
ML Interview Q Series: How do Bagging and Boosting methods differ in the field of ensemble learning?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Bagging is a method in which multiple models (often decision trees) are trained in parallel on different subsets of the training data. These subsets are created by sampling with replacement, also called bootstrap samples. Because the models are trained independently, any overfitting tendency is reduced when their individual predictions are averaged to form a final prediction. Bagging tends to decrease variance without necessarily increasing bias. Random Forest is a common and popular example of the Bagging technique, where decision trees are both bagged and randomized in terms of feature usage.
Boosting is a sequential process where a new model is built to correct errors made by the previous one. Initially, all training instances receive equal attention, but with every iteration, the misclassified examples from the prior step are given higher focus so that the next model can learn from those mistakes. The final prediction is typically formed through a weighted combination of the individual base learners, with later learners (and the ones that perform better) usually assigned higher weights. Boosting often reduces bias by successively fitting weak learners in a manner that emphasizes the data points that are currently not well predicted.
Mathematical Formulation of Bagging
When using Bagging for a regression or classification problem, suppose we have T base learners h_1(x), h_2(x), ..., h_T(x). The combined output is computed by taking the average (for regression) or majority vote (for classification). In the regression scenario, the final predictor f(x) is:
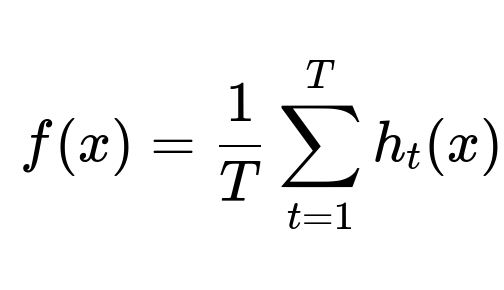
In this expression, T is the total number of base models, and h_t(x) is the prediction of the tth model. This ensemble approach stabilizes predictions and reduces variance.
Mathematical Formulation of Boosting
Boosting combines multiple weak learners in a sequential manner. Suppose we have T learners h_1(x), h_2(x), ..., h_T(x), each trained to emphasize the errors from its predecessor. The final model F(x) often takes a weighted sum of all these base learners:
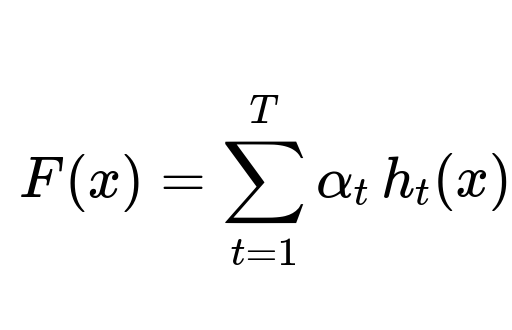
Here T is the total number of iterations or weak learners, alpha_t is a weight indicating the contribution of the tth learner (often determined by its error rate on the training set), and h_t(x) is the tth learner's prediction.
Typical Implementation Details
Bagging can be implemented easily in Python using libraries like scikit-learn:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
X_train, X_test, y_train, y_test = ... # Your data split
base_estimator = DecisionTreeClassifier()
bagging_model = BaggingClassifier(base_estimator=base_estimator, n_estimators=10, max_samples=0.8, bootstrap=True)
bagging_model.fit(X_train, y_train)
predictions_bagging = bagging_model.predict(X_test)
Boosting can be achieved with AdaBoost or Gradient Boosting libraries in scikit-learn:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
X_train, X_test, y_train, y_test = ... # Your data split
base_estimator = DecisionTreeClassifier(max_depth=1)
boosting_model = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50, learning_rate=1.0)
boosting_model.fit(X_train, y_train)
predictions_boosting = boosting_model.predict(X_test)
Key Differences
Bagging trains models independently, which means it focuses on reducing variance by aggregating many parallel learners. It is particularly effective for high-variance, low-bias models like fully grown decision trees. Because each learner trains on different bootstrap samples, the models typically do not correlate strongly, and their averaging leads to smoother predictions.
Boosting, on the other hand, works adaptively. Each new learner is fitted to emphasize data that the current ensemble does not predict well, and this focus often reduces the overall bias. However, because each learner is influenced by the previous ones, boosting can be more prone to overfitting if not regularized properly (through parameters like learning_rate, number of estimators, or constraints on individual learners).
Pitfalls and Edge Cases
Bagging can still overfit if the base learner is too complex and if the number of estimators is small. Properly tuning the depth of decision trees and ensuring there are sufficient ensemble members can help.
Boosting can become prone to overfitting if the learning_rate parameter is too large or if the number of iterations (estimators) is extremely high without appropriate regularization. Techniques such as early stopping, shrinkage (learning rate), and subsampling (as in Gradient Boosting) help mitigate this.
Follow-up Question 1
How do you address overfitting in boosting methods that keep adding more learners?
One way to handle overfitting is to introduce a smaller learning_rate, which prevents each new model from making overly aggressive adjustments to the previous ensemble. Another approach is to set a maximum number of estimators and then use early stopping, where the process halts if the validation error stops decreasing. Regularizing individual weak learners (for example, limiting the depth of decision trees) also reduces the risk of overfitting.
Follow-up Question 2
Which approach is preferable for a high-variance base learner, such as a fully grown decision tree?
Bagging is typically more suitable for high-variance learners because training them on multiple bootstrap samples and averaging reduces the variance substantially. This synergy is best seen in Random Forest, where each individual tree is not only trained on a different random subset of data but also uses randomly chosen subsets of features at each split, further reducing correlation among the trees.
Follow-up Question 3
When might boosting outperform bagging in practice?
Boosting often excels when the main challenge is high bias or when the dataset is relatively large and diverse. By iteratively focusing on misclassified examples, boosting can systematically reduce bias and yield a strong learner. It can work well for complex datasets where a single weak learner fails to capture all the patterns, yet successive corrections significantly improve the ensemble’s accuracy.
Follow-up Question 4
How do you tune hyperparameters in Bagging versus Boosting?
In Bagging, controlling the complexity of each base learner, the number of estimators, and the sample size for each bootstrap are key hyperparameters. For Boosting, learning_rate (shrinkage), number of estimators, and each base learner’s complexity (such as max_depth for trees) are pivotal. Tuning typically involves a grid search or randomized search over these hyperparameters combined with cross-validation to ensure the best balance between bias and variance.
Follow-up Question 5
What if I have a very small dataset? Which ensemble method should I choose?
With a small dataset, boosting can sometimes overfit quickly because it repeatedly emphasizes the same limited examples. You can still use boosting with careful tuning of learning_rate and limited tree depths, but bagging might be more robust overall if you have a model with high variance. Data augmentation or cross-validation during training can also help mitigate the problem of small data size for both approaches.
Follow-up Question 6
Does increasing the number of estimators in bagging always improve performance?
Increasing the number of estimators in bagging generally does not hurt performance severely, but after a point, the gains in accuracy or reduction in variance become marginal. Extremely large ensembles also increase training and prediction time. There is a practical limit, often found through cross-validation, where the model stops improving noticeably with more estimators.
Below are additional follow-up questions
How does the choice of the base estimator in a boosting algorithm impact performance and the risk of overfitting?
Choosing a weak learner like a shallow decision tree is common because shallow trees have low variance and high bias, and boosting systematically reduces bias by adding many such weak learners. If the base estimator is too complex (for example, deeper trees), each model can overfit the data quickly, potentially leading to ensemble overfitting, especially if the learning_rate is not reduced accordingly. On the other hand, if the base learner is too simple (like a very shallow stump), many iterations may be required to achieve good performance, potentially increasing computation time. Hence, a balance is needed: shallow trees are often a good starting point because their simplicity lets the boosting process iteratively refine the decision boundary in a controlled manner, mitigating overfitting risk while systematically reducing bias.
How do boosting algorithms handle class imbalances, particularly since they emphasize misclassified examples more?
In a significantly imbalanced dataset, boosting may continually focus on the minority class if it is consistently misclassified. While this might help identify minority-class examples, it can also lead to overfitting if the algorithm overemphasizes these cases to the detriment of the majority class. One remedy is to adjust class weights so that the boosting process does not excessively prioritize the minority class. Another approach is to use sampling methods (oversampling the minority class, undersampling the majority class) before training. It is also important to track performance metrics such as F1-score, Precision-Recall AUC, or ROC AUC to ensure the boosted model’s attention is balanced across classes. Some implementations allow direct control over how errors on different classes are weighted, further preventing overfitting on the minority class.
What is the effect of random subsampling in boosting, and how does it compare with bagging’s bootstrap approach?
Random subsampling in boosting, sometimes referred to as stochastic gradient boosting, randomly selects a fraction of the data at each iteration to train the new weak learner. This is somewhat similar to how bagging takes different random subsets of the data. However, the key difference is that boosting is still a sequential procedure, and each newly trained model sees a slightly different subset of data (while also focusing on the previously misclassified points). This randomization can help reduce correlation among the weak learners, lowering variance and the risk of overfitting. In contrast, bagging trains each learner on an independently drawn bootstrap sample, focusing on parallelization and variance reduction without emphasis on the errors of prior learners. Stochastic gradient boosting often finds a beneficial trade-off between overfitting control and bias reduction by applying randomness to data sampling.
Does boosting tend to be more sensitive to outliers compared to bagging?
Boosting can be more sensitive to outliers because each model in the sequence tries harder to correct misclassified samples, including potentially outlying or noisy points. If outliers are truly anomalous, the model may end up overfitting these rare cases. Strategies to mitigate this include using robust loss functions (e.g., Huber loss in some boosting implementations) or applying data preprocessing steps to either remove or downweight outliers. Using a smaller learning_rate also helps, ensuring the ensemble does not drastically overemphasize extreme points. Bagging, in contrast, often dilutes the effect of outliers by averaging predictions from multiple independently trained models, reducing the singular impact of anomalous training instances.
Which method (Bagging or Boosting) handles noisy labels better, and why?
Bagging often handles noisy labels better because each individual model is trained on a different bootstrap sample, and the averaging or majority-voting mechanism naturally smooths out extreme predictions caused by mislabeled instances. Boosting, on the other hand, repeatedly focuses on hard-to-classify points, which can include mislabeled instances. If these noisy points are given too much emphasis, the boosting algorithm can overfit to the noise. One way to handle noisy labels with boosting is to introduce early stopping or use a robust loss function that reduces the penalty for extreme misclassifications, thereby preventing the algorithm from excessively prioritizing mislabeled data.
What role does feature engineering and data preprocessing play when deciding between bagging and boosting approaches?
Feature engineering and data preprocessing can have distinct impacts on bagging versus boosting. Because boosting iteratively refines models, subtle patterns in the data can be captured if the features are carefully engineered to reveal important relationships. Inadequate or noisy features can mislead the sequential process more easily, causing overfitting to artifacts. By contrast, bagging tends to be less sensitive to minor flaws in the data because of its averaging effect. Nonetheless, quality feature engineering benefits both methods by enhancing signal-to-noise ratio. In practice, it is crucial to apply consistent scaling or transformations across all ensemble members in either method, ensuring uniform data representation. Properly handled categorical variables, missing values, and outliers help both bagging and boosting perform optimally.
Can bagging and boosting be combined into a single hybrid approach, and how could that be beneficial?
Yes, hybrid approaches exist where boosting is applied on top of bagged models or vice versa. For instance, one might first bag multiple weak learners for stability and then apply a boosting-like mechanism on top of those aggregated results. Alternatively, you might train multiple boosted ensembles on different subsets of the data and then bag the outputs of these boosted models. Such hybridization aims to capture the strengths of both techniques: boosting’s reduction in bias and bagging’s reduction in variance. However, these methods can be computationally expensive, as they involve multiple layers of ensembling, and careful tuning is needed to avoid overfitting or undue complexity.
How do we interpret or explain predictions from boosting and bagging models for stakeholders who demand interpretability?
Both bagging and boosting rely on ensembles of multiple learners, which can complicate direct interpretability. However, there are tools and approaches to address this:
Feature importance analysis: Aggregating feature importances across individual trees provides a sense of which features are most influential.
Surrogate models: Train a simple, interpretable model (like a single decision tree) to approximate the ensemble’s predictions. This surrogate can reveal approximate patterns that the ensemble uses.
Partial dependency plots and SHAP values: These methods help visualize how input features influence predictions, even in an ensemble context.
Boosted models can be trickier to interpret because each learner depends on previous ones. Nonetheless, frameworks like XGBoost and LightGBM offer built-in feature importance measures and can be integrated with advanced explainability packages (e.g., SHAP). Bagging, especially Random Forest, also provides straightforward feature importances and easy generation of partial dependence plots. In both cases, the focus is on summarizing how the ensemble arrived at its decisions, rather than examining any single learner in isolation.
How do the computational costs of bagging and boosting compare for very large datasets, and what are best practices for managing them?
Bagging is easier to parallelize because each learner is trained independently on different bootstrap samples. With adequate computational resources, this can scale fairly well. Boosting is inherently sequential; each new model depends on the residuals or errors of the previous ensemble. While frameworks like XGBoost do offer parallelization within each iteration, the sequential nature still can make boosting slower than bagging for very large datasets. Best practices include:
Using distributed implementations (e.g., Spark MLlib for bagging/boosting or distributed XGBoost) for large-scale data.
Carefully tuning the number of estimators and complexity of each learner to strike a balance between performance and computational cost.
Employing subsampling (in stochastic boosting) and feature sampling to reduce training times.
Is it possible to use neural networks as base learners in bagging or boosting, and what considerations should be kept in mind?
Yes, neural networks can serve as the base learners. In bagging, multiple neural networks can be trained on bootstrap samples, and their outputs can be averaged. This approach is sometimes referred to as an ensemble of neural nets. In boosting, one can iteratively fit neural networks that focus on the residuals of the previous ensemble model. However, training even a single neural network can be computationally expensive, and combining it with boosting’s sequential approach can be very time-consuming. Overfitting is also a concern if each neural network is large. Techniques like early stopping, dropout, or weight decay can mitigate overfitting. Additionally, the interpretability challenge grows because each neural network is typically a complex model, making the final ensemble even harder to explain.