
ML Interview Q Series: How can we scale model training to handle Netflix's millions of titles and users in a recommendation system?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
A large-scale recommender system typically involves two main computational challenges. The first is the sheer volume of user-item interactions (for Netflix, millions of subscribers and millions of movies or shows). The second is the high dimensionality of the user and item feature spaces. Scaling requires strategies to efficiently manage memory usage, computational load, and distributed resources, all while maintaining model accuracy.
Many recommender systems rely on matrix factorization or deep learning–based approaches. Matrix factorization methods often factorize the user-item interaction matrix into lower-dimensional latent factors, which is computationally lighter once trained. Deep learning methods can capture more complex interactions but require careful architectural choices and infrastructure for distributed training. In both cases, the training framework needs to handle large mini-batches and frequent parameter updates across potentially thousands of compute nodes or GPUs.
One of the most commonly cited approaches for classic collaborative filtering is to minimize the sum of squared errors between the predicted user-item rating and the actual rating, along with some regularization. In matrix factorization, this objective function can be expressed as follows:
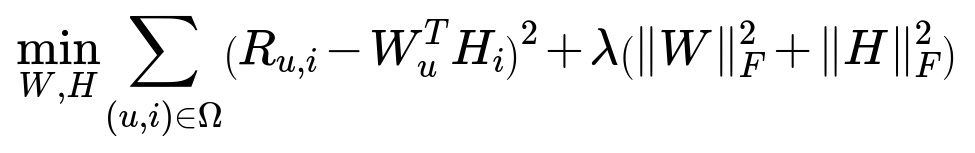
Here:
R is the user-item rating matrix, where R_{u,i} in plain text format is the rating from user u to item i.
W is a matrix of user latent factors, with each row representing the latent features of a user.
H is a matrix of item latent factors, with each row representing the latent features of an item.
lambda is the regularization hyperparameter controlling overfitting.
Omega is the set of (user, item) pairs for which ratings are known.
||·||_F denotes the Frobenius norm, summing the squares of all entries in a matrix.
When scaling to the entire Netflix dataset, storing all user and item vectors as well as computing large gradients must be parallelized or distributed.
Distributed Data Storage and Computation
One key step is to partition both the user matrix and the item matrix across different compute nodes. This can be done in many ways. An example is to split users among different nodes so that each node only stores and updates a subset of user latent factors, while items can be stored in a central parameter server or also partitioned across nodes. For deep learning methods, frameworks like TensorFlow Distributed or PyTorch Distributed Data Parallel automatically handle gradient communication and synchronization across GPUs or machines.
Mini-Batch Training and Sampling
Mini-batch training is standard practice. Rather than loading all user-item interactions at once, the data is broken into manageable batches, each processed independently to compute gradients. With large recommender systems, negative sampling is also common for implicit feedback tasks; the model sees explicit or implicit feedback for positive interactions and a set of randomly sampled negative interactions.
Parallelization and Asynchronous Updates
In large-scale scenarios, asynchronous or semi-synchronous updates can speed up training. This happens when different workers compute updates on their local mini-batch, then periodically synchronize with a parameter server or through all-reduce operations. This approach helps the system not to idle waiting for a slow node. However, asynchronous methods can lead to gradient staleness, which must be managed through careful design (e.g., limited asynchronous steps or fast network interconnects).
Memory Efficiency Techniques
With millions of users and items, memory usage can explode if each user and item has a large latent dimension. Strategies to reduce memory footprints include choosing smaller embedding dimensions, pruning unimportant features, or using quantization. For many deep recommendation models (like wide and deep networks or autoencoder-based models), more sophisticated architectural tweaks such as factorized embeddings or hashing can keep the parameter size manageable.
Handling Data Pipelines
When training on massive datasets, data loading and preprocessing can become a bottleneck. Systems like Apache Spark can be used to create efficient pipelines. The preprocessed data can be streamed into a distributed deep learning framework, reducing the time from data ingestion to training. Consistent shuffling and partitioning strategies help maintain good load balancing across nodes.
Example Using PyTorch Distributed Data Parallel
Below is an illustrative Python code snippet that outlines how distributed data parallel (DDP) can be used in PyTorch to train a simple recommender model at scale. This snippet is a conceptual example and not a fully functional end-to-end system:
import os
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def init_distributed_process(rank, world_size, backend='nccl'):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group(backend, rank=rank, world_size=world_size)
class MFModel(torch.nn.Module):
def __init__(self, num_users, num_items, embedding_dim):
super(MFModel, self).__init__()
self.user_emb = torch.nn.Embedding(num_users, embedding_dim)
self.item_emb = torch.nn.Embedding(num_items, embedding_dim)
def forward(self, user_indices, item_indices):
user_vectors = self.user_emb(user_indices)
item_vectors = self.item_emb(item_indices)
preds = torch.sum(user_vectors * item_vectors, dim=1) # Dot product
return preds
def main(rank, world_size, data_loader):
init_distributed_process(rank, world_size)
device = torch.device(f'cuda:{rank}' if torch.cuda.is_available() else 'cpu')
num_users = 1000000
num_items = 500000
embedding_dim = 64
model = MFModel(num_users, num_items, embedding_dim).to(device)
ddp_model = DDP(model, device_ids=[rank])
optimizer = torch.optim.Adam(ddp_model.parameters(), lr=0.001)
loss_fn = torch.nn.MSELoss()
for user_batch, item_batch, rating_batch in data_loader:
user_batch = user_batch.to(device)
item_batch = item_batch.to(device)
rating_batch = rating_batch.to(device)
optimizer.zero_grad()
predictions = ddp_model(user_batch, item_batch)
loss = loss_fn(predictions, rating_batch)
loss.backward()
optimizer.step()
dist.destroy_process_group()
# In practice, you'd launch multiple processes (one per GPU) that all run main(...).
This kind of distributed setup is crucial when dealing with a massive number of users and items, as it leverages multiple GPUs or machines to simultaneously process different parts of the data and update shared model parameters.
Follow-Up Questions
How would you address cold start issues when new users or items appear in such a massive system?
Cold start problems arise when the model has little or no data about a new user or a new item. One technique is to incorporate side information or metadata about users or items, such as user demographic information or item genres, to generate initial embedding vectors. Another approach is to train a hybrid model that fuses collaborative filtering (learning from user-item interactions) with content-based methods (learning from item or user attributes). In real-world production, strategies like prompting new users with a short survey or questionnaire can bootstrap user profiles more quickly.
What techniques can be used when the data is sparse, and most user-item interactions are unobserved?
Data in large recommenders often has extreme sparsity. Negative sampling is a common approach for implicit feedback tasks, selecting items users did not interact with as “negative” examples. Matrix factorization naturally handles sparse matrices well, since only known ratings are used in the loss function. Other methods include using graph-based approaches or factorization machines that can better capture interactions among sparse features. Dimensionality reduction and embedding-based methods also help mitigate the effect of sparse data, as the latent factors represent dense summaries of user-item relationships.
How do you handle distributed hyperparameter tuning for massive recommenders?
Hyperparameter tuning in large-scale scenarios can be done using distributed hyperparameter search frameworks such as Ray Tune or Optuna. Each hyperparameter configuration is launched as a separate training job. Techniques like population-based training or Bayesian optimization can be used to guide the search toward better configurations. It is also common to combine distributed hyperparameter tuning with early stopping if a configuration’s performance plateaus quickly to save compute resources.
What if the system needs real-time recommendations during training?
Real-time recommendations require frequent updates of the model parameters to reflect the latest interactions. This can be achieved using online learning or streaming approaches, where mini-batches are formed from recent user activity, and parameters are incrementally updated. Systems like parameter servers or streaming platforms allow near real-time model refreshes. However, there is a trade-off between model freshness and system complexity—high-frequency updates can require a sophisticated pipeline to avoid user-visible latency issues.
How do you prevent overfitting and ensure that the model generalizes well on such large data?
Regularization, dropout (in the case of deep neural networks), and carefully selected embedding sizes are crucial. Cross-validation on separate user groups or item subsets can help detect overfitting. In practice, large datasets can sometimes reduce overfitting but raise computational and data pipeline complexities. Proper hyperparameter tuning, early stopping, and using scaled batch normalization (in deep models) are standard practice to ensure balanced generalization.
How do you monitor training convergence and performance at scale?
Monitoring requires both offline and online metrics. Offline, you might periodically measure root mean square error, mean average precision, or other metrics on a validation set. Online, Netflix-like platforms rely heavily on A/B testing, evaluating whether a new model improves retention or watch time. Large-scale logging and analytics systems ingest interactions in near real-time, providing dashboards and alerts that detect performance drops. Distributed logging frameworks that can handle billions of events per day are often used, and integrated with the training system to track model convergence or divergence.
These methods collectively address the challenges of training and deploying recommendation models when confronted with the scale of services like Netflix. By properly partitioning data, choosing distributed frameworks, and incorporating strategies for streaming updates, cold starts, and hyperparameter optimization, it is possible to deliver accurate and efficient recommendations to millions of users.
Below are additional follow-up questions
How do you ensure user privacy when training on sensitive data such as viewing habits or personal user information?
When dealing with highly sensitive user data, regulations and user trust considerations become paramount. One strategy is differential privacy, which adds noise to model updates or data points so that individual user records are anonymized. For matrix factorization or deep models, this can be achieved by injecting small amounts of noise to gradients during backpropagation, limiting how much information about a single user can leak out.
Federated learning is another possibility. Instead of aggregating user data on a central server, you can train local models directly on the user’s device, and only transmit aggregated gradients to a central orchestrator. This reduces exposure of raw data. However, challenges include dealing with unreliable or resource-constrained devices, unbalanced data distribution across users, and higher complexity of deployment.
A practical pitfall is forgetting that even pseudonymized user IDs can sometimes be re-identified with auxiliary data. Proper sanitization of user-level logs and minimal data retention policies also help reduce risk. Deployment must address encryption in transit and at rest to protect user data from unauthorized access.
How would you handle multi-objective optimization (e.g., maximizing user engagement while also promoting fresh content)?
In real-world systems, objectives often extend beyond predicting ratings or clicks. You might want to balance short-term engagement with long-term satisfaction, or ensure new content is discovered alongside popular titles. One technique involves defining a reward function that combines multiple objectives, such as alpha * short_term_metric + beta * diversity_metric, then tuning alpha and beta to find the right balance.
Another option is to train a multi-head network, where the shared layers learn general representations, and each head focuses on a distinct objective like watch time, content diversity, or novelty. You then combine losses from each head during backpropagation, controlling their relative importance with weights. A subtle pitfall here is that these objectives can compete: optimizing purely for watch time might reduce diversity, or exclusively promoting novelty might hurt short-term engagement if recommendations become too unpredictable.
The best approach typically involves iterative experimentation (e.g., A/B tests) to see which trade-off resonates with users. You also need to be careful when measuring these metrics, as short-term spikes in engagement might come at the cost of user churn down the line if recommendations become too repetitive or fail to reflect user preferences.
How do you handle rapidly shifting user behavior, for instance when a previously obscure show becomes a trending hit?
User interests change over time, and large-scale recommenders must adapt quickly. One approach is to include a time decay or a recency weighting mechanism in the training data, so newer interactions have a stronger influence. For example, you can assign higher weights to interactions from the last few weeks than interactions from months ago.
An alternative is to incorporate near real-time data into the model via incremental or online learning. This might mean updating embeddings or partial model layers on an hourly or daily basis, ensuring that the surge in popularity for a newly trending show is captured rapidly. However, real-time or near real-time updates require robust infrastructure for streaming data ingestion, frequent retraining, and safe model deployment without service interruption.
A potential pitfall is over-reacting to short-term fluctuations, leading to instability in recommendations. A model might prematurely push newly popular items to the top, only to find user dissatisfaction if those items do not have broad appeal. Balancing the responsiveness of the model with stable performance usually involves smoothing or inertia parameters.
How do you address fairness, bias, or diversity considerations in large-scale recommendations?
Fairness can refer to ensuring that content from underrepresented creators is not overshadowed by mass-appeal titles, or that different demographic groups of users receive equally relevant recommendations. A common approach is to extend the loss function to penalize large disparities across user groups. For instance, you might measure the difference in average predicted ratings across demographic segments and apply a fairness penalty term that discourages large mismatches.
Techniques to improve diversity can involve re-ranking strategies, where you first generate a set of candidate recommendations based on predicted relevance, then apply a re-ranking algorithm to ensure a variety of genres or item types. Another option is to incorporate fairness constraints directly in model training, for example using constrained optimization methods that enforce balanced exposure of content.
A pitfall is that fairness is context-dependent and may have multiple interpretations, requiring close collaboration with product managers, legal counsel, and ethicists to define acceptable trade-offs. Implementing fairness also can degrade immediate accuracy metrics, so it becomes an iterative process to find a workable compromise that aligns with the platform’s goals and ethical obligations.
How do you incorporate content-based features or embeddings in a hybrid recommendation approach?
While collaborative filtering relies on user-item interactions, content-based features come from textual descriptions, images, or metadata of the movies or shows themselves. A hybrid system can combine these signals to address cases where user behavior data is sparse. For instance, you can train a neural encoder to transform movie descriptions into content embeddings, then combine these embeddings with the collaborative user and item embeddings.
One method is to concatenate content embeddings with learned item latent factors. Another is to initialize item embeddings by training on content alone, then fine-tune the embeddings with collaborative feedback. Using autoencoder approaches that reconstruct metadata or item descriptors can also embed semantic information.
A subtlety arises in weighting the importance of content embeddings relative to collaborative embeddings. If content signals dominate, the system might fail to capture emergent preferences that are not reflected in the item metadata. On the other hand, ignoring content means you lose the ability to recommend new or niche items that have limited interaction data.
How do you provide explainability or transparency to users in large-scale recommendation engines?
Recommender explainability often involves techniques that highlight key features or user behaviors driving the recommendation. For matrix factorization, you might show which latent factors are most influential, or highlight a set of items that share similarities with the recommended item. In deep learning–based systems, attention mechanisms or feature attribution methods can provide insight into how the network arrived at a particular recommendation.
An approach for user-friendly explanations is to label latent factors post hoc with human-understandable tags. For instance, if factor 12 often correlates with romantic comedies, you can show users a tooltip: “We recommended this because you like romantic comedies.” Another practice is to show items or user actions that heavily contributed to the predicted rating. However, interpretability can be challenging for very deep models, so you may rely on approximate or surrogate models that are more transparent.
A potential pitfall is oversimplification, where the explanation does not accurately reflect the complex underlying model. This can erode user trust if the system appears inconsistent or manipulative. Balancing transparency with model complexity and business secrecy requires careful design of the explanation interface.
How do you manage malicious user actions or spam in massive recommendation systems?
Malicious users can artificially inflate an item’s popularity (e.g., through bot accounts), or deflate competitor items’ perceived quality. Large-scale systems need mechanisms to detect suspicious patterns, such as an unusually high frequency of new user signups that rate one show extremely high or extremely low.
Outlier detection methods, such as measuring rating entropy per user or item, can flag suspicious outliers. You can also maintain a trust score for each user account, lowering the impact of accounts that appear to be bots or exhibit unnatural behavior. In a deep learning context, you might build an auxiliary model to classify suspicious rating patterns or track user embeddings over time to catch abrupt changes in rating style.
A pitfall is that malicious activity can blend into normal user interactions if it is subtle. Too-aggressive filtering might block legitimate emerging trends or penalize enthusiastic users. An ongoing arms race arises as adversaries adapt. Frequent audits, combined with robust anomaly detection and continual retraining, are essential to stay ahead of spam campaigns.
How might reinforcement learning be applied in a large-scale recommender context?
Where user feedback is sequential and each recommendation may affect future engagement, reinforcement learning (RL) can be used to optimize long-term user satisfaction. An RL agent observes user states (e.g., watch history, dwell time, explicit ratings), takes an action (recommends a set of titles), and receives a reward (e.g., watch duration or a rating). Over time, the agent learns a policy that maximizes cumulative reward.
In practice, RL-based recommenders often rely on offline training with historical interaction data, then carefully conduct online tests. Offline training typically involves counterfactual estimation to deal with the fact that historical actions were not chosen by the RL policy. Another trick is to use batch-constrained Q-learning or other offline RL methods that reduce the risk of policy divergence.
A subtle challenge is that fully exploring all content for each user is impractical, raising the risk of suboptimal exploration strategies. RL also may produce unexpected or undesired behaviors, such as “addictive loops” that push content the user can’t stop watching but ultimately leads to dissatisfaction. Balancing user autonomy with RL’s efficiency can be a major design and ethical concern.
How can you handle multi-lingual or region-specific catalogs in a global recommender system?
Global platforms often serve content in multiple languages and have region-specific licensing or cultural preferences. One approach is to partition the user base by region or language and train separate models. However, this can lead to data silos and less knowledge transfer across regions. A more advanced solution is to include language embeddings or region embeddings in the model, letting the recommender learn cross-lingual similarities.
If the content metadata is in multiple languages, you can create universal language representations (e.g., using BERT or multilingual embeddings) to unify titles and descriptions. This allows the recommender to leverage semantic similarities even if items are in different languages. A tricky scenario arises when you have minimal user data for certain languages. Transferring knowledge from high-resource languages to low-resource languages becomes critical, sometimes requiring zero-shot or few-shot adaptation.
A pitfall is ignoring local cultural nuances. Just because two shows share textual similarities in their descriptions does not mean they will be equally appealing in different regions. Incorporating region-specific popularity trends and user feedback in the model helps avoid misguided universal recommendations.
How do you ensure resilience and fault tolerance when training and serving recommendations at scale?
A large-scale recommender might use hundreds or thousands of compute nodes. Failures are inevitable, so the system design must tolerate node outages or transient network issues. Distributed frameworks like Apache Spark or Kubernetes orchestrate retries and rescheduling of failed tasks, while parameter servers or all-reduce strategies often employ checkpoints and replication to preserve model states.
Frequent checkpointing ensures that partial training progress is not lost if a machine crashes. Load balancing and auto-scaling can be employed so that if certain nodes are under strain, new instances come online and share the load. For serving, multiple replicas of the recommendation model run behind a load balancer, so user requests keep flowing smoothly even if one replica goes down.
A hidden pitfall is that naive checkpointing can bloat storage usage and slow down training, especially if done too often. Similarly, poorly designed auto-scaling might spin up too many nodes, leading to high costs and diminishing returns. Fine-tuned parameters for checkpoint intervals and resource usage help strike a balance between fault tolerance and efficiency.