


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Categorical variables can pose challenges when training models because most algorithms expect numerical inputs. Encoding transforms these categorical features into numeric form. Different encoding strategies have different trade-offs in terms of model performance, interpretability, and computational cost.
Label Encoding
Label encoding involves mapping each distinct category to an integer. For example, if a feature has categories such as Red, Green, and Blue, then Red might map to 0, Green to 1, and Blue to 2. This approach is simple but can inadvertently introduce ordinal relationships between categories that do not necessarily exist. It is often used with tree-based models like random forests or gradient boosting, where the numeric magnitude of the encoded label is less critical.
from sklearn.preprocessing import LabelEncoder
data = ['Red', 'Green', 'Blue', 'Green', 'Red']
encoder = LabelEncoder()
encoded_data = encoder.fit_transform(data)
print(encoded_data) # Example output could be [2, 1, 0, 1, 2]
One-Hot Encoding
One-Hot encoding transforms each category into a binary vector, where one position is 1 and the rest are 0. This eliminates any implied ordinal relationship. The downside is that high-cardinality features generate wide, sparse matrices.
import pandas as pd
df = pd.DataFrame({'Color': ['Red', 'Green', 'Blue', 'Green', 'Red']})
one_hot_df = pd.get_dummies(df, columns=['Color'])
print(one_hot_df)
Because one-hot vectors quickly become large for features with many unique categories, advanced techniques or dimensionality reduction methods are sometimes applied.
Dummy Encoding
Dummy encoding is similar to one-hot encoding but drops one of the categories. This is done to avoid the “dummy variable trap” in linear models, where one of the categories can be inferred from the rest. For many model types like linear regression, dropping one category helps prevent multicollinearity. The difference from one-hot encoding is minimal, but it is usually safer when dealing with linear models.
Ordinal Encoding
Ordinal encoding is used when the categorical feature actually has a defined ordering (like cold < warm < hot). Unlike label encoding, the integer assignment is meaningful and reflects the inherent order of the categories. This is appropriate for ordinal data but not for nominal data.
Frequency Encoding
Frequency encoding replaces each category with how frequently that category appears in the dataset. For example, if the category Color=Green appears 40% of the time, it might get the value 0.40. This approach can sometimes capture useful signals about the prevalence of a category. However, it might not distinguish different categories that share the same frequency.
import pandas as pd
df = pd.DataFrame({'Color': ['Red', 'Green', 'Blue', 'Green', 'Red']})
freq_map = df['Color'].value_counts() / len(df)
df['Color_freq_encoded'] = df['Color'].map(freq_map)
print(df)
Target Encoding
Target encoding replaces each category with a statistical measure of the target variable for that category, often the average of the target values within that category. This is especially common in tasks like regression or binary classification because it can provide a strong signal to the model. One must be careful to avoid target leakage, so techniques like cross-validation or adding noise are used to reduce overfitting.
Here is the core mathematical formula for the average target encoding for a given category c:
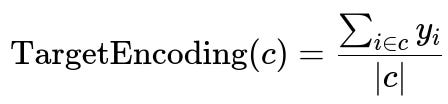
In this expression, sum_{i in c} y_i is the sum of target values for all data points that belong to category c, and |c| is the count of data points in category c.
import pandas as pd
# Suppose we have a dataset with a categorical feature 'Color' and a target 'Sales'
df = pd.DataFrame({
'Color': ['Red', 'Green', 'Blue', 'Green', 'Red'],
'Sales': [10, 20, 15, 25, 12]
})
# Compute the mean target for each category
mean_target_by_cat = df.groupby('Color')['Sales'].mean()
# Map each category to its average target
df['Color_target_encoded'] = df['Color'].map(mean_target_by_cat)
print(df)
Hash Encoding
Hash encoding converts categories to numeric vectors by hashing the category name and then reducing the hash to a fixed number of dimensions (for instance, hashing into 10 bits to produce vectors of length 10). Collisions can occur, but it is efficient for high-cardinality data when memory is limited. Hash encoding is commonly found in large-scale production systems for text processing or wide categorical features.
from sklearn.feature_extraction import FeatureHasher
data = [{'Color': 'Red'}, {'Color': 'Green'}, {'Color': 'Blue'}]
h = FeatureHasher(n_features=5, input_type='dict')
hashed_features = h.transform(data)
print(hashed_features.toarray())
Embedding-Based Encoding
Embedding-based encoding is typically used in deep learning. A categorical feature is mapped to a learned dense vector of real-valued numbers. During training, these embeddings are tuned to capture relationships between categories. This is particularly effective in large language models or recommendation systems where there are many categories, and we want to learn latent relationships.
# Pseudocode snippet showing how embeddings might be defined in PyTorch
import torch
import torch.nn as nn
# Suppose you have 100 possible categories, and you want an embedding of size 8
num_categories = 100
embedding_dim = 8
embedding_layer = nn.Embedding(num_categories, embedding_dim)
# Input: batch of categorical indices
categorical_indices = torch.tensor([1, 2, 50, 99], dtype=torch.long)
embedded_output = embedding_layer(categorical_indices)
print(embedded_output.shape) # e.g., torch.Size([4, 8])
Potential Follow-Up Questions
What are the biggest pitfalls with target encoding, and how do you avoid them?
One major pitfall of target encoding is overfitting to the training set, because each category’s encoded value is derived from the target itself. If there are categories with very few samples, their average target might not generalize. Another issue is data leakage, since the encoding could implicitly reveal information about the target in a way that will not be available at inference time.
Approaches to mitigate these issues include: Splitting the data into folds and computing the target encoding based only on out-of-fold samples. This ensures the model does not learn from the example’s own target directly. Adding noise to the encoded value to reduce variance. Applying smoothing based on the global mean of the target and the per-category mean when the category has few examples.
How do you handle unseen categories at inference time?
When using label encoding, one-hot encoding, or frequency encoding, any new category at inference time will not have a defined mapping. Common workarounds include: Assigning a special “unknown” category if the distribution of unseen categories is expected to be small. Using hashing-based encoders that can naturally hash unseen strings into a numeric vector. In embedding-based methods, adding a placeholder embedding for unknown or rare categories.
Are embeddings always better than other encoding techniques for high-cardinality data?
Embeddings can be powerful because they allow models to learn relationships between categories. However, embeddings require more hyperparameter tuning (such as embedding dimension) and a suitable deep learning architecture to train them effectively. They also need large amounts of training data to generalize well. In contrast, simpler encodings like frequency or target encoding can work well in many situations and require fewer computational resources. Whether embeddings are “better” depends on the size of the data, the complexity of the problem, and the model type.
Why might one choose hashing over label or one-hot encoding?
Hashing can be beneficial when dealing with extremely high-cardinality features because it does not require storing all unique categories. It saves memory and can handle unseen categories by automatically assigning them to one of the existing hash buckets. The collision risk might be acceptable if the dimensionality is chosen carefully. One-hot encoding becomes infeasible for extremely large numbers of categories, and label encoding may not capture the nuances in very large feature spaces.
How does the scale of frequency- or target-encoded features affect linear models vs. tree-based models?
For linear models, scale can matter because large numeric values might dominate gradient updates. Standardizing or normalizing the encoded features can be beneficial. For tree-based models, scale is less of an issue, because these models split based on threshold comparisons rather than distances. However, if frequency or target encoding introduces spurious relationships or unusual distributions, tree-based models can still be misled, so it is important to validate these encodings carefully.
Would dummy encoding fix the ordinal assumptions introduced by label encoding?
Yes, dummy encoding (or one-hot encoding) eliminates the ordinal assumption by creating separate binary features. In label encoding, categories with higher assigned integer values might be interpreted by some models as having a higher “rank.” Dummy encoding does not impose this because each category is represented independently. This is why dummy encoding is often safer for nominal data. However, it comes at the cost of increasing dimensionality.
What if you have a categorical feature with thousands of categories and not much data?
High-cardinality features with limited data per category can lead to sparse representations when using one-hot encoding, and overfitting with target encoding. Strategies include: Combining rare categories into an “other” category to reduce dimensionality. Using hashing to project all categories into a manageable space. Applying an embedding-based approach with regularization to learn meaningful dense vectors.
These considerations ensure that the approach to encoding large categorical features is both memory-efficient and robust against overfitting.
Below are additional follow-up questions
How do you approach choosing the encoding method for nominal vs. ordinal categories?
Nominal categories do not have a natural ordering (e.g., color = red, green, blue). In contrast, ordinal categories carry a meaningful sequence (e.g., size = small, medium, large). For nominal data, one-hot or dummy encoding is often a strong default because it preserves no implicit rank. However, if you have a high-cardinality nominal feature (many distinct categories with limited data), hashing or target encoding might be more pragmatic, provided you manage the risk of overfitting. For ordinal data, encoding the categories as sequential integers often makes sense, as the numeric relationship among the encoded values can reflect the natural order.
Edge cases or pitfalls include situations where a feature appears ordinal but is actually arbitrary (like “product version” or “school grade” where the difference between categories is not uniform). Misinterpreting an ordinal feature as nominal (or vice versa) can introduce biased relationships into the model and hurt performance. When in doubt, it is helpful to do an exploratory analysis, potentially with domain experts, to decide if an ordering truly exists.
Can multiple encoding methods be combined in the same dataset, and if so, why might you do that?
It is possible and sometimes beneficial to apply different encoding strategies for different features within the same dataset. For example, you may have an ordinal feature like “education level,” which naturally fits ordinal encoding, while another feature “city name” might need hashing or frequency encoding if it has thousands of unique values. Each feature’s structure (cardinality, ordinal vs. nominal nature, distribution of categories) can guide the choice of the most appropriate encoding.
By mixing encodings, you can reduce dimensionality for certain features with high cardinality while preserving interpretability for those with fewer categories. A potential downside is increased code complexity: multiple transformations must be managed consistently in training, validation, and inference pipelines. Additionally, the combination of encodings can sometimes introduce subtle interactions that are not captured well by simpler models, so verifying performance with cross-validation is crucial.
What special considerations arise when encoding categorical features that contain missing or null values?
When a categorical feature has missing values, you have to decide whether to treat “missing” as a separate category or impute it. One-hot encoding might allow you to create a separate dummy column for missing values. Label encoding often forces you to encode missing as a numeric value unless you remove or impute. For advanced methods like target encoding, missing values can lead to misleading target averages if not handled properly.
If “missing” is systematic (e.g., certain attributes are missing only for specific segments of the population), encoding them as their own category might capture that information. However, if the data are missing at random, you might prefer to impute with a placeholder such as “Unknown.” You can also consider predictive imputation methods if the data justifies the complexity. The main pitfall is inadvertently introducing a spurious signal if the pattern of missingness is correlated with the target.
How would you handle time-varying categories or categories that change over time?
When categories evolve over time (for instance, product lines being introduced or retired), static encodings can lead to mismatches during inference, especially if new categories emerge after model training. One solution is to periodically retrain or update the encoding scheme so the model remains in sync with the current data distribution.
Another strategy involves using hashing because it does not rely on a fixed mapping of categories to integer or one-hot indices. Hashing will map new or changed category strings to some bucket. While collisions may occur, it gracefully accommodates changes over time. A more advanced approach is to maintain a rolling window or time-based partitioning for target encoding, ensuring you only use historical data to encode categories so you do not leak future information into the model.
How do you detect and manage data drift when using categorical encodings?
Data drift occurs when the statistical properties of your features (including category distributions) shift over time. With categorical data, drift might manifest as entirely new categories emerging or a change in the relative frequencies of existing categories. To detect drift, you can track metrics like the distribution of categories and compare them with historical baselines.
In practice, you might deploy a monitoring system that checks if the frequency of each category is within a certain confidence bound. For more advanced detection, you can use KL divergence or other distributional comparison metrics. If drift is detected, you might need to retrain the encoder (e.g., update target or frequency encoding to reflect current data). Additionally, carefully designed retraining policies or continuous learning can keep pace with changes, but you must ensure that you do not encode rare or transient categories in a way that confuses the model.
Can advanced encoding strategies degrade performance in some scenarios?
Yes. While methods like target encoding, frequency encoding, or embeddings can be very powerful, they can also lead to overfitting if your data do not support the complexity. For example, target encoding can cause data leakage when the model inadvertently learns from the target values in a direct way, especially in small datasets. Similarly, embedding-based encodings might require extensive training data to learn meaningful embeddings. If the dataset is too small, the embeddings might be unstable or converge to trivial solutions.
Additionally, advanced encodings can reduce transparency. For instance, with embeddings, it is not straightforward to interpret the learned vectors. In highly regulated industries, explainability might be critical, making simpler encodings preferable. It is always wise to perform robust validation and interpretability checks (such as feature importance or partial dependence) after implementing advanced encoding approaches.
If you have severely imbalanced categories, how do you ensure the encoding doesn’t overshadow minority classes?
When categories have wildly different frequencies, methods like frequency or target encoding can become biased toward the dominant categories. In frequency encoding, minority categories might yield extremely small values that the model might disregard. In target encoding, categories with only a few samples might produce noisy averages, leading the model to overfit those small categories.
Strategies to mitigate these issues include: • Grouping rare categories together into a single “other” class if they constitute a small overall portion of the dataset. • Applying smoothing in target encoding, blending the category’s own average with the global mean when the category frequency is low. • Using techniques like balanced sampling or upsampling minority categories if it makes sense for the use case.
You should also measure model performance for these minority categories specifically, possibly via recall or F1-score, to ensure that they are well represented after encoding.
When dealing with complex feature interactions, can encoding influence feature crosses or second-order interactions?
Yes, the way a categorical feature is encoded can significantly impact how a model handles interactions with other features. For instance, in linear or logistic regression, dummy encoding makes interactions more explicit—you might choose to include interaction terms by multiplying dummy columns from different features. In contrast, label encoding might obscure how categories interact if it imposes an arbitrary numeric ordering.
Tree-based models can somewhat learn interactions on their own. However, certain encodings might still help or hinder the process. For example, target encoding could expose a strong signal in a single numerical dimension that interacts more simply with other features. By comparison, one-hot encoding might require deeper trees to combine signals from multiple binary columns. The key is to test how these interactions show up in validation metrics and carefully tune both the encoding and model hyperparameters.
Are there scenarios where non-invertible encodings like hashing create problems for debugging or post-processing?
Hashing encoders lose the direct mapping back to the original category, so if you need to interpret which category contributed to a specific prediction, you cannot directly invert the hashed vector. This can complicate root cause analysis or model debugging, because you only know which hash bucket an input fell into, not which original category triggered that assignment. If interpretability is a priority—such as explaining errors or compliance with regulations—hashing might not be ideal.
In production environments, this is sometimes acceptable if performance and memory considerations outweigh the need for detailed interpretability. Another partial workaround is to store a small mapping of known categories to hash buckets and attempt to guess which category might have been used at inference, though collisions or unknown categories remain ambiguities.
What are some considerations for encoding text-based categorical features, such as user IDs or URLs, that might be extremely sparse?
Text-based categorical features like user IDs, session IDs, or even URLs can have massive cardinalities, with potentially millions of unique items. Traditional one-hot or even label encoding becomes infeasible at this scale. Hashing can be a good approach to manage memory usage and handle new or rare items gracefully. Embeddings are also an option if you have sufficient data and a deep model capable of learning meaningful patterns from those identifiers.
One common pitfall is ignoring domain knowledge. For instance, a URL might contain subdomains or path segments that are semantically relevant. Instead of hashing the entire URL string, it might be beneficial to break it down or parse it into more meaningful sub-features. Another pitfall is ignoring new categories that only appear in the test set. Properly partitioning your data for training and validation and applying the same transformations at inference (including fallback strategies for unseen tokens) are crucial.
Does the scale of encoding matter for distance-based algorithms like k-NN?
For distance-based algorithms such as k-nearest neighbors or clustering methods, the numeric scale of features heavily impacts distance calculations. Some encodings, like label encoding, can assign arbitrary integers that skew distance metrics in ways that do not reflect real category similarities. One-hot encoding typically increases dimensionality and might inflate distances for categories that differ by only one bit.
If you need to use k-NN with categorical data, you might consider: • Using an encoding that preserves some notion of similarity among categories (possibly embedding-based approaches). • Applying weighting or normalization to ensure the categorical feature does not dominate distance calculations. • Considering specialized distance metrics for categorical features, such as Hamming distance for one-hot vectors.
Pitfalls include performance and memory overhead due to high-dimensional spaces, as well as the potential need for large training sets to find reliable neighbors in the expanded feature space.
How do you adapt embeddings learned for categorical features if your categories expand or contract over time?
If your category set changes (e.g., new product IDs get introduced, old ones are removed), the embedding layer’s size or the mapping from category to index might become outdated. One practical solution is to include a special “unknown” index in the embedding layer for unseen categories. However, if the category space shifts substantially, you may need to retrain or at least fine-tune the embedding layer so that new categories receive meaningful vectors.
A potential pitfall is that if you keep adding new categories to the embedding, you can run out of embedding slots. Some production systems mitigate this by using a hashing trick before feeding into an embedding layer, though this might introduce collisions. Another alternative is periodic or online updates to the embedding matrix, though the complexity can be high. Monitoring performance for new categories is essential to ensure they are properly represented and not producing random embeddings that degrade model predictions.