
ML Interview Q Series: How do Decision Trees define the variance reduction metric, and in what way is it employed during splitting?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Variance reduction is typically applied in regression trees to evaluate how effectively a candidate split decreases the overall uncertainty (variance) in the target variable within a node. The core idea is: a “good” split should partition the data into subsets such that each subset has a lower variance in the target values compared to the original node. By choosing the split that yields the largest decrease in variance, the tree attempts to create nodes that are more homogeneous in their target values.
When we say “variance” in a regression tree setting, we refer to the sample variance of the target values. In practical terms, if a node S has many samples with widely differing target values, it has a higher variance; if those target values are very close to one another, it has a lower variance.
Below is the core formula for the variance of the target values in a node S, shown using LaTeX. The parameter S denotes the set of samples in the node, |S| is the number of samples in S, y(x) is the target value for a sample x, and bar(y)_S is the average target value of all samples in S.

During the splitting process, let us assume you split a node S into two children subsets, S_L (left) and S_R (right). The variance reduction metric, often called ΔVar, is computed by taking the original variance of S and subtracting the weighted sum of the variances of these subsets. We write it as:
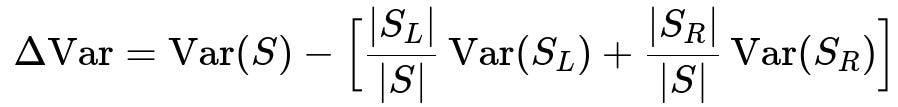
The goal is to choose a split that maximizes ΔVar, i.e., the reduction in variance. This is computed for every potential split (determined by features and thresholds), and the tree picks the split that achieves the highest ΔVar.
If the question arises whether variance reduction is used in classification trees, the short answer is that classification trees generally use metrics like Gini impurity or Entropy reduction. Variance reduction is specifically intended for regression tasks where the target is continuous.
Practical Considerations
In real-world regression tasks, splitting purely based on maximizing variance reduction can lead to very deep trees and overfitting. Hence, techniques such as setting a minimum number of samples per leaf, imposing a maximum tree depth, or using cost-complexity pruning are employed to avoid creating overly specific leaves.
Another point to keep in mind is that outliers can potentially inflate node variances. In practice, robust regression trees or methods like quantile regression trees can mitigate these extremes.
Example in Python
import numpy as np
# Sample data: features X, targets y
X = np.array([[2], [3], [10], [12], [13], [20]])
y = np.array([4.0, 5.2, 9.8, 10.1, 11.7, 21.0])
# Suppose we consider a split at X=10, left side has indices [0,1,2], right side [3,4,5].
S_L = y[[0,1,2]]
S_R = y[[3,4,5]]
# Variance of full node
def variance(values):
return np.mean((values - np.mean(values))**2)
var_full = variance(y)
var_left = variance(S_L)
var_right = variance(S_R)
weight_left = len(S_L) / len(y)
weight_right = len(S_R) / len(y)
variance_reduction = var_full - (weight_left*var_left + weight_right*var_right)
print("Variance of full node:", var_full)
print("Variance of left node:", var_left)
print("Variance of right node:", var_right)
print("Variance Reduction (ΔVar):", variance_reduction)
In this example, the split at X=10 might or might not be optimal. The algorithm iterates over all possible splits and computes the variance reduction for each, selecting the one that yields the highest ΔVar.
Potential Follow-up Questions
How is this different from MSE as a splitting criterion?
In a regression tree, variance is equivalent to the mean squared deviation from the mean. Using the variance or the mean squared error (MSE) for node splits typically produces the same result, because they both capture how far values deviate from their average. In many implementations, the terms “variance reduction” and “MSE reduction” are used interchangeably for splitting.
Does variance reduction guarantee a globally optimal tree?
No, the tree-building process (based on variance reduction or any other metric) usually employs a greedy strategy: it picks the locally best split at each node. This does not guarantee a globally optimal tree. This is why post-pruning or methods like gradient boosting combine multiple trees, as a single, unpruned decision tree often overfits.
Why not use variance reduction in classification problems?
Classification trees involve discrete class labels rather than continuous target values. Metrics like Gini impurity or Entropy measure the purity of class distributions in each node. Variance reduction does not directly align with the goal of class purity, so it is not suitable for classification tasks.
What happens if the variance reduction is negative?
A negative variance reduction typically indicates that the split actually makes the variance worse in the child nodes compared to the parent node, which is an undesired outcome. In standard implementations, that split would simply not be chosen. The tree-building algorithm only keeps splits that improve (i.e., reduce) the variance and discards those that do not.
How does pruning factor into variance reduction?
During the pruning stage (e.g., cost-complexity pruning), subtrees that do not substantially decrease variance (or that fail to improve out-of-sample predictions) are pruned to avoid overfitting. The rationale is that overly specific splits might reduce training variance by tiny amounts but fail to generalize to new data.
These considerations underscore how variance reduction is used in a regression tree’s splitting process, as well as its limitations and practical aspects.