


📚 Browse the full ML Interview series here.
Comprehensive Explanation
One way to approach this is by remembering that a Receiver Operating Characteristic (ROC) curve plots the True Positive Rate (TPR) against the False Positive Rate (FPR) across a range of classification thresholds, whereas a Precision–Recall curve plots Precision against Recall. These two distinct ways of measuring performance can yield differing insights depending on the characteristics of the data, such as the prevalence of positive examples.
Core Mathematical Definitions

TPR is also referred to as sensitivity or recall. It measures the fraction of true positives that were correctly identified out of all actual positives. TP represents the number of true positives, while FN represents the number of false negatives.
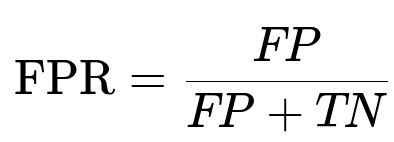
FPR measures the fraction of negatives that are incorrectly labeled as positive. FP represents the number of false positives, while TN represents the number of true negatives.
Precision measures out of all predicted positives, how many are actually positive. FP represents the number of false positives.

Recall is the same as TPR. It captures out of all true positives, how many are caught by the classifier.
ROC Curves
A ROC curve focuses on the trade-off between TPR and FPR. By adjusting the threshold used by a binary classifier, you get different TPR-FPR pairs. Key points about ROC curves include:
They show you how well the classifier can rank the positives higher than the negatives in a broad sense. They do not explicitly account for class imbalance in the sense that even with a very large number of true negatives, a small proportion of false positives can still keep the FPR deceptively low. The Area Under the ROC Curve (AUC-ROC) is often used to summarize the classifier's performance into a single number that ranges from 0.5 (random guessing) to 1.0 (perfect classification).
Precision–Recall Curves
A Precision–Recall (PR) curve indicates how well the classifier balances precision and recall. By varying the classification threshold, you move from points of high precision and low recall to points of low precision and high recall. Key points about PR curves include:
They are especially informative with high class imbalance, since precision is directly affected by the number of negative instances incorrectly labeled as positive. They highlight how well a model is doing on the positive class alone, which is crucial if the positive class is rare. The Area Under the PR Curve can be used as a single metric; it is more sensitive to class imbalance and can give a clearer view of performance when the positive examples are few.
Practical Implementation Tips
In Python, you can generate both curves using scikit-learn:
from sklearn.metrics import roc_curve, precision_recall_curve
import matplotlib.pyplot as plt
# Suppose y_true is the ground truth labels (0 or 1)
# and y_scores are the predicted probabilities for class 1.
fpr, tpr, _ = roc_curve(y_true, y_scores)
precision, recall, _ = precision_recall_curve(y_true, y_scores)
# Plot ROC
plt.figure()
plt.plot(fpr, tpr, label='ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
plt.show()
# Plot Precision-Recall
plt.figure()
plt.plot(recall, precision, label='PR curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend()
plt.show()
How do you decide when to rely on ROC vs. Precision–Recall?
When your dataset is balanced (similar proportion of positive and negative classes), both ROC curves and Precision–Recall curves can be useful, but ROC curves are more commonly used and can provide a straightforward measure of the classifier’s overall ranking performance. If your dataset is highly imbalanced, a Precision–Recall curve often offers a more insightful depiction of how well the positive class is being correctly identified.
Why is ROC sometimes misleading for imbalanced datasets?
If you have a very large number of negative samples relative to positive samples, a small number of false positives can still keep the FPR low, making the ROC curve appear overly optimistic. Precision–Recall curves reveal how the model is performing on the positive class more directly because precision plummets if there are many false positives even if the positive class is small.
How can AUC-PR be interpreted differently from AUC-ROC?
Area Under the Precision–Recall Curve (AUC-PR) focuses solely on performance regarding the positive class. A high AUC-PR means your model achieves both high precision and high recall across thresholds. Area Under the ROC Curve (AUC-ROC) measures how well your model separates positives from negatives overall. In scenarios of heavy imbalance, you might see a high AUC-ROC but a relatively low AUC-PR, indicating the model may rank most positives higher than negatives in a broad sense yet fail to correctly identify enough positives without bringing in too many false positives.
Are there cases where ROC is still valuable even with imbalance?
ROC can still be beneficial if you care about ranking instances effectively. If your application primarily cares about how the model ranks different outcomes, AUC-ROC can provide a robust measure. But if you need to optimize for returning a small set of predictions that are predominantly correct positives (such as in information retrieval, medical diagnostics, or anomaly detection with fewer positives), the Precision–Recall curve or AUC-PR will often be more practical.
Below are additional follow-up questions
How does label noise affect ROC and Precision–Recall curves, and how can we mitigate its impact?
Label noise or mislabeling refers to situations in which some of the training or validation labels are incorrectly assigned. This noise can lead to misleading performance metrics:
When positive labels are flipped to negative (or vice versa), both ROC and Precision–Recall curves can be affected. If many actual positives are mislabeled as negatives, the classifier may appear to miss more positives than it truly does, which can lower TPR or Recall. Conversely, if actual negatives are mislabeled as positives, this can inflate FP counts, reducing Precision. ROC curves can sometimes mask a small but critical amount of mislabeled data because False Positive Rate is normalized by the total number of actual negatives. If the noise is not extremely large relative to the negative class size, the effect on FPR might not look as dramatic, whereas Precision–Recall will likely suffer when there is an increase in false positives or false negatives. To mitigate label noise, one approach is to perform thorough data cleaning. You could cross-check labels with domain experts, or use data-driven anomaly detection to identify suspicious label patterns. Another strategy is to use robust loss functions that reduce the influence of noisy examples (e.g., loss functions that cap the gradient contributions from potential outliers). Label smoothing in deep learning can also help, although it does not entirely eliminate the problem of mislabeled data. In severely noisy datasets, you may see significant dips in both ROC and Precision–Recall curves, and you should then question the reliability of your performance measures. You might augment these metrics with additional checks, like manual audits of misclassifications to confirm that the label was indeed correct.
Is there a way to use ROC or Precision–Recall curves to help calibrate a classifier, and are there any pitfalls?
Classifier calibration involves adjusting the model’s probability outputs so that they align better with true likelihoods of events. For instance, when a model outputs a predicted probability of 0.8 for an instance, you want the true chance of it being positive to be close to 0.8 in reality.
ROC curves focus on ranking performance. A perfect rank ordering can still have probabilities that are not well calibrated. Thus, you can have a high AUC-ROC but probabilities that deviate substantially from actual observed frequencies. Hence, ROC curves alone are not an ideal mechanism for calibration. Precision–Recall curves can give you a sense of how predicted positive probabilities behave relative to actual outcomes, but they also are not explicitly designed for calibration. They indicate how many of your predicted positives are correct at a given threshold but do not necessarily align these thresholds to the true underlying probability. Platt Scaling or Isotonic Regression are standard ways of calibrating a classifier. One pitfall is that if the dataset is highly imbalanced, the calibration model itself might become skewed or overfit. You need sufficient validation data across various probability ranges to perform robust calibration. For highly skewed data, sometimes you need special sampling or weighting methods to better estimate calibration curves.
In extremely imbalanced classification, are there transformations or specialized metrics beyond standard Precision–Recall that offer deeper insights?
When there is a dramatic imbalance—such as fraud detection, medical diagnosis of rare diseases, or anomaly detection—standard Precision–Recall curves can still be challenging to interpret if precision or recall saturates quickly.
One approach is to use the Precision–Recall–Gain (PR–Gain) framework, which rescales precision and recall in a way that reduces extreme skewness and can provide a smoother curve. Some practitioners also use metrics like F2-score or F0.5-score if they want to weight recall or precision more heavily, respectively. An alternative approach is to evaluate partial areas of the curve that focus on operationally relevant ranges of recall or precision (for instance, if you only care about recall above 90%, you look at that slice of the curve). This partial area approach can be more meaningful in a domain-specific context, like cancer detection, where you might demand a certain minimum recall. A pitfall of relying on any single specialized metric is that you might overlook other dimensions of performance. Sometimes you might also care about the classifier’s confidence calibration, cost sensitivity, or the distribution of predicted scores. Thus, specialized metrics should be combined with domain knowledge.
How do threshold-moving strategies differ when optimizing for ROC vs. Precision–Recall?
Altering the classification threshold changes your balance of TPR/FPR (for ROC) or Precision/Recall (for Precision–Recall). The best threshold for ROC might not be the best threshold for Precision–Recall.
With ROC, some practitioners aim for the threshold that maximizes TPR–FPR differences, such as the Youden’s J statistic (TPR + TNR – 1). This is useful when positive and negative misclassifications have relatively similar costs and class distribution is not heavily skewed. With Precision–Recall, if you care deeply about achieving high precision, you might push the threshold up to reduce false positives, but that often lowers recall. Conversely, if recall is paramount, you might lower the threshold, at the expense of increasing false positives and thus lowering precision. A pitfall is ignoring the underlying business or operational cost structure. Threshold selection should reflect real-world trade-offs: for example, how expensive is it to miss a positive instance vs. flagging a negative instance as positive? Additionally, thresholds derived from training or cross-validation sets might not transfer well if data distribution shifts in production.
When might partial AUC be more relevant than the entire area under the curve?
Partial AUC refers to computing the area under only a segment of the ROC or Precision–Recall curve. This can be especially relevant if you are interested in a particular operational regime of the classifier.
For instance, if your medical diagnosis application absolutely must achieve a recall above 0.95, you might only examine the region of the Precision–Recall curve where recall is at least 0.95. Similarly, you might focus on low False Positive Rates in applications where false alarms are costly—like an expensive intervention or a negative user experience. A possible pitfall is selecting a partial region arbitrarily without proper business context. If you choose a partial region that doesn’t reflect real-world constraints, you could over-optimize a narrow slice of performance. Another challenge is that partial AUC calculations can be more sensitive to small changes in thresholding if you are focusing on a narrow range of TPR or FPR.
How do you handle multiclass problems using ROC or Precision–Recall, and what pitfalls may arise?
ROC and Precision–Recall curves are inherently binary classification tools. For multiclass classification, standard approaches are:
One-vs-Rest (OvR): You compute separate binary curves for each class versus the rest. You can then average the curves or the AUC values across classes. One-vs-One (OvO): You compute curves for each pair of classes, which can be more computationally intensive for many classes. Micro or Macro averaging: Micro-averaging aggregates the contributions of all classes by summing up the individual true positives, false positives, and false negatives before computing metrics. Macro-averaging computes metrics independently for each class and then takes an average, giving equal weight to each class. A pitfall is that these methods can obscure which particular classes are failing. If the class distribution is skewed across multiple classes, macro-averaging can hide poor performance on a minority class. Micro-averaging can be dominated by the performance of the majority classes. You often need to look at per-class curves and metrics to truly understand performance. Another subtlety is thresholding in multiclass settings: if you rely on softmax outputs, you typically pick the highest scoring class, but some applications might require more nuanced thresholding strategies (e.g., hierarchical classification).