
ML Interview Q Series: How does Early Stopping function within deep learning, and why is it beneficial?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Early Stopping is a strategy used to prevent overfitting when training deep neural networks. The idea is to keep an eye on a metric such as validation loss or validation accuracy over training epochs and stop the training process once that metric ceases to improve. By doing so, the model maintains generalization strength rather than memorizing the training data excessively.
One way to see this is that each epoch fine-tunes the model parameters to reduce the training objective (often referred to as training loss), but there comes a point where further optimization no longer improves performance on unseen data. Early Stopping detects that point by monitoring a validation metric and halting before the model has the opportunity to overfit.
Overfitting and Early Stopping
Overfitting often arises when a model focuses too heavily on the training set, learning noise and unrepresentative patterns. This generally manifests as a drop in performance on the validation set while the training loss continues to decrease. Early Stopping provides a practical and straightforward method to mitigate this by interrupting training at an optimal time.
In mathematical terms, consider a training loss function, which we will call E_train(theta). Let N be the number of training samples, f(x_i; theta) the model output for sample x_i, y_i the ground truth, and l(...) a loss function such as cross-entropy. We can write:
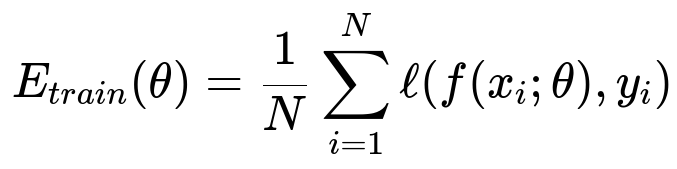
Here, theta represents all the parameters in the network. In parallel, we define a validation loss E_val(theta) over M validation samples:
Early Stopping monitors E_val(theta). When E_val(theta) has not improved for a certain number of epochs (commonly called patience), training is terminated. One may then revert to the network parameters that produced the best E_val(theta).
Mechanism of Implementation
Many frameworks like PyTorch, TensorFlow, and Keras have built-in utilities or callback functions for Early Stopping. During each epoch, the training step is run, then the model is evaluated on the validation set. This metric is tracked to determine if the model is still improving. If improvement stalls for a preset patience (for example, 5 epochs), training ends early. This approach prevents further fitting of the training data that would degrade generalization.
Below is a simple code snippet in Python using PyTorch-like pseudocode to illustrate Early Stopping logic:
import torch
class EarlyStopping:
def __init__(self, patience=5):
self.patience = patience
self.best_loss = float('inf')
self.counter = 0
self.best_model_state = None
def check(self, validation_loss, model):
if validation_loss < self.best_loss:
self.best_loss = validation_loss
self.counter = 0
self.best_model_state = model.state_dict()
else:
self.counter += 1
if self.counter >= self.patience:
return True # Signal to stop
return False
# Example usage during training
model = ... # some neural network
optimizer = ... # some optimizer
loss_function = ... # some loss function
early_stopper = EarlyStopping(patience=3)
for epoch in range(100):
# Train ...
# Compute validation_loss ...
stop = early_stopper.check(validation_loss, model)
if stop:
print("Stopping early. Reverting to best model state.")
model.load_state_dict(early_stopper.best_model_state)
break
This procedure shows a typical pattern: after each epoch, compare the validation loss to the best recorded one. If no improvement occurs for patience epochs in a row, halt training and restore the best-known weights.
Connection to Regularization
Early Stopping is a form of regularization because it limits how long we allow the model to adapt to the training set. By stopping early, the model avoids drifting into a regime where it fits irrelevant fluctuations in the training set. While it is conceptually different from weight decay, dropout, or batch normalization, it still serves the overarching purpose of improving generalization and preventing overfitting.
Balancing Patience and Practical Concerns
Choosing a patience value can be tricky. A small patience may terminate training prematurely, preventing the model from finding a deeper minimum on the training objective. A large patience may not arrest overfitting soon enough. Typically, one can run trials or watch metrics on a validation set to decide on a suitable patience. In many real-world settings, resource constraints, time budgets, and diminishing gains in validation performance guide the exact stopping criteria.
Combining Early Stopping with Other Techniques
Early Stopping often works well in combination with other techniques. For instance, you might use Early Stopping alongside learning rate schedules (e.g., reducing the learning rate on plateau), dropout, and other regularization approaches. The synergy of multiple techniques often yields better performance and stability in training deep neural networks.
Follow-up Questions
Why does Early Stopping help reduce overfitting?
Early Stopping prevents the model from continually adjusting parameters to fit noise in the training set. Instead, it halts training when the model seems to be at an optimal compromise between training accuracy and generalization performance. After that point, continuing training would only reduce training loss but harm validation metrics.
How do we pick the patience parameter effectively?
This often depends on the problem and dataset. A common practice is to monitor how quickly the validation loss typically changes. One can experiment with different patience values (like 5, 10, or 20) and choose whichever yields the best results on a validation set. Another approach is to look at a training curve to see how many epochs typically pass between improvements.
What are potential pitfalls of Early Stopping?
A key pitfall is halting too soon if the validation metric is noisy, leading to underfitting. Choosing an inappropriately short patience can prevent the model from converging. In contrast, a patience that is too long might fail to mitigate overfitting effectively. Another subtle pitfall is if the validation set does not represent the full data distribution well, leading to misleading signals about when to stop.
Can Early Stopping be used alone to guarantee generalization?
Early Stopping helps, but there is no guarantee it alone is sufficient for all tasks. Often, you still want to use additional regularization methods such as weight decay, dropout, or data augmentation to improve generalization. Early Stopping is one piece of a broader strategy that often includes hyperparameter tuning, architecture design, and data preprocessing.
How do we recover the best weights if we stop after several bad epochs?
Many Early Stopping implementations store the best set of parameters whenever the validation loss improves. If the validation loss worsens for enough epochs (beyond patience), one reverts to that set of parameters and ends training. This ensures you retain the most generalizable parameter set encountered during the training process.
Below are additional follow-up questions
What if the validation metric fluctuates significantly between epochs? How does one handle noisy validation signals with Early Stopping?
Noisy validation metrics can mislead an Early Stopping algorithm into halting training too soon or continuing it for too long. One solution is to average (or smooth) the validation metric across multiple epochs before deciding if it has improved or worsened. This smoothing can be done by:
• Using a running average of recent validation losses or accuracies. • Implementing a longer “patience” so that short-term fluctuations do not trigger early termination. • Setting a threshold-based improvement. For instance, require the validation loss to improve by at least a certain fraction to reset the patience counter.
A potential pitfall here is choosing an overly aggressive smoothing or patience that might overlook true improvements or degrade responsiveness. In real-world scenarios, one must balance reacting quickly against waiting for stable signals.
Can we use metrics other than validation loss for Early Stopping? For example, can we stop based on precision, recall, or F1 score?
It is indeed possible to rely on a variety of metrics, not just validation loss. If your target application cares more about certain performance indicators—like F1 score in a highly imbalanced classification task—then you could track that metric on the validation set. Early Stopping halts when that metric plateaus or worsens.
However, one subtlety is that optimizing indirectly for a non-differentiable metric (e.g., precision or recall) can be trickier. The training loop usually still optimizes a differentiable loss (like cross-entropy), while the Early Stopping decision might use the metric of interest. This might create a mismatch if, for instance, the model’s loss is stable or still decreasing, but your chosen metric bounces around. Therefore, be sure that your chosen stopping metric reflects genuine improvements relevant to the overall objective.
Does Early Stopping risk undertraining very large models that typically need many epochs to converge?
In some cases, especially with large-scale models such as massive language models, the best results may emerge only after extensive training. If one applies Early Stopping prematurely, the model might not reach its optimal capacity, effectively reducing its potential performance. This situation can occur if the validation set is not representative of the challenging aspects of the distribution or if the metric stabilizes early on without reflecting the improvements that might come with further training.
One way to mitigate this is to:
• Incorporate a “minimum epoch” requirement, meaning you do not even check for Early Stopping until a certain epoch count has passed. • Use multiple checkpoints and reevaluate performance on a broader or more challenging validation set to confirm whether the improvement truly ended. • Employ additional regularization methods (like weight decay, dropout, or data augmentation) to allow longer training without severe overfitting.
How is Early Stopping affected in scenarios with domain shift or concept drift?
If the data distribution changes over time, the notion of a static validation set may become invalid. Early Stopping might indicate a good point to stop for the old distribution but not necessarily for the new, shifted one. In these cases, a single validation set no longer reflects how the model will generalize in the future.
Potential approaches include: • Periodically updating or rotating the validation set to reflect the latest data distribution. • Using rolling or online metrics for early stopping in streaming contexts. • Retraining or fine-tuning the model with new data once a drift is detected, rather than relying on a single training session.
A subtle pitfall here is failing to detect concept drift in the first place. If the validation data never gets updated, the Early Stopping routine might keep training for an outdated distribution, causing poor real-world generalization.
How do we apply Early Stopping in multi-objective or multi-task learning, where several metrics matter at once?
In multi-task scenarios, you might have separate losses or metrics for each task. One common approach is to aggregate them into a single scalar (e.g., a weighted sum or a custom ranking function). Early Stopping then monitors that aggregate metric. Alternatively, you can define a rule-based system, such as halting only if none of the tasks show improvement for a certain duration.
The challenge is deciding how to weigh or prioritize different objectives. A naive solution might see improvement on one task overshadow a decline on another, potentially leading to suboptimal overall performance. Moreover, a single patience parameter might not suffice if different tasks converge at different rates. Careful tuning or dynamic weighting strategies can mitigate these complications.
If the training dataset is extremely large, is Early Stopping still beneficial or does it become less important?
Even with massive datasets, overfitting can occur. Large datasets often slow the overfitting process, but it can still happen if the model’s capacity is very high. Early Stopping can still reduce wasted computation and time by halting once meaningful gains no longer appear.
That said, in extremely large-scale training (like billions of samples), the model might find new, useful patterns for many more epochs. A potential pitfall is stopping too early, missing out on incremental gains that, at scale, translate to significant real-world performance. Thus, while Early Stopping remains beneficial, one may adjust thresholds or patience, or periodically evaluate whether the cost of additional training is justified by the modest gains in metrics.
Are there any cases where Early Stopping might be detrimental or unnecessary?
It can be detrimental in situations where:
• Training can be done extremely quickly or at minimal cost. If training is cheap, continuous training to full convergence might yield slightly better generalization without a real penalty. • A model is intended to be a base for fine-tuning. In some transfer learning or sequential learning pipelines, partial underfitting at the base model stage might hamper downstream tasks. Overly aggressive early stopping can produce a suboptimal feature extractor. • Very stable or small models that inherently do not overfit easily might not need Early Stopping. In these cases, standard training until convergence is often simpler.
How do advanced methods like “dynamic Early Stopping” or “adaptive Early Stopping” improve upon the basic approach?
In basic Early Stopping, you set a single patience value and a single validation metric to guide when to stop. More advanced methods might:
• Dynamically adjust patience based on the observed rate of improvement. For instance, if the model is still making large leaps in performance, the algorithm might extend patience. • Incorporate multiple metrics, weighting them adaptively based on how critical each metric is or how fast each metric is improving. • Use statistical tests (e.g., to confirm that an observed improvement is statistically significant above some confidence level) before deciding to halt training.
These methods reduce the chance of stopping too soon or waiting too long, but they also introduce new hyperparameters and complexities, such as how to measure significance or how to shift weights among metrics. Balancing these complexities with practical needs is a key consideration in production environments.
What happens if we rely on multiple validation sets or cross-validation for Early Stopping?
Sometimes, one may have multiple validation sets representing different sub-populations or tasks. In such a setting, you could:
• Monitor each validation set’s performance and define a joint stopping criterion, for instance, by requiring no improvement in any subset or a combined metric across subsets. • Rotate validation sets in a cross-validation manner (though this is more computationally expensive) and average the metrics to decide if training should stop. • Select one primary validation set that is most representative of your production environment while occasionally checking others.
A subtle pitfall is that focusing too much on multiple validation splits might lead to overfitting to these splits themselves, ironically. Additionally, cross-validation can substantially slow down the training process since you must evaluate the model on multiple splits at each epoch.
Is Early Stopping still relevant when using advanced optimizers or learning rate schedulers?
Yes. Even if you employ learning rate schedules (e.g., step decay, cosine annealing) or advanced optimizers (like AdamW or RMSprop), you can still overfit if the model has the capacity to memorize training data. Early Stopping complements these methods by preventing further training once the validation metric stops improving.
However, interactions can become tricky. For example, a learning rate schedule might temporarily increase validation loss right before further improvement. If your Early Stopping patience is too small, the model might stop exactly when the next phase of improvement would have started. This underlines the need to carefully tune patience in the presence of learning rate schedules to avoid missing potential performance gains.