
ML Interview Q Series: How would you design a system to detect fraud and notify customers via text for confirmation?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
Building a fraud detection model for banking transactions and integrating a text notification system involves careful planning across several stages. It is not only about selecting the appropriate machine learning algorithm, but also about engineering robust data pipelines, choosing meaningful features, handling imbalanced data, and ensuring near real-time performance so that customers can be notified instantly.
Data Collection and Labeling
A robust fraud detection strategy begins with gathering relevant transactional data. Typical sources include payment details, user location, device signatures, IP address data, past account usage, and any history of confirmed fraudulent activity. Labeled data (past instances of fraud vs. legitimate transactions) is essential. Imbalanced data is common here, since genuine transactions can vastly outnumber fraudulent ones.
Feature Engineering
Careful feature creation can significantly boost model performance. Examples of features:
Transaction-related features, like amount, time, and frequency of transactions.
Customer behavior features, such as historical spending patterns or merchant categories frequently visited.
Geolocation or IP-based features (whether the user’s usual location matches the location of the transaction).
Derived statistical indicators, like average transaction amounts over certain periods and sudden deviations.
Aggregations and rolling averages (e.g., mean transaction amount over last
ndays).Model Selection
Various algorithms can be used for fraud detection:
Logistic regression, decision trees, gradient-boosted trees (like XGBoost, LightGBM), random forests, or neural networks. Ensemble methods often excel, combining multiple models to capture different aspects of fraudulent behavior.
A common and interpretable baseline is logistic regression:

Here, w represents the learned weight vector, x represents the input feature vector, b is a bias term, and (\sigma(\cdot)) is the sigmoid function mapping the linear combination to a probability range 0-1.
In logistic regression, each weight w_i indicates the importance and direction of a specific feature x_i for identifying fraud or genuine behavior.
Handling Class Imbalance
With fraud detection, the fraudulent class is typically a small fraction of total transactions. If the data is heavily skewed, naive models may simply predict “genuine” for nearly every transaction and still achieve high accuracy but miss almost all fraud.
Techniques for dealing with this imbalance include:
Oversampling of fraudulent transactions (e.g., SMOTE).
Undersampling of the majority class.
Adjusting class weights in the learning algorithm so that the model penalizes misclassification of the minority class more.
Using specialized metrics like precision, recall, or the F1 score for hyperparameter tuning instead of raw accuracy.
Model Training and Cross-Validation
When training any supervised classifier for fraud detection, cross-validation helps in evaluating how well the model generalizes. Stratified folds should be used to preserve the fraud vs. non-fraud ratio in each split. Hyperparameters can be tuned to improve recall without destroying precision, or vice versa, depending on business constraints.
Real-Time Inference and Notification Integration
Once the model is trained and tested, the real-time detection system can be organized as follows:
Whenever a transaction is initiated, the transaction data is quickly fed into the deployed model (often through a microservice or a streaming pipeline).
If the predicted probability of fraud is above a certain threshold, the transaction can be flagged for further inspection or delayed pending user confirmation.
A text message is automatically sent to the customer, including pertinent transaction details (like amount, merchant name, and timestamp).
The user can respond with “Approve” or “Deny.” The system updates the transaction status accordingly. If the user denies, the transaction is reversed or blocked.
Model Monitoring and Feedback Loop
An essential part of a fraud detection system is a feedback loop:
Fraud labels become more accurate over time when customers confirm or deny suspicious transactions.
The system continuously collects new examples of confirmed fraud or genuine activity to retrain or fine-tune the model, improving detection performance with changing fraud patterns.
Example Python Snippet
import pandas as pd from sklearn.model_selection import train_test_split, StratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report from imblearn.over_sampling import SMOTE # Suppose df has columns for features and a 'fraud_label' df = pd.read_csv('transactions.csv') X = df.drop('fraud_label', axis=1) y = df['fraud_label'] # Handle imbalance sm = SMOTE() X_resampled, y_resampled = sm.fit_resample(X, y) # Train/validation split X_train, X_val, y_train, y_val = train_test_split(X_resampled, y_resampled, test_size=0.2, stratify=y_resampled, random_state=42) # Train logistic regression clf = LogisticRegression(class_weight='balanced', solver='liblinear') clf.fit(X_train, y_train) # Predict and evaluate y_pred = clf.predict(X_val) print(classification_report(y_val, y_pred))This illustrative example uses logistic regression and SMOTE to handle the imbalanced dataset. The text messaging service would be integrated in a production environment—likely using an API that triggers an SMS notification once the classifier’s probability of fraud is above a certain threshold.
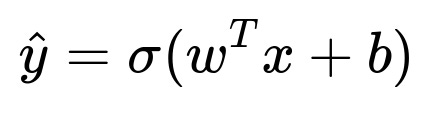
Possible Follow-Up Questions
How do we decide the probability threshold above which we label a transaction as suspicious?
The threshold directly impacts the trade-off between false positives (legitimate transactions flagged as fraud) and false negatives (fraudulent transactions slipping through). We can analyze precision-recall or ROC curves to identify a threshold that suits the bank’s tolerance for risk. A higher threshold reduces false positives but may let more fraud through. A lower threshold flags more suspicious transactions but inconveniences customers who receive many false alarms.
In practice, banks might dynamically adjust this threshold depending on transaction amount, time of day, or known risky merchant categories. They also might incorporate cost-based analysis, weighting the cost of a false alarm versus the potential loss from an undetected fraud.
How do we keep the model updated against new, evolving fraud tactics?
Fraudsters often adapt their behaviors. The solution is an ongoing, incremental learning pipeline or periodic re-training. We gather newly flagged transactions (with user confirmation if they are indeed fraud or not). This data, plus the original training set, forms the basis for re-training. Advanced strategies include online learning, where model parameters are updated in small increments with each new data batch, or active learning, where the system prioritizes uncertain transactions for human review.
Are there privacy or compliance considerations we must address?
Since financial data and user phone numbers are extremely sensitive, compliance with regulations such as GDPR, CCPA, and other data protection requirements is mandatory. Robust encryption of data at rest and in transit, limiting data access, and strict retention policies are crucial. User consent for text notifications and for storing their phone numbers is another consideration. The system must also handle potential data security breaches by employing strict authentication and authorization protocols.
How would we detect if a phone number itself has been compromised?
If an attacker compromises the customer’s phone or SIM card, simple text confirmations might not be sufficient. To mitigate this:
Use two-factor authentication or a secure banking application that can verify device integrity.
Track device usage patterns to detect suspicious device usage.
Send alerts via multiple channels (email, push notifications, or automated phone calls) if large or unusual transactions are detected.
What if real-time response is required, but model inference is too slow?
We can optimize real-time detection by:
Deploying an efficient model or using GPU acceleration for deep learning.
Implementing a two-step approach: a lightweight model for real-time scoring that quickly flags suspicious transactions, followed by a more detailed offline analysis if necessary.
Caching common feature transformations and ensuring minimal overhead in the data pipeline.
How can we ensure customer satisfaction with the text-based system?
Overly frequent or erroneous alerts annoy customers. Thorough calibration is key. Monitoring false positives is essential. Continual improvement and user feedback (e.g., a quick user survey after final resolution of flagged transactions) can help refine the threshold or incorporate additional context in deciding whether to flag a transaction.
Adjusting the content of messages to be user-friendly and clear is also crucial: explaining the merchant name, transaction amount, location, and next steps helps users feel informed without confusion.
Below are additional follow-up questions
How would we deal with concept drift or changing fraud patterns over time?
Fraud tactics and consumer behaviors evolve, so the underlying data distribution can shift—this is concept drift. If the model is not adapted to reflect new patterns, performance degrades. One approach is to maintain a rolling window of recent transactions and retrain at regular intervals, ensuring the model sees the latest data. An alternative is incremental or online learning, where model parameters update continuously as new labeled data arrives. A potential pitfall is if the system’s concept drift detection is too sensitive, it may trigger unnecessary retraining and produce instability. Conversely, if it is not sensitive enough, the model may miss early signs of new types of fraud.
Could we integrate external data sources to enhance detection?
External data, such as blacklists of known fraudulent phone numbers, compromised IP addresses, or negative feedback from other financial platforms, can improve coverage of potential fraud patterns. However, the major risk is data quality and compatibility—external datasets might have different feature definitions or inconsistent label formats. Also, licensing or privacy restrictions might prevent direct usage. Another subtlety is ensuring fairness and avoiding biases: if external data systematically misrepresents certain user segments, the model might propagate those biases.
What happens if our model faces partial or incomplete transaction data?
Sometimes certain fields might not be available in real time due to system delays or third-party service issues. A model that relies heavily on missing attributes may be unreliable. To mitigate this, the system can implement fallback strategies:
Impute missing values based on historical averages or known defaults.
Use a separate lightweight model designed for minimal features in the case of partial data.
Defer classification until critical fields arrive, balancing real-time needs with data completeness. A pitfall is incorrectly imputing data in a way that biases the fraud score or systematically overlooks certain fraud patterns in the incomplete data scenario.
Are there scenarios where an unsupervised or semi-supervised approach might outperform a purely supervised model?
Yes. In settings where confirmed fraud labels are scarce or delayed, anomaly detection techniques can be used to detect unusual transaction patterns without explicit labels. Semi-supervised methods can leverage a small set of known fraud examples combined with a large volume of unlabeled transactions. A primary risk is that anomaly-based approaches might flag too many normal outliers, overwhelming investigators with false positives. Another edge case is that certain fraud might mimic normal behavior closely, thus going undetected by generic anomaly scoring.
How do we ensure that system downtime or high-latency events do not disrupt fraud detection?
Some high-throughput environments might introduce latency if the model or the SMS system becomes overloaded. This can result in delayed alerts or missed real-time decisions. Solutions include horizontally scaling the inference service (e.g., using load balancing) and setting up robust monitoring with metrics that track response times and queue lengths. If a real-time check cannot be completed within a specified time window, a fail-safe approach might block or hold the transaction temporarily, pending manual review. A subtle pitfall is that frequent false alarms with blocked transactions can damage user trust if the system is too conservative during service degradation.
What if large-scale coordinated attacks overwhelm the text-based verification system?
Fraud rings might exploit bulk transaction attempts, causing a surge in text notifications. This can overload SMS gateways or cause legitimate transactions to be delayed. A possible defense is rate limiting at the user or account level, combined with secondary verification steps if an abnormally high volume of suspicious transactions is detected. Another subtlety is verifying that the user’s phone number is still valid and that messages are indeed reaching the intended recipient. Attackers could attempt SIM swapping at scale to bypass verification if phone ownership checks are weak.
Could a rule-based component complement the machine learning approach?
Yes. A hybrid system might combine a rule engine (for well-known fraud heuristics, such as “block transactions above a certain threshold from blacklisted countries”) with a data-driven model. Rules act as a safety net or early filter. The potential downside is that a static rule set can quickly become stale if fraudsters adapt. Continuous maintenance of these rules is needed, and conflicting rules might override an otherwise accurate ML score. Furthermore, an overabundance of complicated or overlapping rules can create confusion and hamper proper debugging.
How do we ensure an efficient and effective feedback system for newly detected fraud cases?
Each flagged transaction needs to be manually verified by domain experts or the affected customers. A robust feedback mechanism will systematically capture whether the transaction was genuinely fraudulent or not. This feedback updates the training dataset for future modeling. If verification is slow or inaccurate, the model cannot adapt quickly. Another edge case arises if users ignore or do not respond to texts, leaving the system uncertain about final labels. Automated reminders or phone calls may be necessary, but this raises costs and potential user annoyance. Proper auditing and logging of these interactions is critical to ensure traceability and accountability.