
ML Interview Q Series: How would you thoroughly examine the space complexity of Logistic Regression?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Logistic Regression is a linear model that maps input features to a probability score for a binary classification task. Its space complexity revolves around the memory required to store parameters (weights), data (input features and labels), and any intermediate structures needed for training.
Parameter Storage
If there are d features, then Logistic Regression’s weight vector has d parameters, plus a bias term. This means the model itself requires memory on the order of d to store the weights. In more formal terms, if w is the parameter vector and b is the bias, the total memory to store the model parameters is proportional to d + 1, which simplifies to O(d). In symbolic notation:
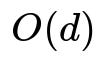
Here d is the dimensionality of the feature space.
Data Storage
When training with a dataset of n samples and d features each, the feature matrix X is n x d in size, and the label vector y has length n. Thus, the memory needed to store this data is typically O(n * d) for the feature matrix and O(n) for the labels. Overall, the dominating term for data storage is:

Additional Memory Needs During Training
Depending on the training strategy (full-batch, mini-batch, or stochastic gradient descent), additional memory may be required to store intermediate computations such as:
Predictions for each sample if full-batch or large-batch gradient descent is used. This typically requires O(n) space to store predicted probabilities for all samples at once.
Gradients with respect to each weight when computing updates; often this is also O(n) or O(n * d), depending on whether you accumulate or compute them on the fly.
If using regularization, you still only need to store the same weight vector (plus gradient terms), so the regularization does not significantly add to the overall space complexity beyond O(d).
In most practical implementations, storing the data (O(n * d)) dominates the memory cost, especially for large datasets. The model itself remains relatively small in comparison (O(d)) unless d is extremely large.
Example Code Illustration
Below is a simple PyTorch example that sets up a Logistic Regression model and highlights the dimensionality of parameters versus data. While this is a toy example, it shows where memory is allocated:
import torch
import torch.nn as nn
import torch.optim as optim
# Suppose we have 10000 samples, each with 300 features
n_samples = 10000
n_features = 300
# Creating random data
X = torch.randn(n_samples, n_features) # O(n*d) memory
y = torch.randint(0, 2, (n_samples,)).float() # O(n)
# Defining a simple Logistic Regression model
class LogisticRegressionModel(nn.Module):
def __init__(self, input_dim):
super(LogisticRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, 1)
def forward(self, x):
return torch.sigmoid(self.linear(x))
model = LogisticRegressionModel(n_features) # O(d) for storing parameters
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Forward pass for demonstration
predictions = model(X) # O(n) space for predictions
loss = criterion(predictions.squeeze(), y)
loss.backward()
optimizer.step()
# Print model parameter sizes
for name, param in model.named_parameters():
print(f"{name}, shape: {param.shape}")
In this code, X and y (the data) consume most of the memory. The model’s parameters (a weight vector of size n_features plus one bias term) consume comparatively less space.
Potential Edge Cases
For extremely large datasets (very high n), you may not hold the entire dataset in main memory. Techniques like mini-batch or streaming (online) training can be employed to process chunks of data at a time and reduce peak memory usage. This approach effectively keeps the space complexity for data at O(mini_batch_size * d) during updates.
For very high-dimensional problems (enormous d), storing the parameter vector w can become a challenge. One might reduce dimensionality using feature selection or transformation methods (e.g., PCA) or employ sparse structures if most weights remain zero.
Follow-Up Questions
How does the size of mini-batches affect space complexity?
Smaller mini-batches lower the amount of memory required at any given time for storing intermediate predictions and gradients. The data still exists, but you do not need to keep the entire batch loaded at once. The model parameters remain O(d), while the chunk of data you load is O(batch_size * d).
Which memory component typically dominates in real-world logistic regression scenarios?
Usually, the biggest contributor is O(n * d) for the dataset. Unless d is extremely large, storing the model parameters O(d) does not overshadow dataset memory usage.
Is it possible to train logistic regression when data is too large to fit into memory?
Yes. By using incremental or streaming methods, you can read portions of data from disk, compute partial updates, and then move on to the next chunk. This ensures you never load the entire dataset into memory at once.
What strategies can reduce the memory footprint for extremely high-dimensional data?
Dimensionality reduction techniques, sparse data representations (when many features are zero), or online feature selection can help decrease memory needs.
How does regularization impact space requirements?
L1 or L2 regularization does not significantly increase model parameter storage beyond O(d). The same parameter vector is used, and the additional overhead is small.
Can compression or quantization help?
Yes, if memory is constrained, you can compress parameters or store them at reduced precision (e.g., float16 instead of float32). This might slightly affect model accuracy but can reduce storage by half or more, depending on the compression scheme.