
ML Interview Q Series: How can we interpret the linear system Ax = b, and under what circumstances does it possess a single unique solution?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Understanding Ax = b
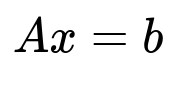
In this system, A denotes a matrix (usually of dimension m x n), x is a column vector of size n, and b is a column vector of size m. The equation represents m linear equations in n unknowns. Each row of A corresponds to the coefficients of one linear equation, and each component of b corresponds to the right-hand side constant of that equation.
The goal is to find a vector x that satisfies all these linear equations simultaneously. If we interpret A as a transformation that maps the vector space of possible x vectors to some output space, then Ax = b means we want to find an x whose image under the transformation A is exactly b.
Condition for a Unique Solution
When A is a square n x n matrix and has full rank (rank(A) = n), it is invertible. In that case, the system has exactly one solution given by:

Here, A^{-1} is the inverse of A. The determinant of A in this scenario is non-zero, which equivalently means that the rows of A (or columns of A) are linearly independent.
If A is not square (for example, m > n or m < n), uniqueness depends on whether rank(A) equals the number_of_columns(A). Specifically:
If rank(A) = number_of_columns(A) and m >= n, the system typically has a unique solution.
If rank(A) < number_of_columns(A), the system can either have infinitely many solutions (if rank(A) = rank(A|b)) or no solution (if rank(A) < rank(A|b)).
Geometric Intuition
The rows (or columns) of A span a certain subspace of the vector space. For Ax = b to have a unique solution:
The rank of A must be maximal with respect to the dimension of x.
b must lie in the column space of A.
There must be no redundancy among the columns of A, ensuring that no two distinct x vectors produce the same b.
When these conditions are satisfied, the linear mapping from x to b is one-to-one and onto the relevant subspace, giving us exactly one solution.
Common Pitfalls and Edge Cases
Degenerate Matrices
If A is singular (for square A, det(A) = 0), or rank(A) < n, then either no solutions or infinitely many solutions can exist. One must check consistency (i.e., if b is in the column space of A).
Overdetermined and Underdetermined Systems
Overdetermined (m > n): There can be no solution if the rank condition is not met. Otherwise, there might be a unique solution (though typically in practice, a least-squares solution is found if an exact solution does not exist).
Underdetermined (m < n): Typically there could be infinitely many solutions unless additional constraints are imposed.
Numerical Stability
Even if a matrix is theoretically invertible, in practice, floating-point computations may cause inaccuracies. For large matrices, we often use numerical techniques (like QR decomposition or SVD) to solve Ax = b robustly.
Follow-up Questions
Can you discuss the link between matrix rank and the uniqueness of solutions in more depth?
The rank of a matrix A (rank(A)) is the dimension of its column space (or equivalently, row space). If rank(A) = n (where n is the number_of_columns(A)), then all columns of A are linearly independent. This implies:
There is no redundancy in how each column can be expressed as a linear combination of the others.
For any vector b in the column space, there is precisely one way to combine those columns to obtain b.
When A is square (n x n) and rank(A) = n, we know A is invertible, thus guaranteeing a single unique solution.
In contrast, if rank(A) < n, some columns can be written as linear combinations of others, meaning multiple x vectors can produce the same output (leading to infinitely many solutions) or, in certain cases where b lies outside the column space, no solutions exist.
If the matrix A is not square, how do we handle Ax = b for a unique solution?
When A is rectangular, there are two common scenarios:
m > n (more equations than unknowns). This is overdetermined. A necessary condition for a unique solution is rank(A) = n. In that situation, A has linearly independent columns, so if b is in the span of those columns, the solution is unique.
m < n (fewer equations than unknowns). This is underdetermined. Even if rank(A) = m, typically there can be infinitely many solutions because we have more unknowns than equations. A single solution might be singled out by imposing additional constraints (like minimizing the L2 norm of x).
What techniques are commonly used to find the solution in large-scale or non-invertible scenarios?
For large-scale systems or cases where A is non-square:
QR Decomposition: Particularly effective for solving least-squares problems (overdetermined systems).
Singular Value Decomposition (SVD): Provides insight into the rank and can handle ill-conditioned or rank-deficient matrices.
Moore-Penrose Pseudoinverse: Used to find a least-squares solution, often giving a minimum-norm solution when the system is underdetermined.
In Python, libraries like NumPy, SciPy, and frameworks such as PyTorch or TensorFlow provide built-in methods (like numpy.linalg.lstsq) to find solutions or approximate solutions depending on the system type.
How do we handle the possibility of no solution versus infinitely many solutions?
The Rouché–Capelli theorem tells us that a solution exists if and only if rank(A) = rank(A|b). Here, (A|b) denotes the augmented matrix formed by appending b as an extra column to A. If rank(A) < rank(A|b), no solution exists (inconsistent system). If rank(A) = rank(A|b) but rank(A) < number_of_columns(A), there are infinitely many solutions. If rank(A) = rank(A|b) = number_of_columns(A), there is a unique solution.
How is this relevant in Machine Learning or Deep Learning?
Many learning algorithms fit parameters by solving systems of linear equations or by using techniques from linear algebra:
Linear Regression: Often framed as solving (X^T X)w = X^T y for the weight vector w.
Optimization Algorithms: Iterative methods like gradient descent often involve inverting the Hessian or approximations to solve normal equations efficiently.
Neural Networks: Though typically not about directly solving Ax = b, numerical stability and invertibility concepts are still relevant, for instance, in certain layers or transformations.
These fundamentals underlie how we handle parameter estimation and model training, ensuring we either have a well-defined solution or adopt approximate methods (like regularization) when the system is ill-posed.