
ML Interview Q Series: How would you measure and evaluate a LinkedIn messaging feature's effectiveness without an A/B test?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
Launching a feature without the ability to run a controlled experiment (like an A/B test) often requires alternative data-driven strategies to assess effectiveness. The goal is to understand whether the messaging feature results in positive outcomes for candidates, recruiters, and the platform as a whole. Below are several high-level approaches and considerations that can be combined for a well-rounded analysis.
Pre-Post Analysis
A common approach is to compare relevant metrics before and after the feature launch. For instance, one might look at changes in:
Messaging usage: Are more candidates messaging recruiters post-launch?
Candidate-recruiter interaction frequency: Has recruiter responsiveness changed?
Hiring success rate or time-to-hire: Are jobs being filled faster or at a higher rate?
Candidate satisfaction: Are there fewer complaints or do surveys indicate improvements in user sentiment?
While a pre-post analysis is straightforward, it can be confounded by external factors such as seasonal variations in hiring activity or macroeconomic changes.
Difference-in-Differences (If a Control Group Can Be Found)
If there is a possibility of constructing a quasi-experimental setup with a control group (for example, a segment of the user population where the feature was rolled out later or where similar messaging is not available), a difference-in-differences method can be employed. The core formula for difference-in-differences is often expressed as follows:
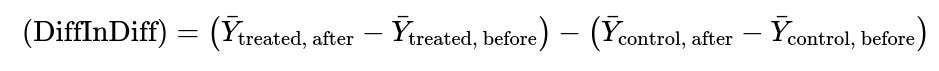
Here, Y_{treated, before} is the average metric of interest (for example, hiring rates or message response rates) for the group that receives the feature before it is introduced, and Y_{treated, after} is the average metric for the same group after the feature is introduced. The same logic applies to the control group. By subtracting the difference in the control group from the difference in the treated group, we reduce confounding effects that affect all groups equally over time. However, difference-in-differences requires a parallel trends assumption, implying both groups would have followed similar outcome trends in the absence of the feature.
Synthetic Control
If there is no natural control group, a synthetic control method might be used, where a weighted combination of units that did not receive the feature (or some historical period without the feature) is used to mimic the “treated” group’s pre-intervention trajectory. One could compare the metric evolution of the “treated” group to this artificially constructed control over the same time period.
Observational Techniques
Regression-based models that control for user or job posting attributes can help isolate the feature’s impact if one can incorporate relevant covariates such as region, job type, candidate profile, and time-of-year effects. Including these factors in a regression allows the model to partially adjust for confounders, though perfect isolation of causal impact is often challenging.
Metrics of Interest
It’s vital to choose carefully what metrics to track:
Engagement metrics: Number of messages sent, read receipts, average response times.
Outcome metrics: Conversion from interview to offer, duration from application to final decision, rate of successful placements.
Satisfaction metrics: Candidate Net Promoter Score (NPS), recruiter feedback, user surveys.
Overall platform health metrics: Could include changes in churn rate (for job seekers or recruiters), fluctuations in job postings, or other second-order effects.
Potential Confounding Factors
In real-world settings, new product releases rarely occur in isolation. For instance, a new marketing campaign might coincide with the feature launch, or seasonal trends in job hiring might mask or exaggerate the feature’s impact. The above methods (difference-in-differences, synthetic controls, regression-based controls) aim to reduce these confounding effects, but thorough analysis often requires domain knowledge and careful selection of relevant covariates.
Follow-up Question: How Do We Handle Selection Bias?
Selection bias arises if the candidates or recruiters who use the new messaging feature differ systematically from those who do not. In an A/B test, random assignment helps mitigate this issue, but in the absence of randomization, we can address selection bias by:
Identifying relevant user characteristics, such as job role, industry, experience level, or activity patterns, and incorporating them as control variables in statistical models.
Matching or stratifying users based on certain attributes to compare similar subpopulations.
Using propensity score matching if the usage is optional, thereby creating pairs (or groups) of users with similar propensity to use the feature but who end up either using or not using it.
These methods help isolate the effect of the feature by ensuring that the treated and control groups are comparable in terms of observable characteristics.
Follow-up Question: How Can We Account for Seasonal or Macro-Level Changes?
Observing a change in metrics pre- and post-launch could be misleading if there is an economic downturn or some seasonality in hiring. Possibilities include:
Fitting a time-series model (for example, ARIMA or a regression with time-based covariates) that explicitly captures seasonal and trend components.
Checking the same time period in the prior year and comparing year-over-year changes. This helps determine whether the observed effect is truly due to the feature or is in line with normal seasonal swings.
Including external signals (such as national job market data) to ensure fluctuations in job availability or economic conditions are accounted for in the model.
Follow-up Question: What If Only One Version of the Product Exists and Everyone Has It?
When the entire user population receives the feature, constructing a control group is more difficult. Quasi-experimental approaches such as the synthetic control method can be used if you have historical data from a time period prior to the feature’s availability. You could:
Identify a set of metrics from a time window before the feature launch.
Build a synthetic “control” using historical metrics or subpopulations that are unlikely to be influenced by the feature (for example, a parallel product area that remains unaffected).
Compare the observed trajectory of key metrics to what the synthetic control predicts those metrics would have been without the feature.
Follow-up Question: Are There Practical Considerations for Implementation?
Practical considerations often involve data infrastructure and organizational readiness. A few common issues are:
Logging and Data Quality: Ensure the platform is accurately logging messages, timestamps, and participant identifiers so that analyses are reliable.
Feature Rollout Timing: Record the exact date and time of the feature launch to enable accurate pre-post segmentation.
User Survey Mechanisms: Set up user feedback channels (e.g., post-interview surveys) to gather qualitative insights on how people perceive the new messaging feature.
Cross-Functional Collaboration: Work closely with product managers and engineers to interpret any unexpected metrics or changes in user behavior that arise due to platform updates unrelated to the messaging feature.
Follow-up Question: How Can We Further Validate Observed Effects?
Validation is critical to confirm the robustness of conclusions. Techniques include:
Performing multiple analyses, such as a difference-in-differences approach and a regression controlling for user demographics, to see if they yield consistent results.
Checking internal validity by analyzing subgroups, like focusing only on a specific region or job category. If the feature should theoretically improve communication in all categories, seeing uniform improvements lends support to the hypothesis.
Triangulating with qualitative data: Conducting user interviews or surveys to see whether they align with the quantitative metrics.
By combining these strategies, it becomes possible to gain confidence in whether the feature truly drives positive outcomes, even in the absence of a formal A/B testing framework.
Below are additional follow-up questions
How Do We Ensure the New Feature Does Not Create Unintended Negative Outcomes for Recruiters?
If candidates start sending many direct messages to recruiters, there is a possibility of overwhelming recruiter inboxes, leading to delayed response times or an overall negative experience for recruiters. In such a scenario, user adoption might look like a success from a candidate standpoint, but recruiters could become less engaged or dissatisfied.
To address this, you can:
Monitor recruiter load metrics: Track the average number of candidate messages per recruiter, frequency of recruiter logins, and any changes in time-to-response.
Conduct recruiter satisfaction surveys: Investigate if recruiters are finding value in responding to these direct messages or if they consider it a distraction.
Observe response rate trends: If a significant drop in recruiter response rate is detected over time, consider refining the feature to reduce message volume (for example, by limiting message frequency or providing recruiters with automated templated responses).
Look for churn or decreased platform engagement: Recruiters might reduce or withdraw their involvement on the platform if the feature is burdensome.
Potential pitfalls include missing the early warning signs that recruiters are overwhelmed (e.g., surge in unread messages, rising complaint tickets), which can escalate quickly if unaddressed.
Could the Feature Incentivize Unproductive Behavior Among Candidates?
Some candidates might exploit this feature by spamming or sending low-effort messages to multiple recruiters, hoping to get any possible traction on their job search. This can degrade the overall quality of the platform experience, leading to noise and frustration.
Possible mitigation:
Introduce throttling or rate limits: Restrict the number of messages a candidate can send within a certain time.
Implement spam detection: Use text classification or keyword matching to identify repetitive low-value messages.
Design friction points: Requiring a minimum profile completeness or an explicit reason for contacting the recruiter can weed out spammy behavior.
Assess message quality: Conduct qualitative sampling or build automated language quality checks to determine if messages are relevant to the position.
Edge cases can appear if well-intentioned candidates are mistakenly flagged as spam, which might deter legitimate usage. This requires nuanced solutions, like human review or advanced ML techniques to reduce false positives.
How Do We Detect and Analyze Long-Term User Fatigue?
While initial metrics might show an uptick in messaging, over time, both recruiters and candidates could become fatigued if the novelty wears off or the value proposition isn’t sustained.
Ways to detect and analyze:
Track monthly active usage patterns: Look for a decline in monthly messages per user after a certain period.
Examine open and response rates over time: A gradual drop may indicate diminishing effectiveness or interest.
Compare retention metrics: If users who heavily use the feature are more likely to disengage in subsequent months, you need deeper analysis into whether the feature is contributing to overall burnout.
A subtle pitfall is attributing fatigue to the feature when, in fact, macro factors (seasonal changes or market slowdowns) might be responsible. Proper time-series analysis or difference-in-differences with historical data can help isolate the feature’s impact.
What If Data Logging Has Gaps or Inconsistencies?
Any new feature introduces fresh data pipelines that may not be fully stable at launch, risking missing or duplicated logs. Inconsistencies in data can undermine the reliability of insights.
Strategies to address this:
Validate logging events: Monitor real-time dashboards to spot irregularities (e.g., sudden zero counts for an event type).
Cross-reference multiple data sources: Compare app-side telemetry with server-side logs to ensure alignment.
Maintain a fallback dataset: In early-stage features, collect raw event logs (if possible) that can be re-processed if an issue arises with the primary data pipeline.
Document known data issues: Keep a centralized record of times and dates when data anomalies occurred to avoid misinterpretations.
A critical edge case is if certain messages never get recorded or if double counting occurs. These errors might skew analyses, leading to misguided product decisions.
How Do We Segment by Different User Personas?
Users are not homogeneous. For example, senior-level product managers might behave differently from entry-level engineers. Similarly, smaller companies might respond differently than larger organizations.
Deep segmentation involves:
Identifying relevant attributes: Industry, job position, experience level, company size, geographic region.
Measuring usage and outcome metrics within each segment: Comparing message-sending frequency and response rates across distinct segments can reveal which user groups benefit most.
Checking for retention and long-term success: Some segments might show a short-term spike in engagement but revert quickly to older channels if they find the feature less useful.
A hidden pitfall could be over-segmentation, where sample sizes become too small for reliable conclusions. Balancing granularity with statistical power is essential.
How Do We Ensure Causality and Not Just Correlation?
Without a formal randomized experiment, it can be difficult to claim that the new messaging feature caused a particular outcome (like shorter time-to-hire). The risk is that you might measure a correlation influenced by other factors, such as strong job market demand or an influx of new LinkedIn users.
To strengthen causal inference:
Use quasi-experimental designs (if any partial rollout or natural experiment occurred).
Build control variables into regression models: Controlling for user type, historical usage patterns, and macroeconomic indicators can reduce omitted variable bias.
Perform multiple complementary analyses: For instance, difference-in-differences with synthetic controls can reinforce or contradict a standard regression analysis. Consistency across methods boosts confidence in a causal relationship.
A common pitfall is claiming causality prematurely, which can lead to over-optimistic product decisions or resource allocations.
How Can We Estimate the Return on Investment (ROI) for This Feature?
Organizations will want to know if the additional engineering and product development costs are worthwhile. In the absence of a controlled experiment, ROI calculations can be tricky.
Approaches:
Place a monetary value on improved outcomes: For instance, shorter hiring cycles might reduce staffing shortages, leading to improved productivity for employers. Alternatively, if the feature attracts new subscribers to LinkedIn’s premium offerings, the revenue from those subscriptions might be partly attributed to the feature.
Compare cost savings: If previously recruiters had to rely on more expensive channels (agency recruiters, third-party consultants) and now direct messages have replaced that to some extent, the difference in cost can be a direct benefit.
Evaluate intangible benefits: Qualitative factors, such as improved brand perception or user satisfaction, might not directly show up in short-term financial metrics but could be important in sustaining user loyalty.
Pitfalls arise if you double count benefits or overlook hidden costs, such as increased customer support tickets or new infrastructure for scaling the messaging feature.
What If the Feature’s Usage Declines Over Time, Even Though It’s Valuable?
There can be user-interface or discoverability issues: People may not know the feature exists or how to use it effectively. Additionally, a portion of candidates might have a single short hiring cycle and then leave the platform for extended periods, giving the false impression of reduced engagement.
Potential resolutions:
Measure actual feature discoverability: Track clicks on the messaging entry point. Low entry usage might indicate the need for better UI visibility.
Gather direct feedback: Run in-app prompts or surveys after a user’s initial usage to see if they found the feature beneficial and easy to navigate.
Conduct cyclical re-engagement: Send targeted reminders or notifications, especially to new job seekers or those who appear to be in an active job hunt phase, to remind them of the direct messaging option.
An edge case is if a small, highly engaged group uses the feature consistently, generating most of its value. Relying on average metrics might obscure the significant impact on this niche group.
How Do We Identify Situations Where the Feature Might Work Against the User’s Best Interests?
A candidate might repeatedly message a recruiter, creating a poor first impression or breaching certain professional norms. This feature could inadvertently harm the candidate’s prospects if not used judiciously.
Preventive measures:
Provide best-practice guidelines: Offer in-app tips on appropriate messaging frequency or tone.
Leverage usage analytics to detect anomalies: If a user sends an unusually high number of messages to multiple recruiters in a short window, show cautionary reminders.
Incorporate recruiter feedback: If recruiters consistently flag messages as inappropriate, the candidate might receive warnings or usage limits.
A pitfall is overly restricting candidate communication, which could undermine the feature’s intent and stifle legitimate queries. Balancing guidelines with user autonomy is key.
How Do We Handle Global or Cultural Differences in Professional Communication?
In some cultures, directly messaging a hiring manager may be the norm, while in others it might be perceived as too forward. The platform spans many geographies, each with distinct professional etiquettes.
To accommodate this:
Launch culturally aware messaging guidelines: Provide localized tooltips explaining expected etiquette in each region.
Monitor engagement and success rates by geography: A region-specific drop in response rate might indicate a mismatch with local norms.
Collaborate with regional leads or user research teams: Gather feedback on how recruiters and candidates in each market perceive direct candidate messaging.
Edge cases can arise where a feature is highly successful in one region but fails or is viewed negatively in another. Aggregating data at a global level might hide these differences.
By considering these additional follow-up questions, you can delve deeper into edge cases, user behaviors, and contextual factors that extend beyond straightforward usage and outcome metrics, ultimately leading to a more holistic understanding of the feature’s true performance.