
ML Interview Q Series: How can you handle a Decision Tree that appears to overfit its training data?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
A decision tree tends to overfit when it continues to grow nodes that adapt too closely to the training set, leading to poor generalization. This commonly manifests as excessive depth or a lot of leaf nodes, each capturing very specific details (including noise) in the training set. Strategies to address an overfitted tree revolve around limiting the model’s complexity or trimming its complexity after the full tree has been grown.
Controlling Tree Complexity
One approach is to stop the tree from growing too large by limiting or adjusting certain hyperparameters. Examples include setting a maximum depth, increasing the minimum number of samples required to split an internal node (min_samples_split), or setting a higher minimum samples required for a leaf (min_samples_leaf). These “pre-pruning” methods help ensure that the tree doesn’t become too complex in the first place.
Pruning Methods
Pruning is a post-processing step where an initially grown tree (often fully grown or substantially grown) is systematically reduced in size. The goal is to remove sections that provide little value for predicting on unseen data. Many algorithms evaluate potential subtrees and keep the one that yields the best cross-validated performance or lowest cost.
Cost Complexity Pruning
A commonly used technique is cost complexity pruning (also known as weakest link pruning). In this method, the tree’s “cost” is computed based on its performance on the training set plus a penalty proportional to the number of leaf nodes. This approach is detailed by a function that can be generally written as follows:
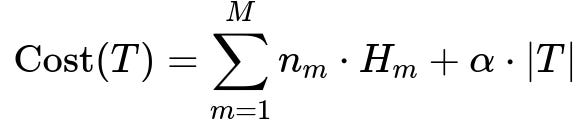
Here:
n_m is the number of training samples in the mth leaf.
H_m is the impurity measure for that leaf (for example, Gini impurity or entropy).
|T| is the total number of leaves in the tree T.
alpha is a parameter that controls how strongly the tree size is penalized. Larger alpha leads to more pruning.
The algorithm finds a sequence of subtrees T_1, T_2, …, T_k, each corresponding to different alpha values, and typically uses cross-validation to pick the alpha that yields the subtree with the best generalization.
Gathering More Data
If feasible, adding more training samples can often mitigate overfitting. A tree that initially memorizes nuances may learn more general decision boundaries if the training set is broadened or made more representative of the entire data distribution.
Ensemble Methods
A highly effective way to prevent a single decision tree from overfitting is to use ensemble methods such as Random Forests, Bagging, or Gradient Boosting. Random Forests, for instance, build multiple trees on bootstrapped subsets of the data with feature subsampling, thereby reducing variance. Bagging averages across many trees to stabilize predictions, while boosting combines many weak learners in a sequential manner to improve performance.
Example in Python
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.datasets import load_iris
# Load a simple dataset
X, y = load_iris(return_X_y=True)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a Decision Tree with certain pre-pruning parameters
tree = DecisionTreeClassifier(
max_depth=5,
min_samples_leaf=3,
ccp_alpha=0.01 # cost complexity pruning (post-pruning parameter)
)
tree.fit(X_train, y_train)
# Evaluate performance
scores = cross_val_score(tree, X_train, y_train, cv=5)
print("Cross-validation accuracy:", scores.mean())
val_accuracy = tree.score(X_val, y_val)
print("Validation accuracy:", val_accuracy)
In the above code, ccp_alpha is the cost-complexity parameter that prunes the tree after it has grown. By tuning these parameters (max_depth, min_samples_leaf, ccp_alpha) through methods like grid search, you can reduce overfitting.
Are there specific hyperparameters you typically tune to avoid overfitting in decision trees?
The most common hyperparameters include:
max_depth: Caps the depth. A smaller value reduces complexity.
min_samples_split: Requires a minimum number of samples to perform a split. A larger value prevents too many splits.
min_samples_leaf: Enforces a minimum number of samples in each leaf. This avoids leaves that only represent very few data points.
max_leaf_nodes: Restricts the number of leaf nodes.
ccp_alpha: The pruning parameter for cost complexity pruning.
These hyperparameters help constrain the tree’s capacity to memorize the training data by preventing overly specific splits and extremely deep branches.
How do you decide which pruning method to use in practice?
In many modern libraries, cost complexity pruning is conveniently integrated, making it a straightforward choice. Some practitioners prefer “pre-pruning” methods (like limiting depth) because they are easy to set up and tune. Others prefer a two-step approach: grow a somewhat large tree, and then use a pruning criterion (like cost complexity or a validation set) to find an optimal subtree. In practice, you often rely on cross-validation or a hold-out validation set to decide which approach gives the best balance between training accuracy and generalization.
Are ensemble methods always better for avoiding overfitting?
Ensemble methods, especially Random Forests, often reduce overfitting dramatically because they aggregate the predictions of many diversified trees. However, ensembles can be more computationally expensive. If your data is large and speed is a concern, a single pruned decision tree might be more suitable. Additionally, ensembles can sometimes obscure interpretability because you lose the transparent, easily visualizable structure of a single tree. So while ensembles typically perform better in resisting overfitting, the choice depends on your performance goals, interpretability needs, and computing constraints.
Could we apply cross-validation in combination with pruning?
Yes. Cross-validation is a powerful way to determine the best pruning parameter alpha (in cost complexity pruning) or to find the best constraints for the tree. By using cross-validation error as a guide, you can systematically compare different values of alpha (and other hyperparameters) to see which balance between complexity and accuracy gives the best generalization on unseen data. This approach ensures that you’re not tuning your pruning parameters just to fit the training set but to optimize performance across multiple folds of data.