
ML Interview Q Series: How can Principal Component Analysis be leveraged to identify anomalies in a dataset?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Principal Component Analysis (PCA) is a technique that reduces dimensionality by projecting data onto the directions of maximum variance. In anomaly detection, the core idea is that normal data points can be effectively reconstructed using the principal components that capture most of the variance, whereas anomalous points often show large reconstruction errors.
Dimensionality Reduction and Reconstruction
PCA finds a reduced set of orthogonal axes (principal components) aligned with the directions of greatest variance in the data. This is achieved by:
Subtracting the mean from each feature.
Computing the covariance matrix of the centered data.
Performing eigenvalue decomposition of this covariance matrix to identify eigenvectors (principal components) and their corresponding eigenvalues (variances explained by each principal component).
Once we have identified a sufficient number of top principal components that explain a high proportion of the variance, any data point x can be approximated by projecting x onto this lower-dimensional subspace and then reconstructing it back to the original space.
Reconstruction Error
A common approach to detect anomalies with PCA is to compute the reconstruction error for each data point. A high error indicates that x is not well represented by the low-dimensional subspace of principal components, suggesting it may be anomalous. The reconstruction error for a data point x can be expressed with the following formula:
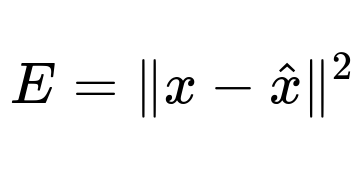
Here E is the reconstruction error, x is the original data point, and x_hat is the reconstructed data point obtained by projecting x onto the selected principal components and then mapping back to the original feature space. The norm is typically the Euclidean norm (L2 norm).
If E exceeds a chosen threshold, the data point is flagged as an outlier or anomaly. This threshold can be determined via domain knowledge, statistical distribution of errors in the training set, or percentile-based methods (for instance, flagging the top 1% of reconstruction errors).
Choosing the Number of Principal Components
Selecting the right number of principal components is crucial. Keeping too few components might cause normal points to have large reconstruction errors (raising false alarms). Keeping too many could reduce the distinctiveness of anomalies since almost every data point can be reconstructed accurately. Practitioners often use the cumulative variance explained ratio to decide how many principal components are sufficient.
Simple Python Example
import numpy as np
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Sample data generation
np.random.seed(0)
X_normal = np.random.randn(100, 5)
X_anomaly = np.array([[10, 10, 10, 10, 10]]) # A single anomalous point
X = np.vstack((X_normal, X_anomaly))
# Standardize features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Fit PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# Reconstruct using PCA
X_reconstructed = pca.inverse_transform(X_pca)
# Compute reconstruction errors
errors = np.mean((X_scaled - X_reconstructed)**2, axis=1)
# A simple threshold approach
threshold = np.percentile(errors, 95) # 95th percentile
anomalies = np.where(errors > threshold)[0]
print("Anomaly indices:", anomalies)
In the above code, we reduce the dimensionality of the data to two principal components, reconstruct the data from these two components, and compute a reconstruction error. Points whose reconstruction errors exceed the threshold are deemed anomalies.
Practical Considerations
One must be mindful of scaling, as PCA is sensitive to differences in variance among features. Normalizing or standardizing all features before applying PCA is usually recommended. Additionally, if the data contain a large number of outliers, they can distort the principal components. Robust PCA variants or methods that diminish the influence of outliers may be used in such scenarios.
What If the Data Has Seasonal Patterns?
Seasonal or time-dependent patterns can complicate PCA-based anomaly detection. If each feature exhibits strong periodic behavior, applying standard PCA might not capture temporal shifts well. One solution is to incorporate time lags or engineered features that account for seasonality, then apply PCA on these transformed features.
How Do We Interpret Anomalies Using Principal Components?
Interpreting anomalies involves understanding how they deviate from normal data in the subspace spanned by principal components. By analyzing which principal components contribute the most to the reconstruction error, one can glean insights into which features or combination of features are unusual for the flagged anomaly.
Could We Use Lower Variance Components for Anomaly Detection Instead?
Yes. While many standard approaches use the high-variance components to reconstruct data, sometimes anomalies stand out in directions of small variance. Specifically, anomalies can have minimal contribution in principal components with high variance but large projection along principal components with low variance. Thus, some algorithms focus on reconstruction within the subspace spanned by principal components that exclude the smallest-variance components, or they monitor the magnitude of projection onto those smallest-variance components directly.
How Does One Determine a Good Threshold for Anomalies?
Threshold determination can be achieved statistically by examining the distribution of reconstruction errors on a validation set, then picking a percentile (like 95th or 99th percentile) or using a confidence interval if the errors roughly follow a known distribution. Domain knowledge is often used to refine this threshold.
Why Might Robust PCA or Other Methods Be Used?
In real-world cases with heavy-tailed distributions or contaminated data, traditional PCA can be sensitive to outliers that affect the covariance structure. Robust PCA and similar techniques reduce the impact of outliers. These methods either use robust estimators for the covariance matrix or perform iterative minimization of an objective function penalizing large deviations.
How Does PCA-Based Anomaly Detection Scale to Very Large Datasets?
For large-scale problems, computing the covariance matrix and performing full eigenvalue decomposition can be expensive. Incremental PCA, randomized PCA, or approximate methods can be used to handle high-dimensional data in a scalable manner. These approaches offer trade-offs in terms of precision of principal components versus computational efficiency.
Below are additional follow-up questions
How does PCA-based anomaly detection handle highly correlated features and multicollinearity?
If the dataset exhibits strong correlations or multicollinearity among features, PCA effectively exploits that redundancy by finding directions (principal components) that capture the shared variance. In the presence of perfectly correlated features, PCA merges them into fewer principal components without losing important information. This can be advantageous because:
It reduces dimensionality: Instead of dealing with many correlated features, the model works with a smaller, more compact representation.
It improves computational efficiency: Fewer components often mean faster downstream processing for anomaly detection.
It can enhance interpretability of anomalies (in some cases): By examining which original features contribute to a principal component, you can spot common patterns among correlated variables.
A subtle pitfall arises if the correlation structure changes at prediction time. PCA is computed on the training data covariance structure, so if real-world changes break the correlations (e.g., new operating conditions or sensor failures in an IoT scenario), the anomaly detection logic might become less reliable. To mitigate this, you can periodically retrain or update PCA with the most recent data so that the correlation structure remains relevant.
What is the best way to adapt PCA-based anomaly detection for streaming data?
When data arrive continuously in a stream, it is often impractical to perform a full PCA from scratch on each new batch because the covariance matrix and the eigenvalue decomposition can be computationally expensive. Two strategies commonly employed are:
Incremental PCA: This approach updates an existing PCA model with new data by incrementally approximating the covariance matrix and principal components. It avoids storing the entire dataset in memory, making it better suited for large or streaming scenarios. However, it relies on iterative updates that maintain an approximation of the principal components.
Windowing or Rolling PCA: You can maintain a fixed-size window of the most recent data and recalculate PCA periodically. This ensures the model remains responsive to recent data trends. A challenge here is choosing an appropriate window size: too small and you risk losing long-term structure, too large and you lose responsiveness to recent changes.
In both cases, the key pitfall is deciding how often to update the PCA model and ensuring that abrupt distribution shifts do not render the current components obsolete. If you detect significant drift in the data distribution, a faster or immediate re-computation of PCA might be necessary.
How can missing data be handled in PCA-based anomaly detection?
Missing data in any feature can hinder the computation of covariance matrices. Several approaches exist:
Imputation Before PCA: Use statistical or model-based methods (e.g., mean imputation, KNN-based imputation, or more sophisticated approaches) to fill missing entries. Then apply PCA on the completed dataset. However, this can introduce biases if the missingness pattern is not random.
Probabilistic PCA or EM-based PCA: These variations model the data using a probabilistic framework. They can iteratively estimate missing values as part of the PCA process, often using the Expectation-Maximization algorithm. This may produce more accurate reconstructions than naive imputation methods.
Ignore Incomplete Samples: In some scenarios, you might discard records with missing values. This only works if the proportion of incomplete data is very small. Otherwise, you risk losing valuable information or introducing bias.
A major pitfall is ignoring the mechanism behind missingness. If data are missing not at random (MNAR), then a naive approach might systematically underestimate or overestimate certain directions of variance, adversely affecting anomaly detection.
In what situations might PCA-based anomaly detection fail to catch anomalies?
Non-Linear Structure: PCA is a linear method. If the normal behavior of the dataset lies on a non-linear manifold, PCA might fail to capture that structure accurately. Consequently, certain anomalies that deviate non-linearly could remain undetected.
Anomalies Aligned with High Variance Directions: Sometimes, an anomaly happens to lie along a direction with large variance. Because the principal components prioritize directions of greatest variance, this anomalous point might not produce a high reconstruction error.
Highly Disparate Feature Scales: If you do not scale or normalize features properly, PCA might overweight features with large variances, obscuring anomalies that manifest in other features with smaller variances.
Too Many Principal Components Retained: Retaining too many components can lead to almost perfect reconstruction of all points, making it difficult to separate anomalies from normal points.
Why might we sometimes avoid feature scaling or use alternative scaling strategies?
Feature scaling is usually recommended for PCA because large-scale features dominate the variance. However, in certain domains, you might deliberately avoid it or use different scaling strategies because:
Domain-Specific Importance: Some features, by domain knowledge, genuinely have a larger scale and are more important to the anomaly detection process. Uniformly scaling them down might weaken their influence.
Sparse or Binary Features: When dealing with categorical indicators or binary vectors (e.g., presence or absence of events), standard scaling might not be meaningful. Instead, specialized transformations or no scaling at all can be used.
Robust Scaling: If outliers are prevalent, standard normalization (subtract mean, divide by standard deviation) might be overly sensitive. Alternative scalers (e.g., RobustScaler in scikit-learn) using medians and interquartile ranges are sometimes preferred to reduce distortion from outliers.
The key pitfall is not validating the impact of your chosen scaling method on anomaly detection performance. A mismatch can lead to overlooked anomalies or false positives.
How does the choice of distance metric for reconstruction error affect anomaly detection results?
The standard approach uses the L2 norm (Euclidean distance) to measure reconstruction error. However, other norms or distance metrics can be used:
L1 Norm: More robust to outliers in the sense that it penalizes large deviations less aggressively. But it might not capture small, distributed errors as effectively as L2.
Mahalanobis Distance: This considers the covariance structure among features. It can be appropriate if some features are highly correlated, though it introduces additional complexity in estimating the covariance matrix (and can be redundant if you have already done PCA).
Cosine Similarity: Sometimes used for text or very high-dimensional data, focusing on directional alignment rather than magnitude differences.
The main pitfall in selecting a distance metric is misalignment with the actual notion of “anomalous.” For instance, if you only care about large magnitude deviations, the L2 norm might be suitable. If you care about directional differences, some angle-based measure is more appropriate.
Why might we consider an autoencoder instead of PCA for anomaly detection?
An autoencoder is a neural network that learns a non-linear transformation for dimensionality reduction. There are scenarios in which autoencoders can outperform PCA:
Non-Linear Patterns: PCA is linear, while autoencoders can capture complex, non-linear manifolds using hidden layers and activation functions. This is beneficial for data where normal behavior is not primarily linear.
Feature Learning: Autoencoders can learn higher-level representations that are more expressive than the principal components in some domains (e.g., images or text).
Scalability and Performance: With GPU acceleration and the ability to handle very large datasets in mini-batches, autoencoders can sometimes be more scalable, although training might require more hyperparameter tuning.
The pitfall with autoencoders is that they require careful architecture selection, hyperparameter tuning, and more computational resources. Overfitting is also a risk if the autoencoder simply memorizes the training data, which can artificially lower reconstruction errors for both normal and anomalous points.
How does PCA-based anomaly detection compare to methods like Isolation Forest or Local Outlier Factor?
Isolation Forest: Focuses on isolating outliers by creating random splits. It does not require an explicit distance or density measure. This can be highly effective for high-dimensional datasets and is robust to non-linear relationships. However, it might not offer the same interpretability regarding principal components or reconstruction.
Local Outlier Factor (LOF): Estimates local density deviations. Anomalies are points whose local density is significantly lower than that of their neighbors. LOF works well for capturing local patterns, but it can struggle with very high-dimensional data or large datasets due to complexity.
PCA: Offers a global, variance-based view of normal vs. anomalous data. It is computationally relatively straightforward up to moderate dimensionality, but less effective for highly non-linear scenarios or local anomalies.
A common pitfall is blindly applying one method without considering the data’s characteristics (dimensionality, linearity, distribution). Combining PCA-based reconstructions with other outlier detection algorithms can yield more robust results if the dataset is heterogeneous.
How does lack of interpretability of principal components impact the real-world usage of PCA-based anomaly detection?
In regulated industries (e.g., finance, healthcare), stakeholders often require clear explanations of why a data point is flagged as anomalous. PCA’s linear transformations can sometimes be partially interpretable by examining the loadings (coefficients) in each principal component. However:
Loadings Can Be Hard to Explain: A principal component might be a combination of dozens or hundreds of original features. Explaining that combination is not always straightforward for stakeholders.
Business Accountability: If an anomaly triggers an investigation or an automated decision, the organization might need to justify it. PCA alone may not suffice unless you augment it with feature-level analysis or domain-relevant visualizations.
A pitfall is the mismatch between technical feasibility and regulatory requirements. Some teams use post-hoc explanations (like analyzing feature contributions to reconstruction error) or combine PCA with domain-meaningful features to maintain interpretability.
How should we handle scenarios where the underlying data distribution evolves over time in unexpected ways?
Data drift or concept drift is common in real-world applications. A static PCA might quickly become obsolete if the distribution shifts. Approaches to address this include:
Periodic Retraining: A simple strategy where PCA is periodically recalculated using a rolling window or incremental updates. This ensures that the principal components adapt to gradual shifts in the data distribution.
Online PCA with Drift Detection: More sophisticated techniques track distributional changes in real time. If a significant drift is detected, the PCA model is reset or updated more aggressively.
Hybrid Strategies: You might maintain multiple PCA models, each specialized for certain known regimes, and then dynamically select which model to use based on real-time conditions or contextual signals.
A pitfall is failing to detect subtle or gradual shifts that accumulate over time, so the PCA model slowly drifts out of touch. Thorough monitoring of reconstruction errors and other metrics can help identify when the model needs updating.