
ML Interview Q Series: How do Manhattan distance and Euclidean distance differ when applied to clustering tasks?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Manhattan distance is closely tied to the concept of absolute differences. It is sometimes referred to as the L1 norm in a vector space. When using Manhattan distance in clustering, each dimension's difference contributes additively, reflecting a “city-block” or “taxicab” geometry. Meanwhile, Euclidean distance is associated with the L2 norm and involves squaring and summing the component-wise differences before taking a square root. This difference in mathematical form has significant implications for how clusters are shaped and how algorithms converge during training.
Here is the core mathematical expression for Manhattan distance:
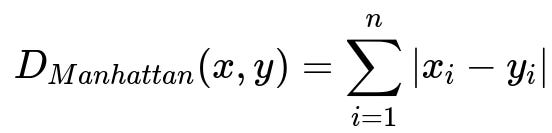
In this expression, x and y represent two points in n-dimensional space, x_i and y_i are the components of those points along dimension i, and |x_i - y_i| is the absolute difference along that dimension.
For Euclidean distance, the core formula is:

Here, x and y are again two points in n-dimensional space, x_i and y_i are their respective coordinates along dimension i, and (x_i - y_i)^2 is the squared difference in each dimension. After summing those squared differences, one takes the square root.
When applied to clustering, the choice of distance metric can alter the shape and boundaries of clusters. Euclidean distance typically produces clusters with spherical boundaries in each region of the feature space (assuming no special weighting or transformations), while Manhattan distance can yield more diamond-shaped regions because it relies on summing absolute differences instead of squared differences.
If features vary widely in scale, Euclidean distance can be heavily dominated by dimensions with larger variance, since squaring emphasizes larger numerical differences. By contrast, Manhattan distance places a more uniform emphasis across dimensions. As a result, if outliers exist, Euclidean distance tends to amplify their impact, whereas Manhattan distance can sometimes reduce the effect of these large deviations. Depending on the nature of data and the objectives of clustering, one might favor one metric over the other.
Handling Outliers and High Dimensions
In a high-dimensional setting, Euclidean distance can become less meaningful because all points tend to appear “far” from one another. This phenomenon is often referred to as the curse of dimensionality. Manhattan distance can sometimes mitigate this by focusing on absolute differences without squaring. Still, one must remember that with extremely high-dimensional data, many distance-based methods can suffer from diminished separation between points.
Outliers can sway cluster centers more strongly under Euclidean distance since the squared term magnifies the effect of large values. Manhattan distance might be less sensitive to outliers, but it still accumulates differences linearly if there are extreme values in multiple dimensions.
Implementation Details in Python
Below is an example illustrating how to configure a clustering algorithm (like KMeans) with different distance metrics. scikit-learn’s KMeans only supports Euclidean distance out of the box, so for a Manhattan distance variant, one typically has to either implement a custom approach or rely on other libraries (like clustering in scipy, or apply K-Medoids with Manhattan distance). Here is a brief example of custom usage:
import numpy as np
from sklearn.cluster import KMeans
from scipy.spatial.distance import cityblock, euclidean
# Sample data
X = np.array([
[1, 2],
[2, 3],
[10, 12],
[11, 14],
[50, 60]
])
# Standard K-Means with Euclidean distance
kmeans = KMeans(n_clusters=2, init='k-means++', random_state=42)
kmeans.fit(X)
labels_euclidean = kmeans.labels_
# For Manhattan distance, one approach is to compute a custom approach
# For demonstration, let's calculate cityblock distance among points:
def manhattan_kmedoids(X, k):
# This is a simplistic placeholder for demonstration
# A proper K-Medoids approach is recommended in production
# Perform some naive iteration to pick 'medoids' and assign clusters
import random
medoids_indices = random.sample(range(len(X)), k)
medoids = X[medoids_indices]
labels = [0]*len(X)
# Simple iteration
for _ in range(10):
# Assign each point to the nearest medoid
for i, point in enumerate(X):
distances = [cityblock(point, m) for m in medoids]
labels[i] = np.argmin(distances)
# Update medoids (naive approach)
for cluster_idx in range(k):
cluster_points = X[np.array(labels) == cluster_idx]
# Choose new medoid by minimizing total Manhattan distance
best_m = None
best_cost = float('inf')
for cp in cluster_points:
cost = sum([cityblock(cp, other) for other in cluster_points])
if cost < best_cost:
best_cost = cost
best_m = cp
medoids[cluster_idx] = best_m
return labels, medoids
labels_manhattan, medoids = manhattan_kmedoids(X, 2)
print("Euclidean-based KMeans cluster labels:", labels_euclidean)
print("Manhattan-based KMedoids cluster labels:", labels_manhattan)
print("Medoids using Manhattan distance:", medoids)
Potential Follow-Up Question: Why might we favor Manhattan distance over Euclidean distance in certain clustering scenarios?
Manhattan distance is sometimes preferred in situations where data might contain significant outliers or when different features have varying scales that could magnify the effect of larger values under Euclidean distance. It can also be effective for certain high-dimensional data sets where the squared nature of Euclidean distance exacerbates the problem of all points lying in a far-away boundary, though caution still applies in very high-dimensional spaces.
Potential Follow-Up Question: How does scaling of features affect these distance metrics?
When features have very different ranges, Euclidean distance can amplify the dimension with the largest range due to squaring. Normalizing or standardizing features can help mitigate this effect. Manhattan distance also benefits from scaling or normalization, but in a less exaggerated way compared to Euclidean distance. The core principle of uniform influence across dimensions remains important for interpretable clustering outcomes.
Potential Follow-Up Question: In practical clustering algorithms like KMeans, why is Euclidean distance commonly used rather than Manhattan distance?
KMeans is designed with Euclidean distance partly because the “means” update step is mathematically straightforward under the L2 norm. Minimizing the sum of squared Euclidean distances connects to a closed-form solution for the centroid. For Manhattan distance, there is no direct closed-form update for the cluster center that minimizes the sum of absolute distances, so approaches like K-Medoids are employed instead.
Potential Follow-Up Question: Can using Manhattan distance lead to different cluster shapes compared to Euclidean distance?
Yes, Manhattan distance can produce diamond-shaped decision boundaries in each region of space, while Euclidean distance typically yields spherical or circular boundaries (in low dimensions). This geometric shape difference can significantly influence how data points are grouped, especially when distributions are elongated along feature axes.
Potential Follow-Up Question: How do both distances behave in sparse feature spaces?
In sparse feature spaces where many coordinates are zero, Manhattan distance (L1) can sometimes be more interpretable. It effectively counts how many coordinates differ (and by how much) in an absolute sense. Euclidean distance can be less intuitive if only a few coordinates have non-zero values but still can produce meaningful clusters if squared differences in those non-zero dimensions dominate. Data preprocessing and normalization remain crucial to get robust results in both cases.