
ML Interview Q Series: How does Non-Linear Regression differ from Linear Regression in terms of modeling and assumptions?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
A linear regression model assumes a direct linear relationship between input features and the target. In contrast, a non-linear regression model captures more flexible patterns, allowing complex relationships that are not strictly linear in form.
Linear regression has a classic representation:
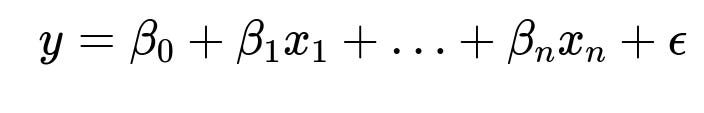
where y is the target variable, x_i are the predictor variables (for i from 1 to n), beta_i are the model coefficients, beta_0 is the intercept term, and epsilon is the error term capturing noise or unexplained variations. By "linear," we mean the model is linear in the parameters beta_i. Even if we use transformed features such as polynomials of x or logs of x, so long as the model remains a linear combination of those terms in terms of the coefficients, it is still considered a linear model.
Non-linear regression has a more general representation:
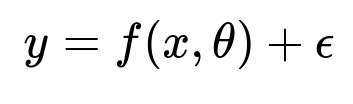
where f is any non-linear function of the predictors x and parameters theta. This f can be a polynomial, a logistic function, a neural network-based function, or any other relationship that is not strictly expressible as a linear combination of parameters. Non-linear regression provides a broader class of functional forms, allowing the model to fit patterns that are curved or more complex.
In practical implementations, linear regression methods often rely on closed-form analytical solutions (such as the Normal Equation) or simple gradient-based approaches. Non-linear regression typically requires iterative optimization procedures (like gradient descent, Gauss-Newton, or other numerical methods) that aim to approximate a global or local minimum of an often non-convex objective.
One major difference is interpretability. Linear regression yields coefficients with direct meaning about the incremental effect of each feature on the response. Non-linear models can be more challenging to interpret because their parameters might not have direct, easily parsed impacts on the target. This can be mitigated by methods like partial dependence plots or feature importance measures, but it is not as straightforward as in linear models.
Another distinction arises in computational complexity. Non-linear regressions may demand more computational resources, and they often risk getting stuck in local optima during training, whereas linear regression has a convex loss function under typical assumptions. Regularization, parameter initialization, and careful hyperparameter tuning are more critical in non-linear models to prevent overfitting and ensure stable training.
Non-linear regression can capture more diverse relationships at the cost of greater model complexity and potentially higher variance. Linear regression might be outperformed if the underlying relationship is truly non-linear, yet it is usually simpler, faster to train, and less prone to overfitting (especially if the number of features is not too large and regularization is applied).
In summary, the key differences center on the assumed relationship between predictors and target, the complexity of finding parameter estimates, the interpretability of coefficients, and the risk of overfitting. Non-linear regression excels when the data relationship is inherently complex or curved, while linear regression suffices when the relationship is reasonably well-approximated by a linear function of parameters.
Example Implementation in Python
Below is a brief illustration of fitting a linear regression model versus a non-linear model (e.g., polynomial) using Python. Although both can technically use linear solvers if the non-linearity is introduced by feature transformations, this snippet outlines the practical difference in code style:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
# Generate some synthetic non-linear data
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2 * np.sin(X) + 0.5 * np.random.randn(100)
X = X.reshape(-1, 1)
# 1) Linear regression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
y_pred_linear = lin_reg.predict(X)
# 2) Non-linear regression (polynomial)
poly = PolynomialFeatures(degree=5)
X_poly = poly.fit_transform(X)
poly_reg = LinearRegression()
poly_reg.fit(X_poly, y)
y_pred_poly = poly_reg.predict(X_poly)
# Plot
plt.scatter(X, y, label='Data')
plt.plot(X, y_pred_linear, color='red', label='Linear Fit')
plt.plot(X, y_pred_poly, color='green', label='Polynomial Fit')
plt.legend()
plt.show()
In this example, the polynomial approach introduces non-linearity by creating polynomial terms (degree=5). The resulting model, while still technically a linear model in terms of the expanded polynomial features, can capture curvature in the data that a plain linear model might miss.
Potential Follow-Up Questions
What are the typical assumptions for linear regression, and how do they compare to non-linear regression assumptions?
Linear regression usually assumes a linear relationship between features and target, normally distributed residuals, homoscedasticity (constant variance of errors), and independence of errors. Non-linear regression does not strictly require the relationship to be linear, but it often still assumes independence and a specific form of the noise distribution. In many non-linear contexts, we also assume that we have a functional form for f. Violating these assumptions can affect the reliability of model estimates, and model diagnostics are important for both linear and non-linear approaches.
When might we prefer a non-linear regression model over a linear one?
We generally opt for non-linear regression when there is evidence or domain knowledge suggesting that the data relationship is not well-captured by a linear function of coefficients. Observations of curved or more complex trends, significant errors from a linear approximation, or strong interactions among predictors often justify using non-linear methods.
Can linear regression handle non-linearity by feature engineering?
Yes, feature engineering can introduce non-linear terms (like polynomial features or interaction terms), which can still be fit with a linear solver. The model remains linear in terms of its parameters but can effectively capture certain non-linear patterns in the original features. However, when the underlying relationship is highly complex, a more general non-linear regression approach or neural network may offer more flexibility.
How do we interpret coefficients in non-linear regression?
In many non-linear regressions, individual coefficients do not have an easily interpretable meaning as in linear models. For instance, the weights in a neural network are intertwined across layers, and the impact of a single weight is not directly meaningful in isolation. Techniques like partial dependence plots or sensitivity analyses can help provide insights into how changes in predictors affect the target, but direct numeric interpretability is often less clear than in linear regression.
What are common strategies to avoid overfitting in non-linear models?
Regularization techniques (L1, L2, or structured regularization), data augmentation (when applicable), cross-validation, and early stopping in iterative optimization are common strategies. Careful selection of model capacity (like limiting the polynomial degree or controlling the complexity of a neural network) also helps prevent the model from fitting noise in the training data.