
ML Interview Q Series: How do Ensemble Learning and Multiple Kernel Learning fundamentally differ in their underlying principles and practical usage?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Ensemble Learning and Multiple Kernel Learning (MKL) share a conceptual similarity in that they both aim to combine multiple models or functions to improve predictive accuracy. However, they differ significantly in how these combinations are carried out and the types of problems they address.
Key Idea of Ensemble Learning
Ensemble Learning is a meta-approach where multiple base learners (such as decision trees, neural networks, or other classifiers/regressors) are combined to produce a single, more robust prediction. Methods such as Bagging, Boosting, and Stacking aggregate predictions to reduce variance, bias, or both.
Ensemble methods do not necessarily require the base learners to be kernel-based. Instead, they rely on statistical techniques (like sampling the data differently, reweighting misclassified examples, or stacking layer outputs as new inputs) to produce an overall strong model. The fundamental assumption is that by aggregating diverse hypotheses, one can cancel out the errors of individual learners and achieve better accuracy.
Key Idea of Multiple Kernel Learning
Multiple Kernel Learning primarily arises in the context of kernel methods (e.g., Support Vector Machines). A kernel function implicitly maps data into a higher-dimensional feature space, enabling powerful linear separation in that space. When using a single kernel, you select or design one kernel function (like an RBF or polynomial kernel). However, different kernels may capture different aspects of the data distribution. This is where MKL steps in.
MKL attempts to learn an optimal combination of several kernel functions to create a single kernel that best suits the problem. Typically, you have M kernels k_m(x, x'), each with a distinct shape or parameterization. Rather than guessing which kernel is best, you allow the model to learn a set of weights beta_m that govern how strongly each kernel influences the final combination.
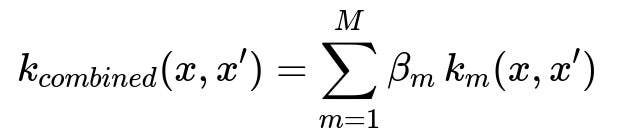
In this expression, M is the total number of kernels available, beta_m is the weight for kernel m, and k_m(x, x') is the m-th kernel function evaluated between any two points x and x'. These beta_m coefficients are often constrained (such as requiring them to be nonnegative or to sum to 1) to ensure a valid positive semi-definite combined kernel. The model then optimizes these coefficients alongside the parameters of the classifier or regressor (often a Support Vector Machine) to minimize the overall training loss.
Differences in Architecture and Philosophy
Ensemble Learning can be model-agnostic. You can combine any types of learners, provided you have a mechanism to unify their predictions. Boosting techniques such as AdaBoost re-weight the training data for each subsequent weak learner, while Bagging (e.g., Random Forests) trains each base learner on different bootstrap samples.
Multiple Kernel Learning is specific to kernel-based methods. Instead of combining entire models in a voting or averaging scheme, it combines the kernels themselves into a single, more expressive kernel. The final classifier (such as an SVM) is then trained on that resultant kernel. Essentially, MKL is about learning the best representation of data via kernel combination, whereas Ensemble Learning is about combining the predictions of separate learners.
Practical Implications
Ensemble Learning:
Widely used in competitions and industry because it is straightforward to implement and often yields significant performance boosts.
Different ensemble strategies exist, including random forests (Bagging-based) and gradient boosting frameworks, each with its own trade-offs in terms of interpretability, variance reduction, and bias reduction.
Potential downside is increased model complexity. A large ensemble can be computationally heavy in both training and inference.
Multiple Kernel Learning:
Typically used in domains where kernel methods excel (e.g., structured data, smaller data sets, or problems where the kernel trick is especially beneficial).
Learning multiple kernels can capture diverse data representations: for instance, different kernels might handle different feature groups or different similarity measures.
Can be more elegant if your problem specifically aligns well with kernel-based approaches. However, it can be less flexible if your application does not naturally favor kernel methods.
Optimizing multiple kernel weights can be computationally expensive, and performance is highly sensitive to hyperparameter tuning and how the kernels are structured.
Potential Follow-up Questions
How would you apply Ensemble Learning in a deep learning context?
Ensembling in deep learning typically involves training multiple neural networks on the same data but with different initializations, architectures, or hyperparameters. These individual models’ outputs can be averaged or majority-voted to produce a final prediction. Another approach, known as Snapshot Ensembling, trains a single neural network and takes multiple "snapshots" of it at various training stages.
Ensembling deep networks can reduce variance and improve robustness, but it demands more memory and computational resources. In production systems, the overhead of deploying multiple large models can be costly. Techniques such as distillation can reduce this burden by training a smaller "student" network on the ensemble’s predictions.
What are the main challenges in implementing Multiple Kernel Learning?
The most common challenges include:
Selecting the right set of kernel functions. You might combine RBF kernels with different bandwidths, polynomial kernels of various degrees, or domain-specific kernels. Determining constraints for the weights beta_m and ensuring the resulting kernel matrix remains positive semi-definite. Managing computational costs, as MKL problems often require solving more complex optimization procedures than standard SVMs. Avoiding overfitting when using a large collection of kernels. Regularization strategies or sparsity constraints (e.g., L1 or elastic-net style) on the kernel weights help mitigate this.
Can Ensemble Learning and Multiple Kernel Learning be combined?
Yes. One could build an ensemble where each base learner is a kernel-based model with a different kernel, and then vote or average their decisions. Alternatively, one could use an MKL approach within each base learner. This combination can be powerful but also increases complexity significantly. Balancing computational efficiency with performance gains is crucial.
Are there domain-specific considerations that favor one method over the other?
Ensemble Learning methods are extremely general-purpose and easy to apply across many domains, especially when you have large datasets and computational resources. Multiple Kernel Learning is more specialized and is particularly appealing when you have:
Multiple modalities or feature subsets, each of which might be represented best by a separate kernel. Smaller datasets or specialized tasks (like structured prediction) where kernel methods shine. A strong prior belief that combining specific kernels will yield a superior data representation.
On the other hand, if your data is vast and unstructured (like images or text), deep learning ensembles might be more practical in production.
Would I always see a performance benefit from using MKL over a single kernel?
Not necessarily. If a single kernel function is already well-tuned to capture the structure of your data, the complexity and overhead of MKL may not provide a meaningful benefit. MKL helps most when data exhibits varied relationships or patterns that different kernels can capture. Proper kernel selection and weighting can be crucial, and if done poorly, it might lead to overfitting or negligible improvements.
Could we frame Ensemble Learning as a special case of MKL or vice versa?
Conceptually, Ensemble Learning and MKL are distinct. Ensemble Learning deals with aggregating different model outputs, while MKL integrates multiple kernels into a single model. However, there is a loose analogy: in stacking-based ensemble methods, we combine the predictions (or features) of multiple models, which in some sense is combining learned representations. MKL can be viewed as combining different “feature mappings,” but the scope is limited to kernel functions. One might argue that both are forms of "model combination," yet their operational details and typical use cases differ significantly.
Implementation Example in Python
Below is a simplified pseudo-example of implementing a kernel-based SVM and then switching to multiple kernel learning. This example is more conceptual than production-ready.
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics.pairwise import rbf_kernel, polynomial_kernel
from sklearn.model_selection import train_test_split
X, y = ... # Your data and labels
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Single-kernel SVM with RBF
rbf_svc = SVC(kernel='rbf', gamma=0.5, C=1.0)
rbf_svc.fit(X_train, y_train)
print("Single Kernel RBF Accuracy:", rbf_svc.score(X_test, y_test))
# Simple approach for multi-kernel combining:
K_rbf = rbf_kernel(X_train, gamma=0.5)
K_poly = polynomial_kernel(X_train, degree=2, coef0=1)
# Weighted sum of kernels
beta_rbf, beta_poly = 0.7, 0.3
K_combined = beta_rbf*K_rbf + beta_poly*K_poly
# SVC requires a precomputed kernel
mk_svc = SVC(kernel='precomputed', C=1.0)
mk_svc.fit(K_combined, y_train)
# Evaluate on test set
K_rbf_test = rbf_kernel(X_test, X_train, gamma=0.5)
K_poly_test = polynomial_kernel(X_test, X_train, degree=2, coef0=1)
K_combined_test = beta_rbf*K_rbf_test + beta_poly*K_poly_test
print("Multi-Kernel Accuracy:", mk_svc.score(K_combined_test, y_test))
This simplistic demonstration uses a fixed combination of two kernels by assigning them weights 0.7 and 0.3. True Multiple Kernel Learning would learn these weights automatically through an optimization procedure.
By considering these topics and potential follow-up discussions, you can illustrate a solid grasp of the conceptual and practical nuances distinguishing Ensemble Learning and Multiple Kernel Learning.