
ML Interview Q Series: How do Decision Trees differ from Neural Networks in practical machine learning scenarios?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Decision Trees represent data by recursively partitioning the feature space based on certain splitting criteria, often Gini impurity or entropy. Neural Networks, on the other hand, map inputs to outputs through layers of weighted connections that can represent highly complex transformations.
Model Structure and Learning Approach
Decision Trees rely on a hierarchical, rule-based structure. Each node splits data by a threshold or a categorical division. Neural Networks are a collection of layers where parameters are learned using backpropagation. Trees partition the input space in a piecewise-constant manner, whereas Neural Networks tend to learn smooth, continuous functions that can capture complicated, high-dimensional interactions.
Mathematical Core for Decision Trees
One of the most common splitting criteria in Decision Trees is the Gini impurity for classification tasks. It measures how frequently a randomly chosen element from the set would be incorrectly labeled if it was randomly labeled according to the distribution of labels in the node. The formula for Gini impurity of a node with K classes is shown below.
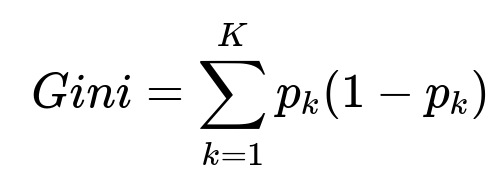
Here p_k is the fraction of samples belonging to class k in that node, and K is the total number of classes. A lower Gini impurity indicates that the node is more “pure” (i.e., it contains mostly samples of a single class).
Mathematical Core for Neural Networks
A feed-forward operation in a simple multi-layer perceptron typically involves a linear transformation followed by a non-linear activation function. For a given layer l, the transformation can be expressed as:

Here h^{(l)} denotes the output of layer l, W^{(l)} is the weight matrix for layer l, b^{(l)} is the bias term for layer l, and phi is a non-linear activation function such as ReLU or sigmoid. This process is repeated for multiple layers, enabling the network to learn complex features.
Interpretability and Transparency
Decision Trees are straightforward to interpret. Each node represents a simple decision, and the overall path from root to leaf can be easily followed. Neural Networks are often criticized for being black-box models, because the learned parameters are distributed across many layers and are not trivially interpretable. Techniques like feature importance and saliency maps can offer insights into the network’s decisions, but they do not achieve the same clarity as the straightforward rule sets in a Decision Tree.
Tendency to Overfit
Decision Trees can overfit if they grow too deep, capturing noise in the training data. Pruning or setting constraints like maximum depth helps reduce overfitting. Neural Networks can also overfit if they are very large or trained for too many epochs without regularization. Methods like dropout, weight decay, and data augmentation often help combat this.
Data Requirements
Decision Trees typically work well with tabular data where feature splits are meaningful. They handle outliers more gracefully because a single split may isolate outliers easily. Neural Networks usually require large amounts of data to fully realize their representational capacity. They thrive in domains like computer vision or NLP, where vast labeled datasets are available, and they can learn extremely intricate feature hierarchies.
Training Complexity and Computation
Decision Trees are relatively fast to train on smaller datasets. However, they can become slow with extremely large feature spaces or large datasets if complex ensembles like random forests or gradient-boosted trees are used. Neural Networks can be computationally intense, especially when dealing with high-dimensional inputs or deep architectures, but specialized hardware (like GPUs) and optimized libraries reduce these training times significantly.
Example Implementations in Python
Below is a simple Decision Tree classifier in scikit-learn:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
tree_model = DecisionTreeClassifier(max_depth=3)
tree_model.fit(X_train, y_train)
accuracy_tree = tree_model.score(X_test, y_test)
print("Decision Tree Test Accuracy:", accuracy_tree)
A minimal feed-forward Neural Network in PyTorch might look like this:
import torch
import torch.nn as nn
import torch.optim as optim
# Example dataset (random inputs for illustration)
X_train = torch.randn(100, 4) # 100 samples, 4 features
y_train = torch.randint(0, 3, (100,)) # 100 samples, 3 classes
# Simple fully connected network
model = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
optimizer.zero_grad()
outputs = model(X_train)
loss = loss_function(outputs, y_train)
loss.backward()
optimizer.step()
# Example forward pass
with torch.no_grad():
outputs = model(X_train)
_, predicted = torch.max(outputs, 1)
accuracy_nn = (predicted == y_train).float().mean()
print("Neural Network Training Accuracy:", accuracy_nn.item())
Potential Follow-up Questions
What scenarios favor Decision Trees over Neural Networks?
Decision Trees can excel on smaller, structured, tabular datasets that do not contain extremely high dimensional features. They are easy to interpret and can handle missing values with less preprocessing. Neural Networks often shine when the data is high dimensional (images, text, audio) and large enough to support complex model training.
How can we mitigate overfitting in both models?
For Decision Trees, pruning techniques or limiting the maximum depth and minimum samples per split are common strategies. For Neural Networks, regularization methods like dropout, weight decay, or early stopping can help, along with data augmentation techniques to increase dataset diversity.
Why are Decision Trees sometimes preferred for business applications?
Many business applications require stakeholders to understand and trust the model’s decisions. A Decision Tree can be visualized, and each decision path is transparent, allowing non-technical users to see how predictions are made. Neural Networks, although potentially more powerful, can be opaque, making it harder to explain the logic behind certain outputs.
Do ensemble methods blur the line between these two models?
Ensembles of Decision Trees like Random Forests and Gradient Boosted Trees can sometimes rival or exceed Neural Networks on structured data. They remain tree-based models but add more complexity and lower variance through averaging or boosting. Meanwhile, Neural Networks can be ensembled as well, but typically the approach differs, focusing more on random initialization or architecture variations.
How might one combine both?
A possible approach is to use a Neural Network for feature extraction (especially in domains like images or text), then feed those features into a Decision Tree model. Alternatively, one might train a Decision Tree and then use a small neural network to calibrate or reweight the Decision Tree outputs. Such combinations can sometimes capitalize on the interpretability of trees and the representational power of neural networks.