
ML Interview Q Series: Explain how a lower bound differs from a tight bound in computational complexity.


📚 Browse the full ML Interview series here.
Comprehensive Explanation
A lower bound typically describes the best-case growth rate that a function T(n) can exhibit in terms of n. In algorithmic complexity analysis, it is common to use Big Omega notation to express such a lower bound. A tight bound, on the other hand, is usually described by Big Theta notation, indicating that the function T(n) both grows at least as fast as and does not outgrow a certain function g(n).
A lower bound (Big Omega) conveys that the time complexity or resource usage of an algorithm cannot be lower than some function g(n) when n (the input size) becomes sufficiently large. A tight bound (Big Theta) implies that the algorithm's complexity grows both no faster than and no slower than some g(n) in the long run.
When discussing lower bound, one typically says that T(n) is in Omega(g(n)). When the bound is tight, it is said that T(n) is in Theta(g(n)), signifying that T(n) is asymptotically bounded both from above and below by g(n).
Lower Bound (Big Omega)

In this expression T(n) is the function representing the run-time or resource usage of the algorithm, and g(n) is the comparison function that describes the growth rate. Stating T(n) in Omega(g(n)) means there exist constants c > 0 and n0 > 0 such that for all n > n0, T(n) >= cg(n). This indicates that beyond some threshold n0, T(n) will never dip below cg(n) asymptotically. A typical example is sorting algorithms: comparison-based sorting has a known lower bound of Omega(n log n), meaning no comparison-based sorting algorithm can do better than n log n time on average in the worst case.
Tight Bound (Big Theta)
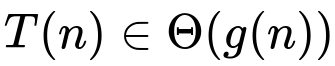
In this expression T(n) and g(n) fulfill the requirement that there exist constants c1 > 0, c2 > 0, and n0 > 0 such that for all n > n0, c1g(n) <= T(n) <= c2g(n). This implies that T(n) grows asymptotically at the same rate as g(n). If T(n) is in Theta(g(n)), it is also automatically in both O(g(n)) and Omega(g(n)), satisfying both upper and lower bounds at the same time.
Intuitively, a lower bound tells us that an algorithm cannot run any faster than a certain rate in the worst or average cases. A tight bound tells us that its runtime grows exactly on the same order as g(n), and there is no significant gap between its upper and lower constraints.
Potential Edge Cases and Real-World Considerations
In many real-world algorithmic tasks, it might be difficult to establish a strong lower bound due to special data structures, randomization, or domain-specific optimizations that beat naive analyses. Even when a tight bound of Theta(g(n)) is found in a theoretical sense, real-world performance can deviate if data distributions do not match assumptions made during asymptotic analysis. Hence, while lower and tight bounds are extremely valuable for worst-case or average-case theoretical performance, practical performance analysis and profiling often complement these asymptotic results.
How Lower Bounds Impact Algorithm Choice
Developers or researchers often look at lower bounds to understand if they should even attempt to find a more efficient algorithm than what is already known. If there is a well-established lower bound of Omega(n log n) for comparison-based sorting, for instance, one knows there is no point in searching for a sorting algorithm that beats n log n comparisons in the general case.
Follow-up Questions
Can an algorithm that is proven to have a certain lower bound in the worst case still have better performance for specific inputs?
Yes. A lower bound generally states that the algorithm cannot do better than that bound over all possible inputs in the worst (or sometimes average) scenario. However, specific inputs might be arranged in such a way that the algorithm performs significantly faster than that worst-case or average-case lower bound suggests. This is why practical performance may still be better than the theoretical lower bound for certain data distributions.
Is it possible for an algorithm to meet its known lower bound on all possible inputs?
It depends on the nature of the problem. If an algorithm always meets the lower bound, that means for every input the complexity never goes below that threshold. In many cases, algorithms have worst-case and average-case complexities aligned with the known lower bound, but for some specialized inputs, they might perform better. For certain problems, especially those proven to be in a complexity class where tight analysis is available and there are no shortcuts, algorithms do approach those bounds fairly consistently. However, for many problems, the performance may vary based on input characteristics, data distributions, or specific heuristics.
Why is it important to distinguish between best-case, worst-case, and average-case bounds?
Distinguishing them is essential because these bounds reflect different aspects of an algorithm’s performance. A lower bound often refers to a worst-case scenario, ensuring the algorithm cannot go below a certain threshold for the hardest inputs. Best-case scenarios might be significantly faster, which can be relevant in certain specialized use-cases. Average-case analysis is often the most realistic reflection of real-world performance, especially if the inputs follow certain distributions. Understanding all three cases helps in designing algorithms suited for practical environments where input distributions vary.
If T(n) is in Omega(g(n)), does that automatically imply T(n) is in O(g(n))?
No. Being in Omega(g(n)) only guarantees that T(n) does not grow more slowly than g(n). It says nothing about whether it grows faster, equal, or unbounded relative to g(n). For T(n) to also be in O(g(n)), it would have to not exceed g(n) asymptotically beyond some constant factor. If T(n) is in both Omega(g(n)) and O(g(n)), that is precisely what Big Theta(g(n)) indicates, and we call it a tight bound.
How do randomization and probabilistic algorithms affect the concepts of lower and tight bounds?
Randomization often changes the way we analyze bounds. Instead of deterministic guarantees, many randomized algorithms have expected or high-probability bounds on performance. For example, a randomized algorithm might consistently avoid certain worst-case patterns with high probability, thus yielding a better average performance than the deterministic worst-case. Still, the notion of lower bound can apply in a probabilistic sense, implying that with some high probability the runtime does not fall below a certain threshold for large n. Tight bounds can also be established in expectation or with high probability, capturing both upper and lower behaviors in the probabilistic setting.
Does establishing a lower bound on one machine or model of computation hold for other computational models?
In general, a lower bound often depends on the model of computation. For instance, the well-known comparison-based sorting lower bound of Omega(n log n) relies on the assumption that only comparisons are used to gain information about the ordering of elements. A different computational model that allows more powerful operations or queries might bypass that lower bound. Hence, bounds are usually specific to the assumptions about operations allowed, memory access patterns, or hardware constraints. Researchers must be precise about the model when discussing lower bounds and tight bounds.
Can tight bounds ever change if the underlying assumptions in the proof are updated?
Yes. If the proof of a tight bound relies on certain assumptions—such as uniform memory access, limited operations, or specific input distribution—and those assumptions no longer hold, the established bound might be invalid. A classic example is the shift from the RAM model of computation to parallel or quantum models. Algorithmic complexities can change drastically if different operations are allowed or if new techniques break the original assumptions.
Are there real-world scenarios in machine learning where big Omega (lower bounds) or big Theta (tight bounds) are relevant?
In machine learning, one often encounters complexity analyses of training algorithms, especially for large-scale gradient-based methods or for algorithms that require repeated passes over massive datasets. A lower bound might indicate the minimum number of operations or iterations needed, no matter how efficiently one codes the algorithm. A tight bound shows that both the upper and lower performance measures align well with a particular function of n (for example, n^2 or n log n). In practice, these bounds guide the design of algorithms and the hardware needed to train large models.
Below are additional follow-up questions
How does understanding a lower bound influence or constrain the way we design algorithms?
A lower bound provides a theoretical limit on how efficiently a particular problem can be solved. If we know, for instance, that a certain problem has a lower bound of n log n for comparison-based solutions, this knowledge may prevent researchers from investing time in attempts to build a comparison-based algorithm faster than n log n. Instead, they might look for alternative paradigms (like non-comparison-based solutions) or accept that the known bound is near optimal and then focus on optimizing practical aspects, such as constant factors, memory usage, or parallelization.
One subtle pitfall is when the lower bound is established under specific assumptions—like a particular computational model or distribution of inputs—and designers might incorrectly assume those constraints cover all real-world cases. It can happen that a specialized approach or data structure avoids the conditions under which the lower bound was proven, thus making it possible to beat what was once thought unbreakable. In large-scale or specialized computational settings, ignoring such edge scenarios can mean missing out on innovative solutions.
What is the distinction between weak and strong lower bounds, and when does it matter in practice?
A “strong” lower bound shows that no algorithm can beat a certain complexity for all inputs under broad assumptions. A “weak” lower bound might be established under more restrictive conditions or apply only to specific algorithm classes or subsets of inputs.
For example, a lower bound proven only for comparison-based models of sorting is strong when discussing sorting by comparisons, but it might be deemed weaker if a different computational model (like integer-based algorithms) can bypass it by exploiting arithmetic operations. In practice, recognizing the difference helps teams judge whether a lower bound is truly fundamental to a problem or conditional on model assumptions. Overlooking these distinctions can lead engineers to believe a problem is inherently unsolvable below a certain threshold, when in fact only certain algorithmic techniques are ruled out.
How do we validate that a proposed lower bound is truly correct and not just a consequence of incomplete proof techniques?
Proving lower bounds typically requires showing that every possible algorithm in a chosen model of computation must perform a certain minimum amount of work. This can involve combinatorial arguments, adversarial constructions (where an adversary picks inputs to foil attempts to solve the problem more efficiently), or information-theoretic arguments that demonstrate a certain number of bits of information must be processed.
A potential pitfall is that some proofs rely on assumptions that might later be circumvented. For example, if the proof assumes only a single processor with uniform memory access, parallel or advanced hardware might violate those assumptions. Additionally, proof techniques often evolve: new methods of analyzing or constructing algorithms may exploit gaps in old arguments. Therefore, validating a lower bound involves confirming that the proof covers all possible algorithmic techniques under the relevant model and that it does not make hidden assumptions that innovative approaches could sidestep.
How do lower and tight bounds translate to the parallel or distributed computing realm, where scaling can shift cost models?
In a parallel or distributed setting, the cost model changes significantly. Instead of focusing solely on the serial time complexity (like T(n)), attention shifts toward factors such as communication overhead, synchronization costs, and the parallel speedup. A tight bound in a serial context might no longer apply when multiple processors can work simultaneously on different parts of the input.
An example is matrix multiplication: some distributed algorithms partition the computation across many nodes, potentially surpassing the naive time complexity if network communication is efficiently handled. However, if there is a known lower bound in terms of communication overhead for distributed matrix multiplication, that bound might become the true bottleneck. Failure to account for these communication or synchronization constraints can lead to overly optimistic expectations about speedups. The real challenge is to prove lower bounds that accurately capture the interplay of parallel or distributed strategies with the core problem complexity.
If the best known algorithm exactly meets the established lower bound, can we conclusively say the algorithm is optimal?
Meeting an established lower bound suggests that, under the assumptions of the proof, the algorithm is indeed optimal. However, there might be two subtle uncertainties:
The proof might not cover all imaginable strategies or data structures. Another insight in the future could break the existing bound.
The lower bound might rely on certain computational models. If a new model or specialized hardware emerges (e.g., quantum or approximate computing), the bounds might not hold.
Hence, while meeting the bound strongly suggests optimality in the given framework, “optimal” is always qualified by the conditions and models used in the proof. In real-world engineering practice, even if the theoretical bound is met, practical factors like constant factors, memory overhead, and cache locality can make one “optimal” algorithm slower in real-time performance than another that is theoretically no better in big-O terms.
How might large hidden constants in tight bounds affect real-world adoption of an algorithm?
When T(n) is in Theta(n^2), for example, that indicates asymptotically quadratic behavior. But if the actual implementation includes extremely large hidden constants, the algorithm might still be impractical for real-world input sizes, at least until n grows so large that the n^2 term dominates. Another algorithm with a slightly worse asymptotic notation but much smaller practical overhead could be faster for the input sizes that matter in production.
In real-time or resource-limited environments, these large hidden constants and memory footprints can overshadow the asymptotic advantage of “tight” bounds. Engineers often weigh these constants, available optimizations, specialized hardware, or caching mechanisms more heavily than pure asymptotic statements.
In online or streaming models, how are lower and tight bounds assessed when input arrives continually and the algorithm must respond in real time?
Online algorithms receive their input piece by piece and must make decisions without knowledge of future elements. Consequently, performance is judged by how close the algorithm’s decisions are to what an optimal offline algorithm could achieve. Lower bounds in this setting often specify a minimal “competitive ratio” or a certain level of regret that cannot be avoided, indicating no online algorithm can exceed that performance threshold for all input sequences.
Tight bounds in streaming contexts consider both time and space complexity under one-pass or limited-pass constraints. For instance, if a streaming algorithm claims to run in sublinear space with a certain approximation guarantee, a matching lower bound would prove that any streaming algorithm using fewer than some threshold of memory cannot achieve a better approximation. Pitfalls include ignoring that some streaming algorithms may exploit randomization or additional passes, altering the fundamental assumptions of the lower bound. In real-world systems with unpredictable or bursty streams of data, these theoretical bounds guide designers in deciding whether a certain level of performance or accuracy is feasible.