show a quick Python simulation for additional insight. Along the way, we will discuss potential follow-up questions that often appear in rigorous technical interviews.
In an interview setting, it is common to be asked to derive or explain this result in detail, so we will walk through the reasoning carefully and examine subtle points that might come up.
In this answer, the relevant mathematical expressions are placed between "$" if inline, or in their own centered lines with the format:
some expression
for clarity. We will keep the math expressions relatively minimal, only using them when they offer the clearest explanation of the concept.
In-Depth Explanation
We consider a fair coin with probability 0.5 of landing heads (H) and 0.5 of landing tails (T). We want to compute the expected number of flips until we first see two consecutive heads.
Defining States
We can define three key states to keep track of our progress:
• State S0: We have currently seen 0 consecutive heads. • State S1: We have currently seen 1 consecutive head. • State S2: We have seen 2 consecutive heads in a row (the target state).
Once we reach S2, we are done, so it is an absorbing state in Markov chain terminology. Let:

Transitions Between States
From S0:
• With probability 0.5, we flip a head (H) and move to S1. • With probability 0.5, we flip a tail (T) and remain in S0.
Hence the one-step transition from S0 can lead us to S1 or back to S0. We account for 1 flip each time, which adds 1 to the expectation.
Mathematically:







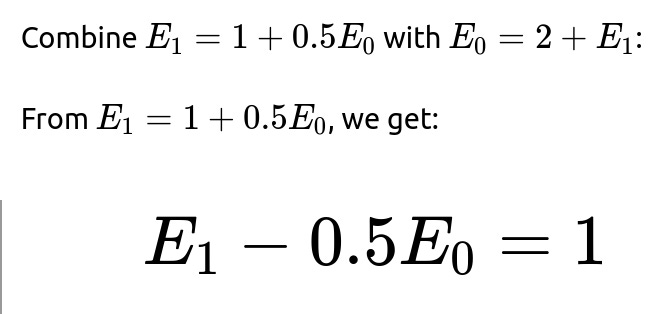







Verifying the Intuition
A fair number of interviewers will also ask for a direct or more intuitive argument. One approach might be enumerating the average length of “runs” of coin flips, but the Markov chain approach is the cleanest. Alternatively, a direct infinite-series method can be set up by considering the probability of achieving HH for the first time on flip 2, 3, 4, and so on, summing over all possibilities. However, the states approach is typically simpler and less error-prone.
Practical Simulation in Python
Below is a short Python code snippet that can empirically estimate the expected number of coin flips needed. It uses a simulation approach to confirm that the observed average number of flips is close to 6.
import random
import statistics
def flips_for_two_heads():
# Start in state S0
consecutive_heads = 0
flip_count = 0
while True:
flip_count += 1
flip = random.choice(['H', 'T'])
if flip == 'H':
consecutive_heads += 1
else:
consecutive_heads = 0
if consecutive_heads == 2:
return flip_count
# Run multiple trials
num_trials = 10_000_00 # 1 million trials
results = [flips_for_two_heads() for _ in range(num_trials)]
print(statistics.mean(results))
If you run this code, you will typically observe a value close to 6 (e.g., 5.99 - 6.01) as the average flip count. The empirical verification aligns nicely with the theoretical answer.
What if the coin is biased?
In many interviews, a common follow-up question is: “What changes if the coin is not fair? Let’s say the probability of heads is p and tails is 1−p.” You would then write slightly different equations for the transitions:
• From S0:
With probability p, move to S1.
With probability (1−p), remain in S0.
• From S1:
With probability p, move to S2 (done).
With probability (1−p), revert to S0.
Then you would solve analogous equations:
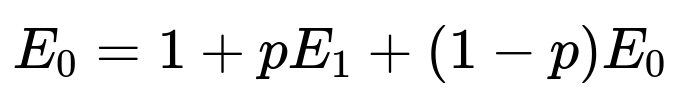
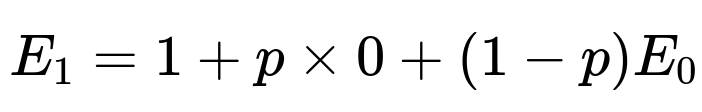

How can we generalize to k consecutive heads?

What if we use an alternative method (e.g., sum of probabilities)?
Sometimes, interviewers will ask you to show a direct summation approach. For instance, let X be the random variable denoting the first time we achieve HH. You can express: P(X=n)
as the probability that the first time HH appears is on the nth flip. This can be derived by enumerating all the patterns of heads and tails leading up to that point. You would then write:
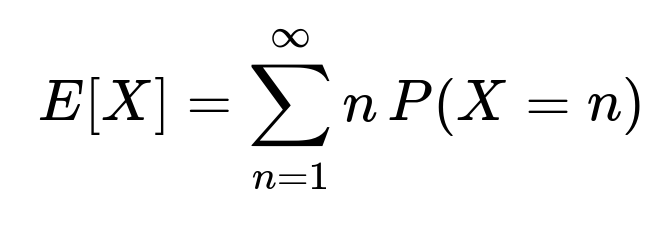
and carefully count the valid sequences. While this method can work, it often becomes algebraically involved. The Markov chain approach is usually cleaner and less prone to combinatorial mistakes.
Could we misinterpret states?
A subtle point in interviews is ensuring that if you are in state S1 (one head so far), and you get another head, you do not revert to S1 but instead succeed. Some candidates incorrectly handle the transition. Similarly, if you are in a scenario of looking for “HHT” or a more complicated pattern, you might have partial overlaps. But for two consecutive heads, it’s straightforward: from S1 plus a head, you’re done. From S1 plus a tail, you go back to S0.
Are there any off-by-one pitfalls?
Another subtlety is forgetting to add the +1 for each flip before transitioning to the next state in your equations. If you set up the equations but forget that each flip “costs” you 1 in your expectation, you can get a mistaken result. Being careful with the “one-step plus new expectation” is critical.
Could the Markov chain approach be extended to real-world scenarios?
Interviewers may probe how you’d handle a real or more complicated setting. For instance, if the coin is not memoryless (some dependency or external factor), you would have to define states that encapsulate enough history to capture that dependency. However, for a memoryless coin-flipping scenario, the Markov chain with three states is completely sufficient.
How might we confirm correctness in a production setting?
An interviewer might ask how to test or confirm that your code or analysis is correct. A good answer is to:
• Write a simulation, run it enough times to reduce variance, and compare with the theoretical calculation. • Validate simpler cases you can solve by hand (e.g., the expected number of flips to get a single head is obviously 2, so you can check that your code or approach generalizes properly).
Final Answer
From the Markov chain analysis, the expected number of coin flips needed to observe two consecutive heads with a fair coin is 6.
Below are additional follow-up questions
How would we approach the variance or the entire probability distribution for the number of flips?
When analyzing the expected number of flips, we focus on the first moment (the average). Interviewers may ask about the second moment or the full distribution of the stopping time. Specifically, they might say: “How do we determine the variance or the probability that it takes more than a certain number of flips?” This is not covered solely by the expectation and requires a deeper look at how likely certain event sequences are.
To tackle the full distribution, a common approach is to define a recurrence relation for the probability that the process ends on exactly the nth flip. For two consecutive heads, we can specify:
The probability that the first occurrence of HH is at flip n.
The detailed constraints on the preceding n–1 flips (they must not contain HH, and the last two flips at times n–1 and n are heads).
This approach often involves summing probabilities of all permissible sequences that avoid HH before flip n–1. You then combine those probabilities to build out the distribution:
P(X=2) is the probability that the first two flips are heads.
P(X=3) is the probability that the first occurrence of two consecutive heads is on the third flip (so the pattern up to flip 3 is THH, with no HH in the first two flips).
P(X=4) is more complicated because you must ensure no HH in the first three flips, then flip 4 is a head and flip 3 is a head.
And so on.
Once this distribution is derived, you can compute higher moments such as the variance. The key pitfall is ensuring correct enumeration of valid sequences before the final success. Mistakes can easily creep in when counting these sequences, so many find it safer to rely on Markov chain methods extended to track the probability distribution over states as a function of the number of flips.
An alternative is to solve for the probability generating function (or probability mass function) directly from the transition matrix for a Markov chain. By systematically analyzing transitions, you can obtain an expression for P(X=n) for each n. This yields a full distribution from which you can compute variance and any other moments.
Real-world edge cases: • If the coin is not fair, or if each flip might fail to produce a valid outcome (e.g., the coin sometimes lands on its edge), the probabilities shift and complicate distribution derivation. • If you only have a small sample (say you only flip 5 or 6 times in practice), then it’s quite possible you never see two consecutive heads at all, requiring you to model the event of “not happening by time n.”
How can partial observability or noisy observations affect the expected time?
In standard formulations, we assume you know with certainty each flip’s outcome (heads or tails). But there could be scenarios in which you sometimes misread or fail to record the exact flip result. For instance, if there is noise in how the coin is observed (like real-world sensors that might confuse heads with tails), the states become uncertain.
Handling partial observability typically requires a Hidden Markov Model (HMM) perspective. Instead of having states that are fully known (S0, S1, S2), you’d track the belief distribution over those states. For each flip:
You have a “true” observation that might be heads or tails.
You observe something that is correct only with a certain probability.
Then, you’d compute a belief state vector representing the probability that you are currently in S0 or S1 given the noisy observation history. From that belief state, you can update your probabilities after each flip. Eventually, once the belief that you are in S2 (two consecutive heads) surpasses some threshold, you might decide that it is “very likely” you have achieved two consecutive heads.
Potential pitfalls in real-world scenarios: • If you cannot reliably differentiate H from T, you might prematurely conclude that you have found two heads in a row. • The probability updates can become complex, especially if the probability of misclassification depends on prior states (non-independent errors).
How does the solution change if the coin can land on its edge?
In real physical coins or specialized coins in magic tricks, there can be a small but non-negligible chance that a coin lands on its edge. Let’s say:
• Probability of heads: p. • Probability of tails: q. • Probability of edge: r.
Here, p+q+r=1.
To adapt the standard Markov chain approach, you’d expand the transitions. If the coin lands on edge, you neither advance toward consecutive heads nor reset the count entirely; rather, you remain in the same “heads count” state. For instance:
From S0:
With probability p, you go to S1.
With probability q, you stay in S0 (since you got tails, so consecutive heads count is still 0).
With probability r, you remain in S0 as well (because an edge isn’t a head, so you are still at 0 consecutive heads).
From S1:
With probability p, you proceed to S2 (done).
With probability q, you revert to S0.
With probability r, you remain in S1 (you do not gain or lose consecutive heads when it lands on edge).

Pitfalls: • Forgetting that edge outcomes can keep you in the same state. • Not accounting for the fact that repeated edge landings will keep adding to the total flip count while not progressing the chain.
How might we handle flipping multiple coins at once?
Sometimes, problems extend to flipping multiple coins simultaneously per “step” (like flipping 3 coins at a time) and looking for at least one instance of two consecutive heads among the results. In that scenario, “time” is measured in how many sets of flips occur, not how many individual coin flips. This changes the Markov chain structure:
Each time step, you get multiple coin outcomes.
You can observe patterns such as HHH, HHT, THH, etc., across the coins.
You ask: “Do any consecutive pairs within that batch show heads?” or more complicated definitions, depending on the problem statement.
That might alter the probability space. For instance, if you flip three coins at once, the chance of seeing at least one instance of HH in positions (1,2) or (2,3) must be computed carefully. If you want two consecutive heads across time steps (e.g., last coin in the previous batch plus the first coin in the new batch?), you need to track partial overlap from the previous step. This can require a higher-dimensional state representation capturing the tail end of the last batch.
Potential pitfalls: • Overlooking the boundary between consecutive batches (e.g., if the last coin in batch 1 is H and the first coin in batch 2 is H, that might count as consecutive heads across the boundary). • Missing the combinatorial complexity of multiple flips each time step, which can significantly complicate transitions.
How could generating functions or advanced combinatorial tools provide an alternative derivation?
Sometimes, advanced interviewers or academic-style questions delve into generating functions. The idea is:

You can often write functional equations for G(z) based on the transition probabilities between states:
From S0, with some probability you go to S1, or remain in S0.
From S1, you either finish or revert to S0.
By enumerating how these transitions translate to powers of z in the generating function, you can solve for G(z) in closed form. Once you have G(z), you can extract E[X] by differentiating at z=1, and likewise find higher moments.
However, the challenge is that deriving G(z) by hand can be more algebraically intense. It’s elegant once done correctly but quite error-prone.
Real-world significance is limited (most practical engineering tasks do not require generating function manipulations for coin-flip problems), but some advanced mathematics or algorithmic roles might expect you to know how to do it or at least recognize that it’s possible.
How does the problem extend to partial matches of a longer sequence, such as consecutive patterns beyond heads?
Another intriguing angle is if you are seeking an arbitrary pattern, like HTHH or THT. The question then shifts to: “What is the expected number of flips needed to observe a certain pattern for the first time?” The technique commonly used is known as the overlap method or leveraging the Knuth–Morris–Pratt (KMP) table for partial matches. That helps handle situations where part of the pattern overlaps with itself.
For two consecutive heads, there is no partial overlap to worry about if you get a tail in between. But if you want a pattern like HTH, you have a scenario:
• If you are in the middle of the pattern (like you’ve matched HT so far) and you see an H, do you partially match the beginning again or do you revert to zero?
Such complexities highlight the difference between simply needing consecutive identical symbols versus matching an entire string. The Markov chain approach still works, but you now have more states (one for each possible partial match length). Then you analyze how a new flip transitions you among these partial-match states.
Pitfalls: • Failing to recognize that certain tail flips might allow you to remain in the same partial-match state. • Overlooking that a pattern could overlap with itself, leading to transitions to states other than S0 or the next immediate partial match.
How can we adapt the problem if we only flip the coin a maximum of N times?
In reality, you might not be allowed to flip the coin indefinitely. Suppose you have a budget of N flips and want the probability that HH appears at least once within those N flips. This is distinct from the unconditional expectation (which could be infinite if p < 1 for certain advanced patterns). But you might also be asked: “What is the expected time to get two consecutive heads, truncated at N flips if we fail to see them?”
One way to handle this is:

Or compute P(HH occurs by flip n) for n=1,2,…,N and sum up appropriately to handle truncated expectations.
Pitfalls: • It’s easy to treat the problem incorrectly by ignoring the possibility of not achieving HH within N flips. • If p is small or if N is small, the probability of never seeing HH is non-negligible, which must be included in your final calculation. • If you store only partial states to do a dynamic programming approach, you have to be sure you handle boundary cases when the maximum flips are reached.
These truncated versions come up if you have resource constraints (like physical time or cost) that limit how many coin flips you can observe.


