
ML Interview Q Series: How do you identify the presence of collinearity, and how would you describe multicollinearity?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Collinearity generally refers to a situation in which two predictor variables in a regression (or other statistical model) are highly correlated with each other. Multicollinearity extends this idea by describing a scenario in which three or more predictors exhibit strong intercorrelations. These interdependencies can cause a range of issues, such as instability in the estimated coefficients, inflated variance in the coefficient estimates, and difficulties interpreting the individual effects of predictors on the outcome.
When predictor variables are correlated, the regression model struggles to determine the unique contribution of each variable to the outcome. This can result in very large magnitudes for regression coefficients (often with unexpected signs) or very large standard errors, making it harder to draw reliable conclusions about the significance of each predictor.
Practical Methods to Detect Collinearity
One can start by examining basic pairwise correlations among variables. Although simple correlation checks can reveal collinearity between two variables, they do not capture the possibility of multiple predictors working together in ways that might cause multicollinearity. That is why a more robust approach, such as the Variance Inflation Factor (VIF), is commonly used.
VIF measures how much the variance of a regression coefficient is inflated due to collinearity with other predictors. For the i-th predictor variable X_i in a linear regression model, we can calculate VIF using the following formula.
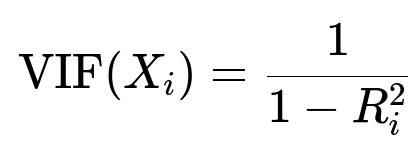
Here, R_i^2 is the coefficient of determination obtained by regressing the i-th predictor on all the other predictors in the model. A higher VIF value indicates more severe multicollinearity. As a rule of thumb:
A VIF of 1 implies no correlation with other predictors.
A VIF exceeding 5 or 10 (depending on context) often signals problematic levels of multicollinearity.
Effects of Multicollinearity
If your model suffers from multicollinearity, the resulting coefficient estimates might exhibit:
Large standard errors, making some predictors appear statistically insignificant even if they are strongly correlated with the outcome.
Changing signs or direction of effect when adding or removing correlated predictors from the model.
Sensitivity of the coefficient estimates to small perturbations in the dataset.
Approaches to Handling Collinearity
When you identify problematic collinearity or multicollinearity, there are a few strategies to mitigate it:
Removing or combining redundant predictors that carry essentially the same information.
Performing dimensionality reduction techniques such as Principal Component Analysis (PCA) to transform correlated variables into lower-dimensional uncorrelated components.
Regularization methods (like Ridge Regression) that can shrink coefficients and reduce variance in the presence of correlated predictors.
Real-World Example
In a dataset of housing prices, you might have features like overall house size, number of bedrooms, and number of bathrooms. All three variables may be correlated because as house size increases, so typically does the number of rooms. If you include all three raw features in a simple linear regression, you may encounter collinearity problems. To handle that scenario, you could either consolidate these predictors or use a regularization technique so that the redundancy does not overly inflate variances of coefficients.
Potential Pitfalls
Some pitfalls related to collinearity include:
Ignoring correlated predictors might lead to biases if the omitted variable has important relationships with both the outcome and other predictors.
Using only raw pairwise correlation checks might overlook scenarios where no two variables are highly correlated individually, but collectively they exhibit strong multicollinearity.
Over-correcting by dropping too many predictors can cause underfitting.
What Interviewers Look For
Interviewers want to see that you are aware of how high intercorrelations among features can undermine the stability and interpretability of a regression model. They also test whether you know the practical measures (such as VIF or correlation matrices) to assess the severity of this problem, and the methods to handle it in practice.
What is the Difference Between Collinearity and Multicollinearity?
Collinearity typically refers to strong correlation between exactly two variables, while multicollinearity indicates a potential set of multiple variables being intercorrelated. Though sometimes these terms are used interchangeably, the core difference is that multicollinearity captures the broader setting where multiple variables jointly create the correlation issue, which might not be observable through pairwise correlations alone.
Additional Follow-Up Questions
Could you explain the difference between using pairwise correlation checks and VIF in more detail?
Pairwise correlations only quantify the relationship between two variables at a time. If you have, for instance, three features X1, X2, and X3, pairwise correlation might indicate low correlations between (X1, X2), (X1, X3), and (X2, X3). However, these variables could still be linearly dependent in the sense that a combination of two variables might predict the third almost perfectly. VIF is designed to detect this situation because it evaluates how well each variable is explained by a linear model built from all the other variables, revealing multicollinearity that might not be evident from simple pairwise checks.
Why does multicollinearity mainly affect interpretability, and not necessarily predictions?
In many supervised learning tasks, the ultimate goal might be making accurate predictions. Even if variables are correlated, certain modeling approaches (especially regularized ones like Ridge Regression or Tree-based methods) might still produce good predictive performance. However, the coefficients in a linear model become unstable if variables are redundant, making it difficult to interpret the individual effect of any single predictor. When the model tries to allocate effect among highly correlated variables, the coefficients can swing widely with small changes in the training data, leading to large confidence intervals.
How can we reduce multicollinearity by data transformation?
Transformations such as Principal Component Analysis (PCA) help convert correlated features into a smaller number of uncorrelated components. By projecting the data onto its principal components, you capture most of the variability in fewer orthogonal dimensions. In linear models, using these components as predictors mitigates the problem of having multiple features that effectively duplicate the same information.
Can Feature Selection alone help manage collinearity?
Yes, feature selection methods can help by removing redundant or correlated predictors. Techniques like recursive feature elimination (RFE) with a linear model or a regularized model can provide insights on which features carry unique predictive value. By discarding features that do not offer additional explanatory power, you can lessen multicollinearity and potentially improve the interpretability of the model.
Is there a specific value of VIF that definitively flags multicollinearity?
Different fields adopt different cutoffs, but a VIF greater than 5 or 10 is often cited as a concern. The choice depends on how strict you want to be about removing potentially correlated features. A cutoff of 5 is more conservative, while a cutoff of 10 might be acceptable in situations where you can tolerate some degree of correlation. The more domain knowledge you have, the easier it is to set an informed threshold.
Why might we still keep some correlated variables if VIF is high?
In practice, some variables might be highly correlated, but each still has unique relationships with the outcome, especially in complex real-world data. If you drop them solely based on VIF thresholds, you might lose valuable information. Domain knowledge is crucial here. You may decide to keep correlated features if they each bring unique interpretive or predictive power, and if your final objective is not compromised by their presence.