
ML Interview Q Series: Explain how cross-validation is carried out and why it is beneficial in practice.

📚 Browse the full ML Interview series here.
Short Compact solution
Cross-validation is a method used to evaluate how well a model will generalize by training and testing on different subsets of the training dataset. The usual approach is to randomly partition the data into a number of equal segments (folds), then train the model using all folds except one, and test on the remaining fold. This procedure is repeated multiple times until each segment has served as the test set once. Finally, the errors from each repetition are averaged to gauge how effectively the model is expected to perform on unseen data. This approach avoids overfitting to a single subset of the dataset, helps conserve data (no separate validation set is wasted), and provides a more robust estimate of a model’s true error. One potential downside is the computational cost: the process must be repeated as many times as there are folds, which can become expensive for larger datasets.
Comprehensive Explanation
Cross-validation aims to give a better estimate of how a model trained on a finite dataset will perform when exposed to new, previously unseen data. The general premise is that by systematically varying which portion of the dataset is used for training versus testing, one obtains multiple measurements of the model’s ability to generalize. This helps mitigate pitfalls such as overfitting, where a model might show extremely low error on the specific training sample but fails to scale well to new data.
Key Steps
Cross-validation is commonly illustrated with k-fold cross-validation:
The dataset is randomly partitioned into k subsets (folds). Each fold is of roughly equal size.
For each of the k iterations, choose one fold as the test set while using all the remaining k−1 folds combined as the training set.
Train the model on this training split, then compute its performance on the chosen test fold.
Collect the performance metric (e.g., accuracy, mean squared error, or other relevant measures) from each of the k test folds.
Average these k performance scores to obtain a single performance estimate.
The final performance estimate often serves as a less biased indication of how the model might behave on fresh data. Having multiple estimates from different test folds also allows the practitioner to assess the variance of the model’s performance and thus gauge its consistency.
Mathematical View
When using k-fold cross-validation, one might compute a score eiei for each fold i. The final estimate of the model’s generalization error is often taken to be the average:
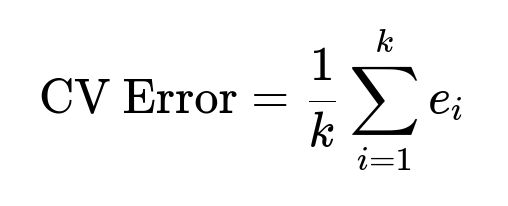

Motivations for Cross-Validation
Efficient use of data: By splitting the data into multiple folds and reusing each for validation, you effectively use all data for both training and validation across the k repeats. This is particularly useful when data is scarce or expensive to collect.
Reducing overfitting risk: Training on a single subset and testing on the same data can produce overly optimistic results. Cross-validation forces the model to be tested on data it has never seen, multiple times, thus providing a more realistic estimate of performance.
Avoiding a separate validation set: When data is limited, setting aside a fixed validation set can reduce the amount of data available for training. Cross-validation circumvents the need to hold out a subset as an exclusive validation set, yet still provides robust performance metrics.
Better generalizability measure: By averaging the performance over the k different folds, one gains confidence that the results are not specific to any particular partition of data.
Considerations and Trade-offs
Computational cost: k-fold cross-validation entails training the model k separate times. If the model is computationally expensive to train, this can become quite time-consuming.
Data distribution assumptions: It is generally assumed that the data is independently and identically distributed (i.i.d.). If there are strong temporal or grouping dependencies in the data, other cross-validation techniques (such as time-series cross-validation or grouped cross-validation) might be more appropriate.
Bias-variance trade-off in choosing k: Common values for k are 5 or 10. Larger k means more training data in each iteration (leading to a potentially lower bias in the performance estimate), but also higher computational demands. When k equals the size of the dataset (i.e., leave-one-out cross-validation), the variance of the estimate can be high, but it uses almost all available data for training in each iteration.
What if the dataset is very large and training is expensive?
In practice, one might opt for a smaller k (e.g., 3 or 5) or even use a single hold-out set if the data is sufficiently large. Another approach is to combine techniques: for instance, one can do a random split to create a train set and a smaller “test” or “validation” set, then employ cross-validation only on the train portion, saving computational cost while retaining the benefits of repeated estimation.
Potential Follow-up Questions
How would you select an appropriate value of k for k-fold cross-validation?
Choosing k depends on multiple factors. If the dataset is not very large, using a bigger k (like 10) makes sense because each fold leaves out less data for testing, giving the model more data to train on each time. This leads to a more reliable estimation of the performance. However, for very large datasets or very computationally heavy algorithms, a smaller k (like 5) often strikes a better balance between training time and performance estimation. Furthermore, if the data is extremely large, even a single hold-out split can suffice because the model tends to see enough data for robust training, and the test portion remains large enough to provide a stable estimate of generalization performance.
Could we use cross-validation for hyperparameter tuning?
Yes, cross-validation is frequently used to tune hyperparameters. For a given hyperparameter configuration, one executes a cross-validation procedure, measures performance, and repeats this for different configurations. The best hyperparameters are then chosen based on the aggregated metrics. This approach is often referred to as grid search or random search with cross-validation. One must be cautious about potential overfitting to the cross-validation folds themselves, which can be mitigated by having a final, separate test set that is only used once after hyperparameter tuning.
What are some alternatives to k-fold cross-validation?
Alternatives include:
Stratified k-fold cross-validation: Ensures class proportions are preserved in each fold, particularly useful for classification tasks with imbalanced classes.
Leave-one-out cross-validation (LOOCV): Each fold is just a single data point, so each iteration trains on all but one instance. This can be beneficial when data is extremely limited, but it can lead to high variance in the error estimate and very high computational cost.
Repeated random sub-sampling (Monte Carlo cross-validation): Repeatedly splits the dataset into training and validation sets at random, trains, and tests, then averages the results. This lacks the systematic coverage of all data points that k-fold provides, but it can be faster and simpler to implement.
Time series cross-validation (rolling window, expanding window): Used specifically for time-dependent data, ensuring training is done on historical data while future data is used for validation, preserving the temporal order.
How do you interpret the variance of the cross-validation scores?
The variance among the fold-by-fold performance metrics indicates how consistent the model is across different subsets of data. If the variance is very high, it suggests that the model’s performance might depend heavily on the specific training set. This might point to potential overfitting or strong sensitivity to the training distribution. Conversely, if the variance is low, the model’s performance is stable across different data splits, indicating it is likely more robust.
Are there scenarios where cross-validation might give misleading results?
Yes, certain scenarios can cause misinterpretation:
Data Leakage: If any preprocessing step inadvertently uses information from the entire dataset before splitting (e.g., normalizing features using the global mean and variance), the performance estimate will be overly optimistic.
Non-i.i.d. Data: For time-series data or data with strong correlations, standard cross-validation will not accurately reflect real-world performance unless adapted to the specific data structure.
Class or Distribution Imbalances: If the data distribution changes significantly over time or has imbalances that are not accounted for with stratified splitting, naive k-fold cross-validation can produce biased estimates.
How would you implement k-fold cross-validation in Python?
A straightforward approach in Python uses libraries such as scikit-learn:
from sklearn.model_selection import KFold, cross_val_score from sklearn.linear_model import LinearRegression import numpy as np # Example dataset X = np.random.rand(100, 5) y = np.random.rand(100) model = LinearRegression() kfold = KFold(n_splits=5, shuffle=True, random_state=42) # cross_val_score will perform the 5-fold training/testing internally scores = cross_val_score(model, X, y, cv=kfold, scoring='neg_mean_squared_error') print("MSE scores on each fold:", -scores) print("Average MSE:", -scores.mean())One can adapt this code to any preferred model or different scoring functions. The key idea is to establish the KFold object that dictates how the data is split, and then let
cross_val_scorehandle training on folds and calculating error metrics automatically.By using cross-validation properly—especially when combined with hyperparameter tuning—practitioners can achieve a reliable estimate of a model’s ability to generalize, guiding both model selection and deployment decisions effectively.
Below are additional follow-up questions
How do we handle data with temporal ordering or grouping in cross-validation?
In situations where observations have a natural temporal sequence (for example, stock market data, sensor readings over time, or sequential medical records), standard k-fold cross-validation can lead to overly optimistic estimates. This is because randomly shuffling and splitting temporal data ignores the fact that future observations should not be used to train a model that is meant to predict past or present.
A common approach is to use time-series-aware cross-validation. One technique is a rolling (or sliding) window method, where a fixed window of past data is used for training, and the immediate next segment is used for validation. Then the window is rolled forward in time. An alternative is an expanding window: start with a certain amount of initial data for training, then evaluate on the following time slice, then train again by incorporating both the initial training set plus the first time slice, and continue expanding in this manner.
A potential pitfall is incorrectly mixing data across time periods. If any preprocessing (like normalizing or feature engineering) is performed on the entire dataset before splitting, it can leak information from the future. Best practice is to fit transformations only on the training portion in each fold and then apply them to the validation portion.
For grouped data, a related concern arises when multiple samples come from the same entity or cluster (for example, multiple measurements from the same patient). A solution is grouped cross-validation, which ensures that all data points from a single group are kept within the same fold, preventing contamination between training and validation sets.
Can cross-validation help with model ensembling? How so?
Cross-validation can be extremely helpful when building ensembles in two major ways:
Model Stacking or Blending In stacking, you train multiple “base” models and then use their out-of-fold predictions to train a “meta” model. Cross-validation splits are used so that each base model is trained on a portion of the data and predicts on the hold-out fold. This process generates an unbiased prediction for each training sample, which is then used to train the second-level meta model.
Hyperparameter Tuning for Each Model in the Ensemble Even if the ensemble is just a simple average of multiple models, you still need to tune each model’s hyperparameters. Cross-validation is commonly used to optimize these hyperparameters so that each model is as robust as possible within the ensemble. You then combine them (e.g., by averaging or voting) for improved stability and performance.
A subtle pitfall is overfitting the ensemble if you don’t keep a truly unseen test set for final evaluation. Sometimes practitioners re-use the same folds for both model training and ensemble blending, which can inflate performance estimates. The best practice is to have an outer cross-validation loop or a final hold-out set.
How does cross-validation behave when there are outliers or anomalies in the data?
Outliers can skew cross-validation results because performance metrics might vary drastically depending on whether outliers end up in training or validation folds. Here are some key considerations:
Robust Metrics If the model and the evaluation metric are highly sensitive to outliers (e.g., mean squared error can disproportionately penalize large errors), cross-validation estimates might show high variance. Switching to more outlier-robust metrics like median absolute error can reduce instability.
Data Splitting If outliers are extremely rare but exist, a random shuffle might place them unevenly across folds. This can yield folds with unrepresentative distributions of anomalies. In such cases, it might be useful to ensure that outliers are distributed in a stratified manner (though “stratified outlier distribution” depends on how outliers are defined).
Model Choice and Transformation Sometimes robust models or data transformations (like log-transforms for heavily skewed data) can reduce the impact of outliers. You must remember to apply these transformations correctly inside each cross-validation fold to avoid data leakage.
What if the dataset is extremely large, and k-fold cross-validation is computationally very expensive?
When training huge models on very large datasets, repeatedly fitting the model k times can be impractical due to memory constraints and time. Here are some practical strategies:
Use a Smaller k Instead of k=10, consider k=2 or k=3. Though the estimate might be slightly more variable, the training cost is drastically reduced.
Use a Single Hold-Out With truly big data, a single training-validation split can suffice. As long as the chosen validation set is large enough and representative, the estimate can be reliable. One might do multiple random splits to get an average performance if resources permit.
Subsample the Dataset If the training set is enormous, subsampling and doing k-fold cross-validation on that subset can give a performance estimate. The assumption is that your subset remains representative of the underlying distribution.
Parallelization and Distributed Training Modern compute clusters allow distributing model training across multiple nodes. Each fold can be trained independently in parallel, significantly reducing overall wall-clock time. However, setting up distributed training is non-trivial and requires careful resource management and pipeline orchestration.
What is the difference between cross-validation and out-of-bag estimates in ensemble methods like random forests?
Cross-validation involves explicitly partitioning the dataset into folds, training on k−1 folds, and testing on the held-out fold. It is a user-controlled procedure typically applied to any predictive model.
Out-of-bag (OOB) error is a built-in estimate of the performance of ensemble methods (like random forests and some gradient boosting algorithms) that sample with replacement (bootstrap sampling) during training. In random forests, each tree is trained on a bootstrap sample that includes, on average, about 63% of the data points (with duplicates) from the original dataset. The remaining ~37%—the “out-of-bag” samples—serve as a test set for that specific tree. The OOB error is aggregated across all trees, providing an estimate without needing a separate validation set or cross-validation.
A pitfall arises if one confuses OOB estimates and cross-validation. While OOB can be faster since no separate folds are constructed and each tree’s unused samples provide an automatic test set, it might not always give the same depth of insight or consistent reliability as a well-conducted cross-validation, especially if the data is not large.
How do we adapt cross-validation for multi-label classification tasks?
In a multi-label classification task, each sample can belong to multiple classes simultaneously. A naive cross-validation approach might split the data such that certain labels are completely absent or severely underrepresented in some folds, distorting the training or evaluation.
To address this, one can adopt a stratified cross-validation approach extended to the multi-label setting. The strategy attempts to preserve the distribution of labels across folds. However, truly stratifying by multiple labels can be challenging if the label space is large or sparse.
Edge cases include:
Extremely Rare Label Combinations: If certain label combinations appear only once or a few times, random splits might cause entire combinations to go missing in some folds, making it hard to learn those classes. An option is to cluster or group rare label patterns together, so they remain in each fold.
Imbalanced Label Frequencies: Even with multi-label data, one label might be present in 90% of samples, while another appears in 2%. You need specialized metrics (like macro/micro-averaged F1) that can handle label imbalance, and cross-validation splits should reflect real-world distributions as closely as possible.
How do you integrate cross-validation into a typical pipeline that includes data cleaning, feature engineering, and final evaluation?
Best practice is to encapsulate the entire pipeline—from data cleaning to feature engineering and final modeling—inside each cross-validation loop. This means:
Data Split: For each fold, you split into training and validation subsets.
Fit Preprocessing: Compute any statistics (like mean, variance for normalization, or feature selection thresholds) exclusively on the training split.
Transform: Apply the trained transformers to the training split, fit the model, then apply the same transformations to the validation split.
Evaluate: Compute performance on the validation split.
A subtle but common pitfall is “information leakage” where transformations are learned on the entire dataset prior to splitting. This artificially inflates performance estimates. Another trap is if you do hyperparameter tuning or extensive feature selection outside of the cross-validation loop; it can bias the results unless you re-run those steps within each fold.
Is there a risk of data leakage in cross-validation if the pipeline is not set up properly? What are best practices to avoid it?
Yes, leakage can happen if any step of preprocessing uses knowledge of the test folds. Common leakage mistakes include:
Scaling or Normalizing Using Entire Dataset: If you compute the mean and standard deviation from the complete data, the validation fold’s statistics leak into training.
Dimensionality Reduction or Feature Selection: If you do PCA or mutual information-based feature selection on the full dataset before splitting, it uses information from the validation portion.
Temporal Data: If you shuffle and randomly split time series data, future observations might end up in training folds.
Best practices to avoid leakage:
Fit transformations only on the training fold in each iteration.
Ensure that the pipeline is constructed so that data transformations are re-fitted within each fold, never using the validation fold.
For time series or grouped data, choose an appropriate splitting strategy that respects the temporal or grouping structure.
How does cross-validation interact with large neural networks (like GPT-style models) that have millions or billions of parameters?
Large neural networks have significant training costs, and running k-fold cross-validation may be impractical in many real-world scenarios due to memory and computational constraints. Potential solutions:
Reduced k: Often, a single hold-out or a 2-fold approach is used. Even repeated random splits might be more feasible than a full 5- or 10-fold cross-validation.
Checkpoints and Partial Reuse of Weights: Sometimes you can partially reuse trained weights across folds. This is not a perfect approach because each fold’s training set is different, but transfer learning or fine-tuning can reduce total computation.
Parallel or Distributed Training: Large-scale neural networks are often trained on clusters or specialized hardware. You could train multiple folds in parallel if resources allow.
Subsampling: If you have an enormous dataset, randomly subsample each fold from the full dataset. This typically preserves the distribution, though you lose some training data each fold.
A subtlety is that large networks might exhibit stochasticity in performance due to random initialization and dropout. Repeated cross-validation folds (or repeated runs of the same fold) can help measure that variability, though it can be extremely expensive.
Can cross-validation alone guarantee good generalization performance?
Cross-validation is a strong method for estimating how well your model may generalize, but it is no guarantee of true real-world performance. Here’s why:
Differences between Training Data and True Distribution: The data you collected might not perfectly represent the real-world distribution. Even with cross-validation, you’re still sampling from a potentially biased dataset.
Unseen Shifts or Drifts: If the data changes over time (concept drift), historical cross-validation may become less predictive of future performance.
Hyperparameter Overfitting: It’s possible to overfit hyperparameters to the cross-validation folds themselves if you use them repeatedly for model selection without a final truly untouched test set.
Complex Real-World Factors: Real-world deployment can involve data pipeline differences, user behavior changes, or operational constraints not captured in the training set.
Despite these limitations, cross-validation remains one of the most systematic methods for model selection and performance estimation. However, it should be complemented with domain knowledge, a final hold-out or real-time test set, and ongoing monitoring once the model is deployed.