
ML Interview Q Series: How does a multi-class classification approach differ from a multi-label classification approach?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
In multi-class classification, each instance is associated with exactly one category out of multiple possible classes. For example, if you have classes such as {cat, dog, horse}, a single image can only be labeled as one of these options. The most common technique in multi-class classification is to use a single softmax output layer, which ensures that the sum of predicted probabilities across all classes equals 1. The model aims to identify precisely one correct class.
By contrast, a multi-label classification setting allows each instance to be assigned multiple labels simultaneously. Here, for each of the possible classes, the model independently decides whether that class should be assigned or not. In the {cat, dog, horse} scenario, a single image might contain both a cat and a dog, so the labels could be assigned concurrently. Typically, a set of sigmoid outputs is used instead of a single softmax output, with each output node predicting the probability of one label independently.
Mathematical Formulations
For multi-class classification with a single correct label for each training example, one standard loss function is the categorical cross-entropy, often used with a softmax activation. If we let N be the total number of training examples and C be the total number of classes, y_{i,c} represent the ground-truth label for the i-th example in class c (1 if class c is the correct class, 0 otherwise), and hat{y}_{i,c} represent the predicted probability that the i-th example belongs to class c, then:

Here, y_{i,c} log(hat{y}_{i,c}) is the log-likelihood of the correct class probability for the i-th sample.
In multi-label classification, the common approach is to optimize a separate binary cross-entropy term for each potential label. If y_{i,c} is 1 when the i-th example has label c and 0 otherwise, and hat{y}_{i,c} is the predicted probability that example i has label c, then:
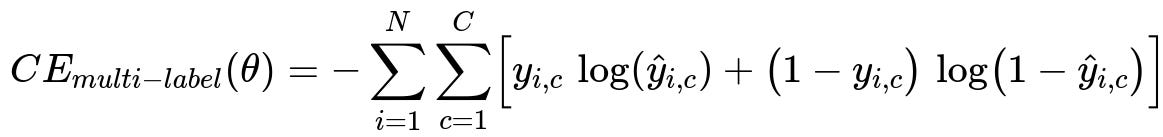
This sums the individual binary cross-entropies across all classes c for all samples i. Each class is predicted independently, enabling multiple labels to be assigned to the same instance.
Architectural Differences
In a multi-class classification network, the final layer often has C neurons (where C is the number of classes) followed by a softmax activation. This ensures that exactly one class is chosen, as the probabilities sum to 1.
In a multi-label setting, the network’s last layer typically has C output neurons, each producing an independent probability. Each neuron uses a sigmoid activation, allowing the model to output multiple “1” labels across different output neurons simultaneously.
Example Code Snippets in PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
# Example: Multi-class classification
class MultiClassNet(nn.Module):
def __init__(self, input_dim, num_classes):
super(MultiClassNet, self).__init__()
self.fc = nn.Linear(input_dim, num_classes)
def forward(self, x):
return self.fc(x) # Usually followed by softmax in the loss step
# Usage
model_mc = MultiClassNet(input_dim=10, num_classes=3)
criterion_mc = nn.CrossEntropyLoss() # Expects a single integer label per sample
optimizer = optim.SGD(model_mc.parameters(), lr=0.01)
import torch
import torch.nn as nn
import torch.optim as optim
# Example: Multi-label classification
class MultiLabelNet(nn.Module):
def __init__(self, input_dim, num_labels):
super(MultiLabelNet, self).__init__()
self.fc = nn.Linear(input_dim, num_labels)
def forward(self, x):
return torch.sigmoid(self.fc(x)) # Sigmoid outputs for each label independently
# Usage
model_ml = MultiLabelNet(input_dim=10, num_labels=3)
criterion_ml = nn.BCELoss() # Binary cross-entropy across each output node
optimizer = optim.SGD(model_ml.parameters(), lr=0.01)
In the multi-class snippet, the target is typically a single integer representing the correct class. In the multi-label snippet, the target is usually a tensor of the same dimension as the output, indicating 1 or 0 for each label.
What are some appropriate evaluation metrics for each setting?
Multi-class models often use accuracy, precision, recall, and F1-score computed per class or macro-averaged. For example, the model might be evaluated on how often it correctly picks the single best label.
Multi-label problems often require metrics that account for the possibility of partial correctness. Commonly used metrics include mean average precision, macro/micro-averaged F1-scores, the Hamming loss, and subset accuracy. Evaluations might also consider how many true labels per sample are correctly predicted, and how many predicted labels are truly present.
How do you deal with label imbalance in multi-label settings?
Class imbalance can be more pronounced in multi-label contexts because some labels may appear frequently while others occur only sporadically. Techniques include oversampling minority labels, undersampling majority labels, or using class-weight adjustments in the loss function. Another practice is to use specialized metrics like macro-averaged metrics that balance performance across all labels rather than favoring those that are more common.
Why do we not use softmax for multi-label classification?
Softmax normalizes the scores so that they sum to 1, forcing exactly one label to be chosen as the most probable. In multi-label tasks, we want to allow each label to be treated independently, enabling the selection of multiple labels simultaneously if needed. A sigmoid function at each output neuron allows for that independence.
How do correlations among labels affect multi-label classification?
When labels co-occur, purely independent predictions across labels might not suffice. If two labels frequently appear together, a model that captures label correlations can outperform one that treats them as independent. Methods like sequence modeling or specialized multi-label architectures try to learn these joint dependencies. In practice, a baseline approach often still predicts labels independently and then leverages post-processing rules or constraints that capture label correlations.
Are there pitfalls in using multi-label classification when the problem is truly multi-class?
It is a mistake to train a model in multi-label style when the real-world problem actually requires exactly one class per example. Doing so can lead to nonsensical predictions, such as assigning multiple classes to a single instance when only one is correct. Ensuring that the problem definition matches the model approach is crucial.
Below are additional follow-up questions
How do loss functions impact training in multi-class vs. multi-label classification?
Loss functions play a crucial role in guiding the learning process of a machine learning model. The choice of loss function must align with the problem type to ensure optimal training behavior.
In multi-class classification, the most common loss function is categorical cross-entropy, which is applied alongside the softmax activation function. The softmax ensures that the predicted probabilities sum to 1 across all classes, effectively forcing the model to choose a single class per instance. The loss penalizes incorrect classifications based on how confidently the model predicts incorrect labels.
In contrast, multi-label classification typically uses binary cross-entropy (BCE) as the loss function. BCE treats each label independently, applying a separate sigmoid activation function to each output unit. This allows the model to learn multiple labels per instance rather than enforcing a single-label constraint.
Key Differences:
Categorical Cross-Entropy (CCE) enforces exclusivity: By normalizing predictions, softmax forces a single label to be chosen per sample. This works well when only one class is correct.
Binary Cross-Entropy (BCE) allows independent label learning: Since sigmoid is applied separately for each class, the model can predict multiple labels with independent confidence scores.
Edge Case Considerations:
Using the wrong loss function for a problem
If BCE is used for a multi-class problem, the model may predict multiple labels for each instance, leading to ambiguous classifications.
If CCE is used for a multi-label problem, the model will be forced to choose only one label, which may not be correct in cases where multiple labels are valid.
Imbalanced class distributions
In multi-label classification, some labels might appear more frequently than others, skewing predictions toward common labels. To handle this, one can apply weighted loss functions, such as Focal Loss or Class Weighting, to balance the contributions of rare and frequent labels.
How does the choice of activation function at the output layer affect multi-class and multi-label classification?
The activation function at the output layer directly determines how predictions are interpreted.
Softmax for Multi-Class Classification: The softmax function normalizes the logits (raw outputs) into probabilities that sum to 1. This forces the model to assign the highest probability to a single class. The equation for softmax is:

where:
( z_i ) represents the logit (raw output) for class ( i )
( C ) is the total number of classes
( \sigma(z)_i ) represents the probability of class ( i )
Since softmax enforces exclusivity, it is ideal for problems where a single class per sample is correct.
Sigmoid for Multi-Label Classification: The sigmoid function transforms each logit independently into a probability score between 0 and 1:

Unlike softmax, sigmoid does not force probabilities to sum to 1. Instead, each output neuron is independently responsible for predicting whether a specific label should be assigned.

Edge Case Considerations:
Conflicting Predictions in Multi-Label Problems
Sigmoid activation means the model might predict two highly probable but conflicting labels (e.g., "Rainy" and "Sunny" in a weather classification problem). In such cases, post-processing heuristics may be required to resolve conflicts.
Softmax in Multi-Label Tasks Produces Incorrect Probabilities
If softmax is used in a multi-label setting, the probabilities for all labels will sum to 1, artificially reducing confidence scores for valid labels. This would lead to underconfidence in correct predictions when multiple labels are valid.
Can you explain the role of thresholding in multi-label classification?
Unlike multi-class classification, where the highest softmax probability directly determines the predicted label, multi-label classification requires an additional thresholding step to decide which labels are assigned.
Why is thresholding needed?
Since each class prediction is an independent probability (from the sigmoid activation), we need a threshold ( t ) to determine which labels to assign:
(\hat{y}_c = 1) if (P(y_c) > t,) and (\hat{y}_c = 0) otherwise.
Where:
(P(y_c)) is the predicted probability of class (c)
(t) is the decision threshold (commonly set to 0.5 but can be tuned)
Choosing the Right Threshold:
Fixed threshold (e.g., 0.5): The simplest approach, but it might not work well for imbalanced datasets where some labels need lower or higher thresholds.
Class-Specific Thresholds: If some classes are inherently rare (e.g., "Emergency" in medical image classification), their thresholds may need to be lower (e.g., 0.2) to avoid missing positive cases.
Adaptive thresholding: Using statistical techniques (e.g., Youden’s J statistic or Otsu’s method) to find the optimal threshold dynamically.
Edge Case Considerations:
False Positives vs. False Negatives Tradeoff
A low threshold increases recall (more labels are predicted) but might introduce false positives.
A high threshold improves precision but could lead to false negatives, missing some correct labels.
Skewed Label Distributions
In datasets where some labels are rare, a uniform threshold may be inappropriate. Rare labels might require more sensitive thresholds.
How does interpretability differ in multi-class and multi-label classification?
Interpretability is critical for understanding model decisions, debugging, and ensuring fairness. The difference in output structures affects interpretability in the following ways:
Multi-Class Models are Easier to Interpret:
Since the model predicts a single class per input, the decision-making process is straightforward.
Feature importance tools like SHAP and LIME can be used to explain why a particular class was chosen.
Multi-Label Models Require More Complex Interpretation:
Since multiple labels can be assigned, interpreting a single label’s decision requires understanding why each class was assigned or not assigned.
Labels might not be independent (e.g., in medical diagnoses, "Diabetes" and "High Blood Pressure" often co-occur), making explanation more challenging.
Visualization techniques such as Grad-CAM can help highlight regions in input data that contribute to specific labels.
Edge Case Considerations:
Overlapping Labels Make Explanations Harder
If two highly correlated labels are predicted together, it may not be clear which features influenced which label.
Misclassified Multi-Label Predictions Can Be Ambiguous
If a model fails to predict an expected label, it’s unclear whether the failure is due to:
The model not recognizing the features at all.
The decision threshold being too high.
Confounding labels affecting predictions.
How does multi-label classification relate to ranking problems?
Multi-label classification can be viewed as a ranking problem where each label receives a relevance score, and the goal is to rank relevant labels higher than irrelevant ones.
Instead of producing a hard thresholded 0/1 prediction, models can return ranked label scores.
This ranking approach is useful in recommender systems, where we want to rank the most relevant recommendations instead of strictly classifying items.
A common evaluation metric for ranking in multi-label settings is Mean Average Precision at K (mAP@K), which measures how well the relevant labels are ranked.
Edge Case Considerations:
Ranking Without Thresholds Can Still Be Useful
In search engines and recommendation systems, we might not need explicit classification—just a well-ranked list of labels.
Thresholding in Ranking Can Vary Based on Context
In some domains (e.g., fraud detection), a high precision threshold might be needed.
In news recommendation, we might allow more false positives to increase user engagement.
How do you handle dependencies among labels in multi-label classification?
Unlike multi-class classification, where all classes are mutually exclusive, multi-label classification often involves label dependencies. These dependencies can be:
Hierarchical: Some labels are subcategories of others (e.g., "Animal" → "Dog").
Correlated: Some labels tend to appear together (e.g., "Rainy" and "Cloudy").
Methods to Model Label Dependencies:
Chained Classifiers: Predict one label at a time, using previous predictions as inputs.
Graph-Based Approaches: Use Graph Neural Networks (GNNs) to learn relationships between labels.
Attention Mechanisms: Transformers can model interdependencies among labels.
Edge Case Considerations:
Ignoring dependencies may reduce accuracy.
Incorrect label propagation can amplify errors in chain-based models.