
ML Interview Q Series: How can one devise an ML-driven solution that automatically curates a user-specific weekly playlist, similar to Spotify's Discover Weekly?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
A machine learning system to generate a user-specific playlist like Discover Weekly generally integrates collaborative filtering, content-based signals, and user behavior analytics. The high-level idea is to match each user to new songs that they are likely to enjoy, while also balancing novelty and diversity. Below is a detailed breakdown of how to design such a system:
Gathering Data
Data collection is fundamental. For each user, we gather:
Historical play counts for songs or artists.
Explicit feedback such as likes, dislikes, or playlist additions.
Implicit feedback such as how often a track is skipped, time spent playing a song, or repeated plays.
Demographic or contextual information about the user (e.g., region, device type) when available.
Audio-based metadata (tempo, genre, instrumentation) and text-based metadata (song descriptions, artist info) for content-based analysis.
Collaborative Filtering Backbone
A large portion of the recommendation pipeline often relies on collaborative filtering. Collaborative filtering capitalizes on the idea that users with similar music-taste histories might enjoy similar tracks in the future. One popular approach is low-rank matrix factorization, where we decompose the user-item interaction matrix into latent factors.
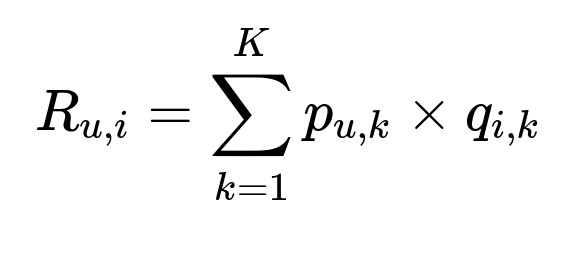
Here:
R_{u,i} in plain text means the rating or implicit feedback for user u on item i.
p_{u,k} in plain text means the latent factor for user u in dimension k.
q_{i,k} in plain text means the latent factor for item (song) i in dimension k.
K in plain text indicates the dimensionality of the latent factor space.
These user-specific and item-specific latent factors p_{u} and q_{i} capture hidden preferences and characteristics. To learn these, we typically optimize a loss function that measures the discrepancy between R_{u,i} (the actual feedback) and the predicted sum of p_{u,k} times q_{i,k}.
Content-Based Signals
In addition to collaborative filtering, a content-based approach uses the attributes of a track (e.g., tempo, key, lyrics embedding). By analyzing each track’s acoustic fingerprint (e.g., from audio spectrogram embeddings) or textual metadata (e.g., from artist descriptions or genre tags), you can recommend similar-sounding tracks to the user’s known favorites. This is helpful for:
Cold start for new or rare tracks.
Users whose interaction data is insufficient for purely collaborative approaches.
Discovering lesser-known songs that align with the user’s broad listening profile.
Hybrid Recommendation
A hybrid system often combines collaborative filtering scores and content-based scores. One way is to form a weighted average of these two kinds of relevance or ranking signals. Another approach is to concatenate user latent vectors with content-based features and feed them into a neural network that outputs a ranking score for each song.
Building the Pipeline
Extract user and track embeddings using matrix factorization or advanced approaches such as neural collaborative filtering.
Extract or compute content embeddings using models like audio-based CNNs or text transformers for lyrics or track metadata.
Merge these representations in a model that predicts how likely each user is to enjoy a given song.
Rank songs for each user and generate a curated list.
Apply business logic constraints such as diversity in genres, novelty, or recency of release to keep recommendations fresh.
Practical Implementation Example (Using PyTorch)
import torch
import torch.nn as nn
import torch.optim as optim
class HybridRecommender(nn.Module):
def __init__(self, num_users, num_items, latent_dim, content_dim):
super(HybridRecommender, self).__init__()
# Embeddings for collaborative filtering
self.user_embedding = nn.Embedding(num_users, latent_dim)
self.item_embedding = nn.Embedding(num_items, latent_dim)
# Dense layers for content-based and user embeddings
self.fc = nn.Sequential(
nn.Linear(latent_dim + content_dim, 128),
nn.ReLU(),
nn.Linear(128, 1) # Output a score
)
def forward(self, user_ids, item_ids, item_content):
# user_ids: [batch_size]
# item_ids: [batch_size]
# item_content: [batch_size, content_dim]
user_emb = self.user_embedding(user_ids) # [batch_size, latent_dim]
item_emb = self.item_embedding(item_ids) # [batch_size, latent_dim]
# Combine user/item embedding with content-based features
combined = torch.cat((user_emb * item_emb, item_content), dim=1)
score = self.fc(combined) # [batch_size, 1]
return score
# Hypothetical usage:
num_users = 10000
num_items = 50000
latent_dim = 64
content_dim = 32
model = HybridRecommender(num_users, num_items, latent_dim, content_dim)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.MSELoss() # or some ranking loss
# Suppose we have training batches of (user_ids, item_ids, item_content_features, target_score)
# The training loop might look like:
for epoch in range(num_epochs):
for user_ids_batch, item_ids_batch, content_batch, target_batch in train_loader:
optimizer.zero_grad()
preds = model(user_ids_batch, item_ids_batch, content_batch).squeeze()
loss = loss_fn(preds, target_batch)
loss.backward()
optimizer.step()
Though simplified, this pipeline demonstrates combining collaborative signals (latent vectors) with content-based features for track scoring. It can be extended to incorporate additional user or track features.
Fine-Tuning and Generating Playlists
To generate the final weekly playlist:
Calculate a “relevance score” for each track per user.
Sort tracks by that relevance.
Inject novelty constraints such as tracks the user hasn't played.
Optionally apply a re-ranking mechanism (e.g., to ensure a diverse set of genres).
Provide the user with a curated list of top tracks for that week.
Potential Pitfalls
Cold Start for New Users: Minimal user interaction data means relying more on content-based or demographic-based recommendations.
Popularity Bias: The system might skew toward popular tracks if not carefully designed to promote diversity.
Over-personalization: The playlist could become too narrowly focused on a specific genre, leading to stagnation.
Data Quality: Inaccurate metadata or inconsistent logging of user interactions can degrade recommendation performance.
Scalability: Recalculating recommendations weekly for millions of users can be computationally expensive. Efficient approximate nearest neighbor and caching strategies are essential.
What if we have many new users with very sparse history?
The system typically relies more on content-based or demographic-based techniques for new users. In some cases, a generic or trending playlist with slight personalization based on basic user attributes (e.g., region or top-level genre preference) can fill the gaps while enough data is gathered. Another approach is to incorporate user sign-up funnel data like favorite artists selected during onboarding.
Could we integrate a user’s real-time feedback to immediately refine recommendations?
Yes. Immediate feedback—such as skipping a suggested track or repeated plays—can be used to update an incremental model or to adjust short-term rankings on the fly. Practical systems often maintain a near-real-time pipeline where such micro-interactions feed into a faster ranking component. This short-term re-ranking layer can complement the main offline-trained recommendation model.
How do we maintain novelty without sacrificing user satisfaction?
One tactic is to blend tracks the user already loves with new discoveries. Some systems incorporate an “exploration factor” that occasionally surfaces less-certain but potentially interesting recommendations. Another method is a two-tier approach: top tracks from collaborative filtering plus a separate slot for new or less-popular tracks that still align with user preferences.
How do we measure success for a weekly recommendation system?
Common evaluation metrics include:
User engagement rate, such as the proportion of recommended tracks listened to in full.
Skip rate: how quickly a user abandons a recommended track.
Save/like rate for recommended songs.
Longer-term metrics like user retention, total session duration, or the number of distinct artists discovered. Offline metrics (e.g., Mean Average Precision, Normalized Discounted Cumulative Gain) can be used for iterative model development, but online A/B testing is the ultimate measure of success.
How do we ensure computational efficiency at a large scale?
A production pipeline often involves:
Precomputing user and item embeddings offline in a batch process.
Using approximate nearest neighbor search to quickly retrieve candidate items.
Maintaining specialized indices or data structures (such as hierarchical clustering or partition-based trees).
Leveraging cloud platforms with distributed computing frameworks to scale matrix factorization or neural training.
These strategies together enable timely updates of Discover Weekly–style playlists for a massive user base.
Below are additional follow-up questions
How do we handle malicious users who try to artificially boost or degrade certain tracks in the recommendation system?
Malicious behavior might include repeatedly playing or streaming a song (possibly using bots) to inflate its popularity or providing intentionally misleading feedback. A robust approach includes:
Anomaly Detection By tracking typical user engagement patterns, you can identify and flag suspicious spikes. Anomalies can be detected with user-behavior profiles, clustering approaches, or a classification model trained on known malicious patterns. Suspicious activities might be excluded or down-weighted in the recommendation pipeline.
Threshold Filtering Impose thresholds (e.g., maximum number of plays or likes in a certain time window) beyond which the system no longer counts new interactions at full weight. This mitigates spammy patterns from having a big influence on track popularity.
Weighted Feedback Instead of letting every piece of feedback have the same impact, weigh the feedback by user trust scores or user engagement consistency. Long-standing users with a history of normal usage might have higher trust. Suspected bot accounts get lower trust weights.
Pitfalls
Over-filtering can penalize genuine users with unusually high listening rates.
Malicious users can adapt by distributing their efforts across many accounts.
Maintaining a real-time detection pipeline is computationally expensive.
How do we incorporate a time-based decay to ensure more recent user interactions carry higher weight?
Time-based decay ensures that recent music preferences have a stronger effect on recommendations than older preferences. A straightforward technique is to multiply older interactions by a weight that diminishes over time. One common decay function is an exponential:

Where in plain text:
w_{t} is the weight for an interaction that occurred t time units in the past.
alpha is a decay rate hyperparameter controlling how quickly importance diminishes.
Delta t is the elapsed time since the interaction.
Integrating this into the model can happen in different ways:
Preprocessing Stage Adjust user-song interaction counts by these weights. Then feed the weighted interactions into your collaborative filtering.
Within the Loss Function Multiply the error terms by a time-decay factor so that recent interactions dominate the gradient updates.
Pitfalls
Setting alpha too large can make older feedback almost irrelevant.
Setting alpha too small might ignore ephemeral user moods (e.g., a user binge-listening to a holiday playlist for a week every December).
How can we detect and incorporate negative feedback when a user hardly interacts with recommended songs?
Negative feedback is crucial for refining recommendations. It can be implicitly inferred when a user:
Skips a track within the first few seconds.
Spends significantly less time on a recommended track than their average.
Never revisits or “likes” a track.
Detection
Maintain features like skip_rate or short_playback_ratio.
Use thresholds (e.g., if user listens to only 10% of the track repeatedly, interpret this as negative preference).
Incorporation
Translate negative signals into lower predicted scores in the matrix factorization or neural model.
Adjust item-user embeddings so that disliked tracks shift away from the user’s preference region in latent space.
Pitfalls
Not all skips are negative. Sometimes a user is simply exploring or looking for a specific track.
Minimal or ambiguous data can lead to over-penalizing certain songs.
How do we tune hyperparameters for a large-scale recommendation model?
Hyperparameter tuning in large recommender systems is challenging because of massive dataset sizes and high-dimensional embeddings:
Automated Tools Tools like Bayesian optimization, Population Based Training, or advanced hyperparameter frameworks can reduce the human effort required for searching.
Offline vs. Online Trade-off Conduct offline experiments using a representative subset or a stratified sampling of the dataset to accelerate hyperparameter exploration. Then validate top candidates through partial rollouts or A/B tests.
Layered/Stage-wise Tuning For very large pipelines, you can tune each module (e.g., embedding dimension, learning rate, regularization) in stages rather than jointly. Start with the collaborative filtering parameters, then proceed to the content-based embedding hyperparameters, then the final fusion.
Pitfalls
Overfitting to offline metrics might not reflect real user behavior online.
Very large hyperparameter spaces require extensive compute resources.
What strategies can we use to embed huge catalogs of audio content efficiently?
When dealing with tens of millions of tracks, naive extraction of feature vectors (e.g., from raw waveforms) can be extremely expensive:
Preprocessing Pipeline Employ a distributed system (e.g., Spark or a cloud-based pipeline) to process audio in batches. Consider caching intermediate spectrogram transformations.
Pre-trained Embeddings Use a CNN or transformer-based audio embedding model pretrained on large audio datasets, then fine-tune or directly apply these embeddings.
Incremental Updates For newly added tracks, batch them in incremental jobs rather than re-running the entire pipeline. Store old embeddings in an efficient feature store.
Pitfalls
Embedding drift if your model distribution changes frequently.
Potential mismatch between general audio embeddings and specialized domain nuances (e.g., niche music genres).
How can we address user privacy concerns in a personalized recommendation system?
User data can be sensitive, so it is crucial to implement measures that respect privacy:
Data Anonymization/Pseudonymization Replace direct user identifiers with hashed IDs or random tokens to reduce the risk of data leaks.
Federated Learning Instead of collecting user data in a central repository, models can be trained locally on the user’s device and only model updates (not raw data) are aggregated on the server.
Differential Privacy Inject carefully calibrated noise in user interaction data to ensure that no single user’s preferences are easily extractable from aggregated statistics.
Pitfalls
Over-encryption or strong anonymization can degrade model quality.
Regulatory complexities (GDPR in Europe, CCPA in California) impose constraints on data usage and retention.
What measures can be taken to mitigate bias against certain artists or user groups in the system?
Recommendation systems can inadvertently propagate popularity biases or marginalize underrepresented artists:
Fair Ranking Algorithms Add constraints ensuring equal opportunity or exposure for items from different demographic groups. A re-ranking step can enforce parity in results.
Diversity Boosting Integrate a diversity objective in the scoring function so that the final playlist includes a range of artists, genres, or styles.
Active Discovery Surface lesser-known artists that align with a user’s tastes at slightly elevated positions to encourage exploration.
Pitfalls
Over-correcting can lead to recommendations that are too far from the user’s original preferences, harming engagement.
Lack of high-quality metadata can make it difficult to identify content that requires fairness interventions.
How do we gauge if a user is satisfied with their recommendation if they do not explicitly interact with 'like' or 'dislike' buttons?
Not all platforms or users provide explicit feedback. So the system relies on:
Implicit Engagement Metrics Time spent listening, frequency of replays, skipping behavior, or partial listens. More continuous plays suggest higher satisfaction.
Session Metrics If a user remains in the same playlist or frequently returns to a curated mix, it indicates approval. If they bounce quickly, it might signal dissatisfaction.
Surveys or Micro-Prompts Occasionally presenting quick rating prompts (e.g., “How do you like this selection?”) can supplement implicit signals with direct user opinions.
Pitfalls
Inactivity might reflect a user stepping away, not necessarily dissatisfaction.
Users might passively accept recommendations without meaning they actually enjoy them.
How do we handle label noise or incomplete data in the training pipeline?
Real-world data often contains inaccuracies (e.g., mislabeled genres, incomplete plays logged due to network issues):
Data Cleaning & Validation Implement integrity checks and consistency rules, such as removing impossible playback durations or contradictory user logs.
Robust Loss Functions Instead of a standard mean squared error, consider loss functions less sensitive to outliers or adopt ranking-based losses that naturally mitigate some noise.
Imputation Techniques Where data is missing (e.g., missing metadata fields), you can rely on average or default values. For user history, you might try matrix completion algorithms or learned embeddings for unknown attributes.
Pitfalls
Over-imputation can introduce biased signals.
Discarding all incomplete data might cause the system to miss important edge cases.
What can we do if the user experiences 'recommendation fatigue' or feeling of being overwhelmed by suggestions?
Some users might feel that the playlist is too large or is refreshed too frequently:
Playlist Size Optimization Limit weekly playlists to a manageable number of new tracks, ensuring a well-curated selection rather than hundreds of possibilities.
Adaptive Refresh Interval Tailor the update frequency to each user’s activity. Highly active users might appreciate frequent updates, whereas less active users might benefit from a more static list for a while.
Tiered Recommendations Provide a "core" set of highly relevant songs plus optional "expand" sections for adventurous users seeking deeper exploration.
Pitfalls
Too few suggestions may miss out on user interests.
Frequent updates can disrupt a user who wants to revisit last week’s discoveries if not properly archived or saved.