
ML Interview Q Series: Explain the bias-variance trade-off in machine learning and show how to represent it with an equation.

📚 Browse the full ML Interview series here.
Short Compact solution
The bias-variance trade-off can be summarized by an expression for the overall model error as the sum of three components: bias, variance, and irreducible error. More flexible models typically exhibit low bias but higher variance, while simpler models tend to have higher bias and lower variance. Bias arises when a model is too simplistic and underfits the data, failing to adequately represent the relationship between features and the target. Variance occurs when a model is overly sensitive to the training data and overfits, reacting to noise and minor fluctuations. Irreducible error is the portion that cannot be directly eliminated by the model. The aim is to find a balance so that neither bias nor variance dominates, thereby avoiding underfitting and overfitting.
Comprehensive Explanation
The bias-variance trade-off is central to understanding how machine learning models generalize to unseen data. When we build a model, we try to ensure it learns from the training set in such a way that it captures the true underlying pattern but does not get misled by the noise or peculiarities in the training data. One way to formalize this is through the following equation:
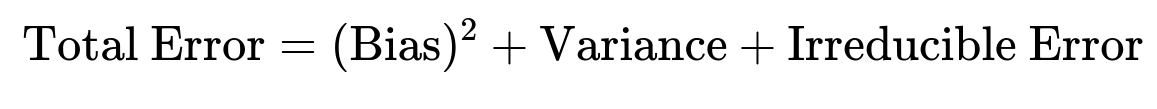
Each term plays a distinct role.
Bias reflects the error that originates from wrong assumptions or overly simplistic model structures. A high-bias situation indicates that the model underfits the data, often showing poor performance both on the training set and on new, unseen data. This might arise when using a model that is too rigid, like a simple linear regressor for a complex, highly nonlinear relationship.
Variance refers to how sensitive the model is to small fluctuations in the training data. A model with high variance learns details (and noise) very specific to the training set, leading to strong overfitting. This results in excellent performance on the training data but usually poor generalization. Very flexible models, such as highly complex neural networks or decision trees grown to large depth without constraints, are more prone to having high variance.
Irreducible error is the noise level in the data that no model can remove, arising from measurement noise or inherent randomness in the system being modeled. It is sometimes also called the Bayes error (though strictly speaking, the Bayes error is the theoretical minimum under certain assumptions).
The trade-off occurs because attempting to decrease bias (through more flexible, powerful models) can inadvertently increase variance, while methods to reduce variance (such as regularization, simpler architectures, or stronger constraints) can cause the bias to go up. A good approach is to find a middle ground that yields strong predictive performance on both training and unseen data.
From a practical standpoint, controlling the bias-variance trade-off involves selecting appropriate model complexity and regularization techniques. When training a neural network, for instance, you might adjust the number of layers, the number of neurons per layer, or the dropout probability. In decision trees or random forests, you might limit the maximum depth or the minimum number of samples required to split. The process of hyperparameter tuning is effectively about striking an optimal trade-off: neither too simple (excessive bias) nor too complex (excessive variance).
One simple demonstration can be seen in a polynomial regression scenario. If the polynomial degree is set too low (for example, a constant or linear fit), the model’s bias is high because it cannot capture more complex patterns. If the polynomial degree is very high, the variance will likely be large, meaning it will fit the training set well but fail on new data.
Below is a small Python snippet demonstrating polynomial regression and how we might watch for bias or variance issues:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# Generate synthetic data
np.random.seed(42)
X = np.linspace(0, 10, 50).reshape(-1, 1)
y = 3 * X.squeeze()**2 - 2 * X.squeeze() + 5 + np.random.normal(0, 5, size=len(X))
# Split into training and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Evaluate different polynomial degrees
degrees = [1, 2, 10]
for d in degrees:
poly = PolynomialFeatures(degree=d)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
lr = LinearRegression()
lr.fit(X_train_poly, y_train)
train_mse = mean_squared_error(y_train, lr.predict(X_train_poly))
test_mse = mean_squared_error(y_test, lr.predict(X_test_poly))
print(f"Degree: {d}, Train MSE: {train_mse:.2f}, Test MSE: {test_mse:.2f}")
In this example, a polynomial of degree 1 (which is a straight line) might underfit (high bias, low variance), while a very large polynomial degree might overfit (low bias on training set, high variance, and worse performance on the test set). The sweet spot, where you have a good balance between both, is the idea behind the bias-variance trade-off.
Potential Follow Up Question: Why do we call it a "trade-off"?
It is labeled a “trade-off” because decreasing bias generally requires increasing model complexity, which typically leads to higher variance, and vice versa. Balancing these two tendencies is critical for optimal performance. Making a model more complex by adding more parameters, features, or layers usually reduces bias but can make the model more prone to small variations in the training data, thus raising variance.
Potential Follow Up Question: Can we reduce both bias and variance simultaneously?
In some circumstances, with improved data quality or larger training sets, it is possible to reduce both bias and variance together. For example, if you gather significantly more data, or use more advanced regularization strategies, or introduce carefully selected features, you might improve the model’s capacity to generalize while also reducing overfitting. However, in many situations with a fixed dataset and a particular model class, reductions in bias usually come with an increase in variance and vice versa.
Potential Follow Up Question: How do regularization methods affect the bias-variance trade-off?
Regularization techniques like L2 (ridge) or L1 (lasso) regression add a penalty on model complexity. They effectively limit the magnitude of the model parameters, preventing them from fitting tiny fluctuations in the data. This normally reduces variance, but it can also raise bias because the model might not capture all the nuances in the data. For neural networks, techniques such as dropout, weight decay, or early stopping serve a similar purpose.
Potential Follow Up Question: How do we measure bias and variance in practice?
Measuring bias and variance directly can be done using a repeated sampling approach, where multiple models are trained on multiple subsets of the data to see how much the predictions vary (an estimate of variance) and how far the average predictions are from the true values (an estimate of bias). In practice, though, data scientists often rely on error metrics such as cross-validation scores to diagnose overfitting or underfitting and then decide whether to adjust model complexity.
Potential Follow Up Question: How do we handle irreducible error?
The irreducible error often stems from noise or randomness in the underlying process. While you cannot remove this from the system entirely, you can try to reduce measurement error by improving data collection methods, cleaning the data, removing outliers, or refining how features are measured. In many real-world tasks, it might be impossible to eliminate this error completely, but being aware of its existence helps avoid excessive attempts to overfit a model in pursuit of unattainable perfection.
Below are additional follow-up questions
In an unsupervised setting, does the bias-variance trade-off still apply, and if so, how?
Even though the bias-variance trade-off is often discussed in the context of supervised learning, it also holds relevance in unsupervised learning. In an unsupervised setting—clustering or dimensionality reduction, for example—the notion of bias and variance pertains to how well the unsupervised method is capable of capturing underlying structures versus how much it overreacts to noise or arbitrary patterns.
A typical example would be clustering. If you set the number of clusters too low (like a simplistic k=2 when the data needs k=5 to capture complexity), you might end up with high bias because your chosen approach cannot represent the data’s true segmentation. Meanwhile, if you allow extremely flexible clustering methods or pick a large k without constraints, you risk high variance: the model can create many small clusters that overfit to local data fluctuations.
Pitfalls and Edge Cases
Ill-defined "true" labels: Because there are no ground-truth labels, it can be tricky to measure bias or variance directly. This can lead to confusion about whether the chosen hyperparameters truly minimize error or just produce a seemingly plausible partition.
Difficulty in model evaluation: Validating unsupervised methods typically requires metrics like silhouette score or other cluster quality measures, which can be misleading if the data has special structure or outliers.
High dimensional data: In high-dimensional feature spaces, many clustering or dimensionality reduction algorithms are more susceptible to random noise (high variance) if they’re overly flexible. Conversely, methods that overly constrain the dimensionality (such as forcing a small latent space) may exhibit high bias.
How do ensemble methods address the bias-variance trade-off?
Ensemble methods, such as bagging or boosting, combine multiple “weak” or “base” learners to produce a more robust final predictor. The key principle is that by pooling several models, the variance of the combined model can be reduced, provided the base learners are sufficiently diverse. Boosting algorithms, like AdaBoost or Gradient Boosting, iteratively correct the errors made by previous learners, aiming to reduce overall bias. By contrast, bagging methods (including random forests) primarily tackle variance by averaging over many uncorrelated models.
Pitfalls and Edge Cases
Overly correlated base learners: If the base models in an ensemble are highly correlated (e.g., all are trained on nearly identical data or have highly similar architectures), the ensemble may not significantly lower variance.
Computational overhead: Ensembles often require significant computational resources during both training and inference. This can be a limitation in real-time environments.
Imbalanced data: If the data is highly imbalanced, ensembles need careful strategies (like stratified sampling or custom loss functions) to avoid systematically ignoring minority classes, potentially leading to high bias or high variance for those underrepresented samples.
How does dimensionality reduction influence the bias-variance trade-off?
Dimensionality reduction techniques (like PCA, autoencoders, or other manifold learning approaches) can help reduce variance by simplifying the feature space. By focusing on the most informative directions or latent factors, the model is less prone to overfitting to noisy or irrelevant features. However, if too much information is discarded, the model may not capture essential data structure, thus increasing bias.
Pitfalls and Edge Cases
Choosing the number of dimensions: Selecting the cutoff for principal components or the latent dimension can be tricky. Too few dimensions raise bias; too many might reintroduce noise and yield high variance.
Nonlinear data: Linear methods like PCA can have high bias if the data truly lies on a complex, curved manifold. Nonlinear methods (e.g., t-SNE, UMAP, or autoencoders) can reduce that bias but risk higher variance.
Interpretability trade-off: Reducing dimensions can make the final model less interpretable if the transformation is not straightforward. This can hide issues of overfitting or underfitting in the transformed space.
What are practical considerations for monitoring the bias-variance trade-off during training?
In real-world practice, you might monitor training metrics (e.g., loss on the training set) and validation metrics (e.g., loss on a held-out set) simultaneously. If the training metric is significantly better than the validation metric, it usually indicates overfitting (high variance). If both metrics are similarly poor, underfitting (high bias) is likely. Tools like learning curves (tracking both training and validation error as a function of training size) are very helpful.
Pitfalls and Edge Cases
Validation set not representative: If the validation set does not reflect the true distribution of future data, the difference between training and validation metrics can be misleading.
Data leakage: Accidental leakage of test or validation data into training can cause artificially low training bias and lead to unrealistically low variance in evaluations.
Non-stationary data: When the data distribution changes over time, monitoring bias and variance becomes more complex. A good model may appear to overfit (or underfit) simply because the distribution drifted from what it was at training time.
How does transfer learning affect the bias-variance trade-off?
In transfer learning, a model pretrained on a large dataset is fine-tuned on a smaller target dataset. This generally reduces variance because the pretrained weights can serve as a strong initialization that encodes broad data patterns. However, if the source domain is very different from the target domain, biases learned in the source domain could manifest as underfitting or mismatch in the target domain. Fine-tuning typically adjusts these biases if enough target data is available.
Pitfalls and Edge Cases
Mismatch between source and target domains: A model pretrained on images of natural scenes may struggle with medical imaging data, for example, creating a systematic bias if those fine-tuning steps do not adapt well.
Limited target data: If the target dataset is too small, the model can overfit quickly in the final layers. This introduces variance that is not fully mitigated by the pretrained initialization.
Layer freezing strategies: Freezing too many layers might leave the model with a high bias for the new task; unfreezing too many layers could increase variance when the target data is not large enough.
How do noisy labels affect bias and variance?
Noisy labels (where some training samples have incorrect target values) can significantly impact the trade-off. A model with high capacity may overfit to these incorrect labels, resulting in increased variance. Attempts to combat label noise—like label smoothing or specialized loss functions—may add bias by discouraging the model from fully trusting the original labels.
Pitfalls and Edge Cases
Systematic label noise: If the noise follows a predictable pattern (e.g., certain classes are mislabeled), the model may develop a systematic bias.
Robustness algorithms: Methods such as robust loss functions or noise-robust training techniques can reduce variance but might inadvertently boost bias if they ignore genuine outliers.
Cleaning the data: In some settings, manually cleaning mislabeled samples is the simplest and most effective approach, but it is time-consuming and expensive.
How do you approach the trade-off in real-time or streaming applications?
In real-time or streaming scenarios, data arrives continuously, and models are updated on-the-fly. Overly complex models with high variance might adapt too quickly to transient changes or noise, while simpler models with higher bias might adapt too slowly.
Pitfalls and Edge Cases
Concept drift: If the underlying distribution of data changes (concept drift), a model with insufficient capacity (high bias) might fail to adapt, whereas an over-flexible model (high variance) might chase short-term fluctuations that are not stable.
Resource constraints: In streaming settings, memory and computational budget can be limited. Overly complicated models that repeatedly retrain can be impractical.
Delayed labeling: In many real-time applications, labels come with a delay, making it harder to diagnose bias or variance issues quickly.
Does the size of the training set directly determine the nature of the bias-variance trade-off?
Generally, having more training data reduces variance because the model sees more examples and learns more robust patterns. At the same time, it does not inherently change the model’s bias; if the model is structurally limited, additional data alone may not fix the systematic underfitting. However, even large training sets can lead to high variance if the model is extremely flexible and not regularized appropriately.
Pitfalls and Edge Cases
Data quality vs. quantity: A large amount of noisy or non-representative data can still lead to overfitting or underfitting in unexpected ways.
The “long tail” problem: Even with a large dataset overall, if certain categories or scenarios are underrepresented, the model can exhibit high variance in those underrepresented segments.
Data imbalance: A bigger training set does not always help if the imbalance remains in the same proportion and the model simply gets an excess of the majority class labels.
In reinforcement learning, how does the bias-variance trade-off manifest?
Reinforcement learning (RL) has a bias-variance trade-off related to how we estimate returns (e.g., Monte Carlo vs. Temporal Difference methods) and how the policy or Q-function approximates the environment. High bias methods might rely on simplistic approximations of the value function, while high variance methods can fluctuate wildly in value estimates due to limited sampling of state-action transitions.
Pitfalls and Edge Cases
Sparse rewards: In RL tasks with rare rewards, aggressively updating the policy from each small batch of experience can introduce high variance, but being too conservative can cause slow learning (high bias).
Off-policy vs. On-policy: Off-policy approaches (like Q-learning with experience replay) can reduce variance by reusing data, but if the behavior policy distribution is drastically different from the target policy, it can introduce biases.
Function approximation: Complex neural network approximators for Q-functions or policies can drastically reduce bias but risk overfitting to limited episodes, driving up variance.
What if domain knowledge is available? How does expert insight influence the bias-variance trade-off?
Incorporating domain knowledge—via carefully engineered features, meaningful architecture choices, or constraints—usually reduces variance by giving the model a strong inductive bias. At the same time, it can raise or lower the systematic bias depending on whether that domain knowledge accurately reflects the true relationships. It is essential to ensure domain assumptions do not conflict with reality.
Pitfalls and Edge Cases
Outdated expertise: Relying on domain experts with incomplete or outdated assumptions can bake systemic bias into the model.
Overly rigid constraints: Hard-coded constraints or complex feature engineering might over-limit the model’s capacity to learn unexpected but relevant phenomena.
Hidden confounders: Domain knowledge might mask confounding variables that the model should have discovered, introducing hidden biases.