
ML Interview Q Series: How do k-Means and k-Medians differ, and under which conditions is one approach more appropriate than the other?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
k-Means and k-Medians are both clustering methods aimed at grouping data points into k clusters based on their similarity. The main difference lies in how they define “center” of a cluster and what distance or error metric is minimized.
k-Means: Minimizing Squared Euclidean Distance
k-Means attempts to find cluster centers (often referred to as centroids) that minimize the sum of squared distances between each data point and its nearest centroid.

Here, x_{i} represents the i-th data point, n is the total number of data points, k is the number of clusters, C_{j} is the j-th cluster, and mu_{j} is the centroid of cluster j. The function 1(x_{i} in C_{j}) is an indicator function that is 1 if x_{i} belongs to cluster j and 0 otherwise.
For each data point, we measure the Euclidean distance to a centroid, square it, and sum those squared distances. k-Means then updates the centroid to be the arithmetic mean of all points belonging to the cluster. This process iterates until convergence or for a fixed number of iterations.
A key characteristic of k-Means is that the mean is sensitive to outliers. Large deviations in a cluster can shift the mean significantly, which makes k-Means best suited for data without extreme outliers and where clusters are roughly spherical in shape.
k-Medians: Minimizing Absolute Deviations
k-Medians clustering reduces the sum of absolute distances (often using L1 or Manhattan distance) to the cluster center. Instead of updating the centroid to be the arithmetic mean, k-Medians chooses the median point (or a point close to the median in high-dimensional spaces). The goal is to minimize the sum of absolute differences from each cluster center.
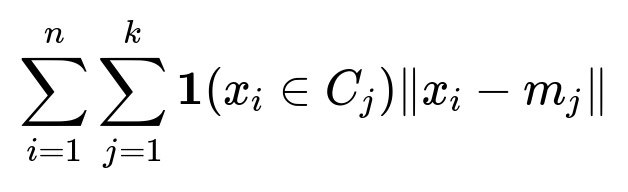
Here, m_{j} represents the median-based center of cluster j. This method is much more robust to outliers because the median is less influenced by extreme values than the mean. If your data contains points far from the main distribution, k-Medians may provide more stable cluster centers.
When to Use k-Means vs. k-Medians
k-Means is often preferred for data that: • Has relatively few or no outliers. • Consists of clusters that are roughly spherical. • Is well-represented by minimizing squared error metrics.
k-Medians is a better fit when: • The data has outliers or extreme values. • You want to reduce the influence of large deviations. • You prefer a robust measure of central tendency (the median rather than the mean).
Practical Implementation Details
Below is a brief Python snippet showing how you might implement k-Means and k-Medians. Standard libraries like scikit-learn provide k-Means out-of-the-box but do not directly provide k-Medians. However, we can outline a pseudo-implementation or use third-party libraries that might have it.
import numpy as np
from sklearn.cluster import KMeans
# Example with k-Means using scikit-learn
data = np.random.rand(100, 2) # 100 points in 2D
kmeans_model = KMeans(n_clusters=3, random_state=42)
kmeans_model.fit(data)
centroids_kmeans = kmeans_model.cluster_centers_
labels_kmeans = kmeans_model.labels_
# Pseudo-implementation for k-Medians (a rough outline)
def kmedians(data, k, max_iter=100):
# Randomly choose initial medians
indices = np.random.choice(len(data), k, replace=False)
medians = data[indices]
for _ in range(max_iter):
# Assign points to the nearest median
clusters = [[] for _ in range(k)]
for point in data:
dists = [np.sum(np.abs(point - m)) for m in medians]
cluster_idx = np.argmin(dists)
clusters[cluster_idx].append(point)
# Update medians
new_medians = []
for cluster_points in clusters:
if len(cluster_points) > 0:
# Compute the median along each dimension
new_medians.append(np.median(cluster_points, axis=0))
else:
# Edge case: if a cluster has no points, reinitialize
new_medians.append(data[np.random.randint(len(data))])
new_medians = np.array(new_medians)
# Check for convergence
if np.allclose(medians, new_medians):
break
medians = new_medians
return medians, clusters
centroids_kmed, clusters_kmed = kmedians(data, 3)
In the snippet for k-Medians, points are assigned to the nearest median based on the L1 distance (sum of absolute differences). The median center is updated dimension-wise using the median function.
What are the computational complexities of k-Means and k-Medians?
k-Means typically has a complexity of O(n * k * d * i), where n is the number of data points, k is the number of clusters, d is the dimensionality of each data point, and i is the number of iterations until convergence. Each iteration requires assigning each point to the nearest centroid and then updating the centroids.
k-Medians has a similar complexity in terms of assigning data points to cluster centers, but updating each center to the median can be slightly more expensive because finding the median in each dimension might involve sorting or selection-based algorithms. Nonetheless, both methods often converge in a reasonable number of iterations, and in practice, the time complexity difference is not drastic unless your dataset is extremely large or very high-dimensional.
How do outliers impact both algorithms?
Outliers can greatly affect the results of k-Means. Because k-Means uses the mean as the cluster center, a single extreme point can shift the mean significantly, possibly creating suboptimal clusters. In contrast, k-Medians is less sensitive to outliers, as the median is more robust. This robustness is often the deciding factor when the data has many spurious points.
What is the role of distance metrics in k-Means and k-Medians?
k-Means typically uses Euclidean distance and squares it in the objective function, making it well-suited for continuous data without large deviations. k-Medians is typically associated with L1 distance (Manhattan distance). The choice of distance metric plays a large role in how the clusters form and which points end up together. k-Means tries to minimize variance-like dispersion, whereas k-Medians focuses on minimizing absolute deviation.
In what scenarios might k-Medoids be a preferred variant?
k-Medoids is another related variant that might be used when you want the “center” of each cluster to be an actual data point (a medoid) rather than the mean or median, or when you have a more general distance function that is not necessarily Euclidean or Manhattan. k-Medoids can use arbitrary distance measures, which makes it preferable for categorical data or scenarios where domain-specific distances are necessary.
Are there any initialization challenges for these algorithms?
Both k-Means and k-Medians can be sensitive to initialization. A poor initial choice of centers can lead to suboptimal clustering or slower convergence. Common solutions include running the algorithm multiple times with different random initializations or using more advanced initialization schemes (like k-means++). For k-Medians, a similar approach of choosing diverse initial medians can help avoid poor local minima.
What happens if a cluster has no points in one of the iterations?
This can happen for both methods if all points assign themselves to other cluster centers. A common approach is to choose a random data point (from the dataset) as the new center for that empty cluster or reassign the farthest point from the largest cluster to the empty one. Handling these edge cases ensures that the algorithm continues to update all k clusters.
How does dimensionality affect k-Means vs. k-Medians?
As dimensionality grows, both k-Means and k-Medians can suffer from the “curse of dimensionality.” In high dimensions, distance measures (whether Euclidean or Manhattan) tend to lose their discriminative power because points can appear equally distant. Dimensionality reduction or feature selection may be needed before applying these algorithms. In very high dimensions with possible outliers, k-Medians might still provide a more robust solution, but the overall clustering challenge remains significant.
Can these algorithms be extended to large-scale datasets?
Both k-Means and k-Medians can be adapted for large datasets. For k-Means, mini-batch k-means is a common extension that processes small batches of data at a time, leading to faster performance and lower memory usage. For k-Medians, similar incremental or online approaches can be used, though they are less common in standard libraries. Parallelizing distance computations and center updates across multiple machines is also feasible.
What are typical convergence criteria?
Common convergence criteria include: • Centroid/median positions no longer change significantly. • Change in the objective function value (sum of squared distances for k-Means or sum of absolute distances for k-Medians) is below a certain threshold. • A predefined maximum number of iterations.
In practice, many implementations set a maximum number of iterations for efficiency and stop early if changes drop below a tolerance value.
Does normalizing or scaling data matter?
Yes. Both k-Means and k-Medians rely on distance measures. When different features have different scales, the clustering outcome might be dominated by features with larger numerical values. Normalizing or standardizing each feature to a consistent scale can help ensure that each dimension contributes equally to the distance measure.
How do we choose k?
Selecting k, the number of clusters, is not trivial. Methods like the “Elbow Method,” the “Silhouette Score,” or domain knowledge can guide the choice. For both k-Means and k-Medians, picking too few or too many clusters can lead to poor clustering quality or oversegmentation. Cross-validation methods (e.g., repeated runs with different splits) or heuristics can also be helpful.