
ML Interview Q Series: How is Dictionary Learning utilized to detect anomalies in data?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Dictionary Learning is a technique that seeks to represent data points in a more compact and meaningful way by learning a set of basis vectors (the dictionary) and a set of sparse coefficients. The fundamental premise for anomaly detection is that normal samples can be reconstructed accurately from this learned dictionary, while anomalous samples exhibit higher reconstruction error because they do not align well with the dictionary that has captured “normal” patterns.
A key formulation of Dictionary Learning aims to solve an optimization that jointly learns the dictionary and the sparse representations of data. Below is a commonly used objective:
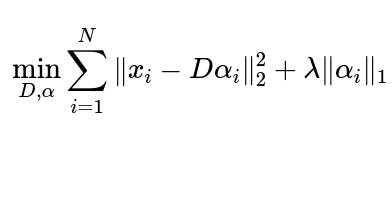
Where:
x_i refers to the i-th data sample.
D is the dictionary (a matrix whose columns are basis atoms).
alpha_i is the sparse coefficient vector for x_i.
lambda is a regularization parameter controlling the sparsity of alpha_i.
The term || x_i - D alpha_i ||_2^2 measures the reconstruction error for the i-th sample.
The term || alpha_i ||_1 enforces sparsity by penalizing the L1 norm of the coefficients, thereby encouraging many coefficient values to become zero.
After learning D and the corresponding alpha_i for normal samples, anomaly detection typically proceeds as follows:
A new data point is projected onto the learned dictionary to find its sparse coefficients.
The data point is then reconstructed using the dictionary and its sparse coefficients.
A reconstruction error is computed. If the error exceeds a chosen threshold, the sample is deemed anomalous.
Because Dictionary Learning tries to capture the “typical” or “recurring” structures found in the training data, samples containing unusual or rare patterns cannot be reconstructed well, which is precisely why these samples end up having higher reconstruction errors.
Practical Considerations
Selecting the right number of dictionary atoms is crucial. Too few atoms might cause high reconstruction error for even normal samples, whereas too many atoms can lead to overfitting, where even anomalous structures get represented with low error. The choice of the regularization parameter lambda also greatly influences the sparsity. A higher lambda forces the coefficients alpha_i to be sparser, which can make the method more sensitive to anomalies but might also reduce representational capacity for normal variations.
In practice, Dictionary Learning can be implemented using available libraries such as scikit-learn (via the DictionaryLearning class) or custom solutions with PyTorch or TensorFlow for more advanced applications. For anomaly detection scenarios, one usually trains the dictionary on purely normal samples (or mostly normal samples with few outliers removed). Afterward, the reconstruction error on new points is monitored to decide if they deviate significantly from learned patterns.
Below is a minimal Python code snippet illustrating how one might perform Dictionary Learning for anomaly detection using scikit-learn:
from sklearn.decomposition import DictionaryLearning
import numpy as np
# Suppose we have normal_data shaped (n_samples, n_features)
normal_data = np.random.rand(1000, 20)
# Train Dictionary Learning on normal data
dict_learner = DictionaryLearning(n_components=10, alpha=1.0, max_iter=500)
dict_learner.fit(normal_data)
# Now we get a new sample new_data which we suspect might be anomalous
new_data = np.random.rand(1, 20)
# Transform the new sample to obtain coefficients
coefficients = dict_learner.transform(new_data)
# Reconstruct the sample
reconstructed = np.dot(coefficients, dict_learner.components_)
# Compute reconstruction error
error = np.linalg.norm(new_data - reconstructed)
threshold = 0.5 # This is a user-defined or validated threshold
if error > threshold:
print("Sample is anomalous (High reconstruction error).")
else:
print("Sample is normal (Low reconstruction error).")
This snippet demonstrates the general flow:
You learn the dictionary on normal data.
You transform new data into its sparse coefficients.
You then reconstruct the new data from those coefficients.
Finally, you compute the reconstruction error and decide if it exceeds a threshold.
What Happens If the Data Distribution Shifts Over Time
A shift in the data distribution can cause previously learned dictionaries to become less relevant for future samples. One approach is to adaptively update the dictionary. In a streaming or online setting, online dictionary learning can be employed, which updates the dictionary incrementally as new data arrives. This ensures the dictionary remains representative of evolving normal behavior.
How Dictionary Learning Compares to Other Methods
Traditional anomaly detection approaches such as one-class SVM or isolation forests concentrate on separating the normal data from outliers. In Dictionary Learning, instead of a direct boundary-based approach, we rely on how well new samples can be reconstructed under a set of learned patterns. Sometimes a combination of dictionary-based reconstruction and boundary-based methods can be employed for more robust detection, especially if the data manifold is high-dimensional and complex.
Follow-Up Questions
How is the threshold for reconstruction error typically decided?
Threshold selection can be done by:
Using domain knowledge. For example, in industrial monitoring, the cost of a missed anomaly might be very high, so we might use a lower threshold.
Using validation data. If there is a labeled dataset with normal and anomalous samples, one can determine the threshold that yields the best metrics (like F1 score, precision-recall, etc.).
Statistically. You might examine the distribution of reconstruction errors on normal samples and set the threshold as mean error plus some multiple of the standard deviation.
Once the threshold is set, any sample whose error is above this threshold can be flagged as an anomaly.
What if the anomalies appear in the training data?
If anomalies are significantly present in the training data, the dictionary may end up learning patterns that pertain to those anomalies. As a result, those anomalies will no longer show large reconstruction errors. Potential solutions include:
Cleaning the training data to remove outliers before dictionary learning.
Using robust optimization approaches that are designed to mitigate the influence of outliers by assigning smaller weights to suspicious samples.
Incorporating an outlier-resistant penalty, which tries to identify and separate outliers during the learning process.
How do we handle high-dimensional data?
Dictionary Learning can naturally handle high-dimensional data, but the computational complexity might become large if both the dimension and the number of samples are huge. Strategies to mitigate high dimensionality include:
Dimensionality reduction techniques (e.g., PCA or autoencoders) before Dictionary Learning.
Efficient sparse coding algorithms, which scale better with data size and dimension.
Online Dictionary Learning, which updates the dictionary incrementally on chunks of data rather than processing everything at once.
Are there situations where Dictionary Learning might fail?
Dictionary Learning may fail to detect anomalies effectively if:
The dictionary is learned on a dataset that does not capture the true variation in normal data, leading to frequent misclassification of normal points as anomalies.
The learned dictionary is overcomplete or too large, causing many patterns (even anomalous ones) to be represented with low error.
There is insufficient sparsity (lambda too small), so many coefficients are nonzero, allowing any sample—whether normal or anomalous—to be approximated too easily.
Hence, careful hyperparameter tuning, proper pre-processing, and domain knowledge are crucial to ensure that Dictionary Learning remains robust for anomaly detection.
Below are additional follow-up questions
How does the choice of dictionary size influence anomaly detection performance?
A fundamental aspect of Dictionary Learning is deciding how many atoms (columns) the dictionary should have. If the dictionary is too small, it might fail to capture the variety within normal data. As a result, normal data could be reconstructed poorly, leading to a high false-positive rate for anomalies. Conversely, if the dictionary is extremely large, it may overfit. In such a scenario, the dictionary can effectively learn to reconstruct not only the normal data but also any rare or unusual patterns, causing genuine anomalies to appear normal.
In real-world settings, one might start by selecting a moderate dictionary size, then evaluate the distribution of reconstruction errors on a validation set containing normal and known anomalous samples. Adjusting the dictionary size based on the observed performance metrics (e.g., F1 score, precision, recall) can be an iterative process. It is also helpful to watch for diminishing returns: increasing the dictionary size beyond a certain point might incur higher computational costs without significant performance gains.
Potential pitfalls:
Sparse Data Regions: In many real-world applications, portions of the input space may be underrepresented during training. A too-large dictionary might attempt to adapt to those underrepresented regions without truly capturing their underlying structure.
Changing Environments: In streaming data scenarios where the underlying distribution shifts, a large dictionary might quickly fill up with outdated atoms that no longer represent the new distribution well.
What role does initialization play in Dictionary Learning for anomaly detection?
Dictionary Learning involves iterative procedures (like coordinate descent or iterative least squares) that start with an initial dictionary (often random or based on a subset of training samples). The final quality of the learned dictionary can depend on where the algorithm begins its search in parameter space.
A poor initialization might cause the algorithm to converge to a suboptimal local minimum, where certain important latent patterns in the data are not discovered. Conversely, a thoughtful initialization—such as using the data itself or using some form of clustering (e.g., K-means centers as initial atoms)—can help the learning procedure converge faster and yield a dictionary that is more representative of normal data patterns.
Potential pitfalls:
Over-Reliance on Random Seeds: In practice, one might run dictionary learning multiple times with different random seeds and pick the best result. However, if the data is large, this can be computationally expensive.
Under-Representation of Minority Subclasses: If some normal classes are rarer in the training set, random initialization might lead to an initial dictionary that doesn’t capture these rare classes well, resulting in higher false positives.
How do we handle multimodal normal data distributions in anomaly detection with Dictionary Learning?
Some datasets contain multiple “normal” modes. For instance, in a manufacturing context, there may be multiple machines, each with its own normal operating characteristics, or in image data, different lighting conditions can represent various modes of normality. If a single dictionary is learned without accounting for these multiple modes, the dictionary might fail to reflect all facets of normal data comprehensively.
One approach is to learn multiple dictionaries, each representing one mode of the data. Another approach is to train a single overcomplete dictionary with enough atoms to represent all normal modes. In either case, you must ensure that data from each mode is sufficiently present in the training set so that it can learn to reconstruct those variations accurately.
Potential pitfalls:
Mode Collapse: If the algorithm lumps several modes together, it might systematically misrepresent one of them. Samples from that mode could then appear anomalous even though they’re normal.
Complex Decision Boundary: With multiple modes, threshold setting for reconstruction error becomes trickier. One might need different thresholds per mode or a more sophisticated approach that recognizes different error distributions.
When would an online or incremental Dictionary Learning approach be preferable?
Online (or incremental) Dictionary Learning updates the dictionary in small batches as new data arrives, rather than learning from all data at once. This is especially relevant in streaming or continually evolving environments, such as real-time monitoring of servers or IoT sensor data from various locations.
Online Dictionary Learning allows you to:
Adapt the dictionary to gradual changes in the normal data distribution.
Handle large datasets where batch dictionary learning becomes infeasible due to memory constraints.
Potentially detect concept drift sooner, as the dictionary is updated continuously.
Potential pitfalls:
Over-Adapting to Noise: If the stream contains many sudden spikes or short-lived anomalies, the dictionary might adapt too quickly and treat them as normal, thereby failing to flag them.
Hyperparameter Complexity: Aside from the usual hyperparameters (dictionary size, sparsity penalty), one must also set the update frequency and the learning rate for online methods. Poor choices can cause the dictionary to either fail to learn meaningful updates or to become too plastic, rapidly forgetting older but still relevant patterns.
Could Dictionary Learning be combined with other anomaly detection methods?
Yes. Sometimes Dictionary Learning alone may not be sufficient to separate normal points from anomalies if the data manifold is extremely complex or if the reconstruction error distribution is heavily overlapping for normal and abnormal samples. Combining Dictionary Learning with other algorithms can lead to robust results. For example, one might:
Use Dictionary Learning to generate features (the sparse coefficients) and then feed these features into a standard anomaly detection model like Isolation Forest or One-Class SVM.
Apply dimensionality reduction via Dictionary Learning, then use a robust clustering approach to identify points that do not belong to any cluster of normal data.
Potential pitfalls:
Added Complexity: Combining multiple methods means more hyperparameters and a more complex pipeline, making it harder to interpret results and tune the system.
Overfitting in Two Stages: If both Dictionary Learning and the secondary method overfit, you might end up with a pipeline that is overly sensitive to random fluctuations and fails to generalize.
How does Dictionary Learning compare to deep learning approaches (e.g., autoencoders) for anomaly detection?
Dictionary Learning and autoencoders share a conceptual similarity: both try to reconstruct inputs, and anomalies are detected via high reconstruction error. While Dictionary Learning enforces sparsity and learns a set of basis vectors in a linear fashion, autoencoders can learn nonlinear transformations by leveraging multiple hidden layers.
Dictionary Learning is often more interpretable, because the learned dictionary atoms can sometimes be visualized or understood individually. Autoencoders, on the other hand, can capture more complex data manifolds with deeper architectures, but they may require much larger training sets and might be harder to interpret.
Potential pitfalls:
Limited Nonlinearity: If the underlying data has strong nonlinear relationships, a purely linear dictionary might struggle to reconstruct these patterns, thus potentially over-flagging normal data as anomalies.
Over-Complex Models: Deep autoencoders might be prone to overfitting, especially with limited data, making them reconstruct anomalies with low error. In contrast, Dictionary Learning with strong sparsity can be more robust in scenarios with smaller datasets.
How do you debug a case where Dictionary Learning results in too many false positives?
Debugging an anomaly detection pipeline using Dictionary Learning often involves iterating through the following checkpoints:
Inspect Reconstruction Errors on Normal Data: Plot the distribution of reconstruction errors on known normal samples. If many normal samples have unexpectedly high errors, possible reasons include:
The dictionary is too small or not capturing all variations.
The regularization parameter lambda is too large, forcing extreme sparsity and diminishing the reconstruction power.
Check the Dictionary Atoms: Visualize (if feasible) or examine the dictionary atoms to see if they align with meaningful features of the data. If they look random or repetitive, the learning process might have converged to a poor local minimum.
Revisit Preprocessing: Ensure data is scaled or normalized appropriately. If certain features have skewed distributions, they can dominate reconstruction errors.
Evaluate the Training Set Quality: If the training set has unrepresentative or noisy data, the learned dictionary might fail to generalize. Clean outliers or restructure the sampling strategy for training.
Potential pitfalls:
Using an Inappropriate Loss Metric: If your data is not well-suited for an L2-norm-based reconstruction error, consider using other metrics or transformations that reflect the domain more accurately.
Overlooking Latent Confounding Factors: Sometimes, external variables (like temperature, time of day, sensor calibration) can affect reconstruction errors, so ignoring them can skew your detection results.