
ML Interview Q Series: How would you design a ML system to reduce missing or incorrect orders at DoorDash?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
A key challenge in the online food-delivery domain is preventing mistakes such as missing items or an entirely inaccurate order from being delivered to a customer. The fundamental question is how to use machine learning to lower the frequency of these errors. A possible strategy is to create a supervised learning pipeline that flags orders at higher risk of mistakes and prompts interventions, either by human review, additional verification, or automatic notifications to the restaurant or delivery personnel.
Identifying the Learning Problem
The nature of the problem is typically a classification task, where the model attempts to distinguish between orders that are likely to be correct and those that are likely to be erroneous. From a data science perspective, each order could be accompanied by a label indicating whether it was correct or incorrect/missing an item. Over time, these outcomes can be recorded from customer complaints, support tickets, or refunds requested.
Data Collection and Feature Engineering
Building the right dataset begins with collecting a broad range of attributes for each order. Examples of these attributes include:
Order details such as the list of items, their quantities, and special instructions.
Historical patterns of similar orders from the same restaurant, time of day, or location.
Restaurant’s historical accuracy performance.
Delivery agent’s history (if any correlation exists with missing or incorrect deliveries).
Time-based factors such as surge hours or staff turnover schedules.
Feature engineering might involve capturing how often a specific item is reported missing, how complex the order is (number of special instructions), or the typical accuracy record of a restaurant during busy hours. Additional features can come from user behavior: how often does a particular user request complex modifications, and what is the usual error rate for those modifications?
Model Selection and Training
A wide range of models could potentially be suitable for this kind of classification. These might include gradient-boosted decision trees, random forests, or deep neural networks if the data volume is substantial. For a typical mid-scale system, tree-based ensembles often perform well because of their ability to handle mixed data types and complex feature interactions.
A straightforward supervised training approach is to define a binary classification label. Suppose y_i is 1 if the order ended up having an issue (missing or wrong item) and 0 if the order was correct. A standard cross-entropy loss can be used to train the model:
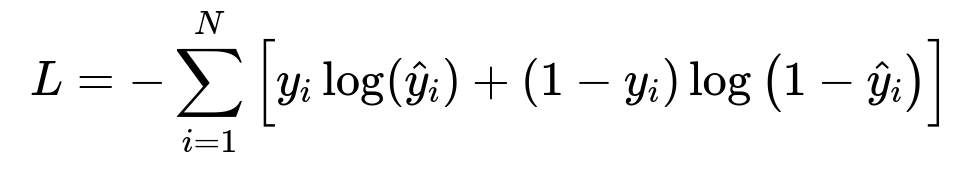
where:
L is the total loss function computed over N training examples.
y_i is the true label for the i-th training example in text format: (1 if erroneous order, 0 if correct).
hat{y}_i is the predicted probability for the i-th example in text format: (probability that the order is erroneous).
The goal is to find model parameters that minimize L across all training examples.
By minimizing this loss, the model learns to assign high probability to orders it believes to be at risk of errors and low probability otherwise.
Model Evaluation and Metrics
Traditional classification metrics help measure performance. Precision can indicate among flagged orders, how many truly had issues. Recall can measure what fraction of the truly problematic orders get flagged. A balanced measure like the F1 score might be used if one wants to weigh precision and recall equally. However, certain business considerations may favor recall over precision. If the cost of an unflagged wrong order is higher than an incorrectly flagged order, the system could be tuned to prioritize recall, possibly at the expense of precision.
In real-world scenarios, an imbalanced dataset is common, as only a relatively small fraction of orders may be incorrect. Techniques such as class weighting, oversampling of the minority class, or undersampling of the majority class can be applied to ensure that the model does not always predict “no error.”
Real-Time Inference and System Architecture
In a production setting, the model might run during the order checkout process. A real-time pipeline can be established, where newly placed orders are scored by the model. Orders with a high predicted risk of mistakes might trigger alerts or auto-verification steps:
Automated verification: The system can ask the restaurant to confirm each item if it detects a suspiciously large or complex order.
Human review: If the probability of an error surpasses a certain threshold, a customer service representative might manually verify details with the customer or the restaurant.
Customer confirmation: For extremely high-risk cases, the system could prompt a final reconfirmation from the user before order placement is finalized.
Monitoring, Feedback, and Iterative Refinement
After deploying the model, it is crucial to track its performance over time and compare outcomes with real-world data (e.g., support tickets, refunds). If the model’s accuracy declines, this might indicate data drift, changing restaurant behaviors, or seasonal variations in ordering patterns. Regular model retraining and hyperparameter tuning can keep performance optimal.
Example Code Snippet in Python
Below is a simplified example showing how one might use a random forest classifier in Python (using scikit-learn) to train a model that flags problematic orders. This is purely illustrative:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# Assume df has columns like 'items_count', 'restaurant_error_rate',
# 'time_of_day', 'historical_user_modifications', 'label' etc.
df = pd.read_csv('orders.csv')
# Extract features and label
X = df.drop('label', axis=1)
y = df['label']
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
stratify=y,
random_state=42)
# Create and train model
model = RandomForestClassifier(n_estimators=100,
max_depth=10,
class_weight='balanced',
random_state=42)
model.fit(X_train, y_train)
# Evaluate model
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
This simplistic snippet demonstrates the basic data split, training, and evaluation steps. In production, there would be additional complexities, including advanced feature engineering, pipeline orchestration, real-time inference endpoints, and continuous model monitoring.
Potential Follow-up Question: Data Imbalance
How can we deal with the situation where only a small fraction of orders end up having errors, creating a highly imbalanced dataset?
One approach is to apply class-weighting in the loss function, which instructs the model to pay relatively more attention to the minority class (orders with errors) than to the majority class. Oversampling techniques like SMOTE can generate synthetic samples to augment the minority class. Undersampling the majority class is also possible, though it can lead to loss of potentially informative data. Another strategy is to adjust decision thresholds after the model predicts probabilities. By setting a lower threshold for classifying an order as “high-risk,” recall is increased at the possible expense of precision.
Potential Follow-up Question: False Positives vs. False Negatives
Which type of misclassification is more costly, and how would you incorporate that into the model design?
In many scenarios, a false negative (failing to flag an actually erroneous order) can be worse because it leads directly to a poor customer experience and potential refunds. A false positive (flagging a correct order as suspicious) might be less damaging because it only adds a bit of friction (e.g., an extra verification step). One can integrate a cost-sensitive approach where the model’s objective is weighted based on the relative cost of each error type. Alternatively, the decision threshold can be tuned so that the system errs on the side of flagging suspicious orders more often, boosting recall at the expense of precision.
Potential Follow-up Question: Model Interpretability
How can we ensure stakeholders trust the model’s decisions and maintain interpretability?
This system might have serious business implications, so stakeholders may want explanations when the model flags certain orders. Methods like SHAP (SHapley Additive exPlanations) or feature importance plots can help clarify which factors most contributed to a particular prediction. If a model is more complex (e.g., a large ensemble or deep neural network), interpretability tools become even more important. Ensuring that restaurant owners, delivery personnel, and customer service teams understand the basics of why some orders get flagged can foster trust and cooperation.
Potential Follow-up Question: Continuous Improvement and A/B Testing
How do you maintain and improve the system over time?
Regular A/B testing can measure if changes in model configuration or feature sets improve performance. By exposing a small percentage of orders to an updated model and comparing outcomes—like the rate of valid complaints or the number of times the model accurately predicts an issue—against orders handled by the existing model, you can quantify performance gains or declines. This process should be repeated whenever significant changes or retraining are performed, especially if new data sources or major feature engineering updates are introduced.
Potential Follow-up Question: Edge Cases
What are some edge cases that could break the system?
Unusually large or complex orders with special instructions that do not resemble anything in the training data can cause the model to be uncertain. A restaurant’s sudden drop in quality control due to unforeseen events (staff shortage, supply chain issues) might not be captured in historical data. Rapid changes in user behavior, such as a surge of new users or changes in ordering habits during major events, can also lead to distribution shifts. Designing a robust monitoring system that tracks incoming data distributions compared to training data distributions can help detect these shifts early.
Below are additional follow-up questions
How do you handle ephemeral or rapidly changing menus when your model relies on historical data about specific dishes?
Sudden menu changes—such as limited-time offers or seasonal items—can invalidate certain features in your dataset if the item no longer exists or if it appears for the first time without historical statistics. This situation poses data distribution shifts that your model may not have encountered during training.
Potential Pitfalls and Real-World Issues
Missing Historical Data: A brand-new menu item may appear frequently, but because there is no existing information about the restaurant’s error rate for that item, the model might be uncertain about its risk level.
Model Overreaction: If new items are not recognized, the model might inappropriately flag them as high-risk by default, increasing false positives.
Data Shift: When an entire section of the menu changes suddenly (for instance, a restaurant revamps its offerings), the model’s underlying assumptions may no longer hold.
Possible Strategies
Adaptive Feature Engineering: Use item-level embeddings or vector representations where the system can generalize from “similar” items, so that new additions to the menu are not treated completely blindly.
Real-Time Updates: If your platform can detect new menu entries, you might immediately adjust features (e.g., set a default vector or baseline risk), and then update as soon as real user feedback or order outcomes become available.
Cold-Start Mechanisms: Employ a fallback heuristic for brand-new items, such as a mid-range default risk estimate, and refine the model’s estimates over time once enough data is collected.
How can you address multi-lingual issues if restaurants or customers provide order details or special instructions in various languages?
When user or restaurant-provided data arrives in multiple languages, the feature pipeline might fail to parse important clues indicating the complexity of an order. For instance, a special instruction in Spanish might be misread if the system was trained only on English data.
Potential Pitfalls and Real-World Issues
Misinterpretation or Loss of Text Features: If text-based features are used to identify risky orders (e.g., “no onions, gluten-free bun”), a mismatch in language can lead to losing that information.
Skewed Performance: The model may underperform for non-English data, creating potential fairness issues among different customer demographics.
Possible Strategies
Language Detection: Automatically detect the language of the text and route it to the appropriate language model or translation system before feature extraction.
Multi-lingual NLP Models: Leverage pre-trained multi-lingual embeddings (e.g., from HuggingFace or multilingual BERT) to generate consistent representations across languages.
Localization in the Application: Encourage standardized note-taking formats or maintain a curated dictionary of common modifications in multiple languages, so the system can better capture critical information.
What considerations arise around data privacy and compliance when collecting order data and user information for model training?
Any system storing user information and order details for machine learning must handle regulatory issues around personal data. Laws like GDPR and CCPA require companies to allow users to opt-out of data collection or request data deletion.
Potential Pitfalls and Real-World Issues
Compliance Violations: Storing personal data without user consent or in unencrypted form may violate privacy regulations.
Model Retraining After Deletion Requests: If a user requests the removal of their data, you must ensure that the model can either be retrained without that data or guarantee that the user’s data does not remain embedded in the model weights.
Over-Collecting Data: Gathering excessive personal details not strictly needed for error detection can raise ethical and legal concerns.
Possible Strategies
Anonymization and Aggregation: Replace personal identifiers (names, addresses) with abstracted or hashed identifiers to protect user privacy while retaining the model’s utility.
Differential Privacy: Implement techniques that add controlled noise, ensuring no single user’s data can be uniquely re-identified from the model’s outputs.
Privacy-Aware Architecture: Keep sensitive PII (Personally Identifiable Information) separate from the data pipeline that feeds into the modeling process, so the model operates only on minimal necessary features.
How do you ensure that your offline metrics (e.g., F1 score, precision, recall on a validation set) translate effectively into real-world outcomes once deployed?
Models might show strong performance on validation or cross-validation metrics but fail to deliver the same improvements in production due to a mismatch between offline and online conditions.
Potential Pitfalls and Real-World Issues
Dataset Shift: The production environment may include new customer behavior, restaurant changes, or fluctuations in ordering patterns that were not reflected in the training/validation data.
Proxy Labels: Offline labels (e.g., user complaints) might not capture every scenario of an incorrect order, causing the model to underrepresent or overrepresent certain error patterns.
User Behavior Changes: Once the system begins flagging orders, it might alter how restaurants package items or how customers submit orders (users might be more careful with their modifications), leading to new data distributions.
Possible Strategies
A/B Testing: Continuously test the model in a controlled manner, measuring the real-world reduction in complaints or refunds compared to a control group.
Online Feedback Loops: Integrate near-real-time feedback from user complaints or support tickets to adjust or retrain the model.
Regular Calibration Checks: Monitor predicted probabilities vs. actual outcomes. If calibration drifts, re-calibrate or retrain with updated data.
How could you incorporate an unsupervised or semi-supervised approach if you don’t have explicit labels for every single order?
Not all incorrect orders are reported, and some orders that are labeled correct might be unknown false negatives. A purely supervised approach can be hampered if only a small fraction of errors is clearly labeled.
Potential Pitfalls and Real-World Issues
Incomplete Labels: Many “correct” orders might actually have minor errors that went unreported, distorting the training signal.
High Labeling Costs: Reliance on user complaints or manual review is expensive and still might miss many cases.
Possible Strategies
Anomaly Detection: Use an unsupervised anomaly detection method to highlight orders that deviate sharply from typical patterns (e.g., extremely large item count, unusual combination of items).
Self-Training: Leverage a large pool of unlabeled examples and label them with a current model’s predictions; then use those pseudo-labels to retrain or refine the model.
Active Learning: Have the model request explicit verification for only the most uncertain or “borderline” orders, thus improving the labeling strategy without needing to label everything.
How can you manage system performance and latency constraints if you want real-time scoring for every single order placed on the platform?
Real-time inference might be necessary to flag errors before the order is confirmed, but large or complex models can have high latency, potentially slowing the user checkout experience.
Potential Pitfalls and Real-World Issues
High Throughput: During peak ordering times, you might process thousands of orders per second. A computationally expensive model can create bottlenecks.
Memory Footprint: Storing large model parameters in memory for quick lookups can be challenging if you deploy many models or large ensemble methods.
User Experience: Any noticeable delay in the ordering funnel can hurt the customer’s overall experience and cause checkout abandonment.
Possible Strategies
Model Optimization: Techniques such as model quantization, distillation to smaller neural nets, or more efficient tree-based models with optimized inference paths can reduce latency.
Edge Caching: Deploy the model closer to the user or restaurant’s region, reducing network latency and allowing faster response times.
Hybrid Approaches: Use a simpler model for immediate triage (fast inference) and only trigger a more complex model for borderline or suspicious cases if needed.
How do you handle the trade-off between minimizing errors (missing or wrong items) and optimizing other objectives, such as delivery speed or cost?
In practice, the business might not focus solely on reducing errors if that significantly slows down order processing or increases operational costs. There is often a multi-objective optimization at play.
Potential Pitfalls and Real-World Issues
Excessive Verification: If you try too hard to eliminate errors, you might slow down the entire process with frequent manual checks.
Conflicting KPIs: Departments responsible for user satisfaction push for fewer errors, while logistics teams push for faster or cheaper deliveries.
Possible Strategies
Weighted Objective Functions: In your decision-making pipeline, incorporate separate reward terms for accuracy, speed, and cost. You then choose trade-off parameters that reflect business priorities.
Tiered Risk Thresholds: Set different thresholds for flagging orders based on time constraints or other operational metrics. Low-latency scenarios might use a higher threshold, while less time-sensitive scenarios can afford a more thorough check.
Cost-Sensitive Learning: Build a cost matrix that includes the penalty for a wrong item vs. the penalty for the extra time or resources used to verify an order. Adjust model predictions accordingly.
Can you utilize external signals—like restaurant inventory data or driver feedback—to further improve accuracy?
Sometimes restaurants run out of certain ingredients, or drivers notice mistakes at pick-up. These external signals can provide valuable real-time feedback loops.
Potential Pitfalls and Real-World Issues
Reliability of External Data: Restaurant inventory systems might not be accurate if employees forget to update them. Driver feedback might be sparse or subjective.
Data Integration Complexity: Merging multiple data sources in real time can introduce engineering challenges, especially if they come in different formats or at different times.
Possible Strategies
Multimodal Data Integration: Combine textual inventory logs, scanning receipts, or mobile app driver feedback to refine predictions. For example, if an ingredient is nearly out of stock, the risk of a missing item might rise.
Rewarding Timely Feedback: Encourage or incentivize drivers to mark incomplete or obviously incorrect orders when they pick them up, which can be fed back into a near real-time system for quicker intervention.
Monitoring Data Quality: Track the accuracy of each external data source. If a particular restaurant rarely updates its inventory, weigh its real-time signals less.
What steps can you take if you discover that the model’s predictions vary significantly across different geographical regions or restaurant types?
Performance can differ because of cultural ordering habits, local menu variations, or differences in restaurant staffing levels. A one-size-fits-all approach may cause high variance in error rates across regions.
Potential Pitfalls and Real-World Issues
Excessive Complexity: Building a separate model for each region or restaurant type might become unmanageable if there are too many segments.
Data Fragmentation: Segmentation can split your dataset into smaller subsets, making training less robust if certain regions have limited data.
Possible Strategies
Hierarchical Modeling: Train a global model for all orders, but include region- or restaurant-specific embeddings or features that capture local nuances. This way, the model can still generalize while accounting for local differences.
Transfer Learning: For new regions with insufficient data, start with a global model as the base and fine-tune it with region-specific data.
Performance Monitoring: Maintain region-level or segment-level dashboards. If a specific segment’s performance lags behind, drill down into possible reasons (e.g., data quality, unique menu items, or a different labeling process).