
ML Interview Q Series: How would you go about assessing a model that determines whether a shared news item on Twitter is pertinent or not?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
When determining how well a model performs in classifying if a piece of news shared on Twitter is relevant, there are multiple dimensions to consider, including data collection strategy, labels, performance metrics, and overall business/contextual goals. The process starts with obtaining a carefully curated dataset of tweets that are labeled as “relevant” or “not relevant” by human annotators. The model’s output is then compared against these ground-truth labels to measure its effectiveness. Below is a closer look at important evaluation methods and metrics, along with deeper insights into critical considerations.
Ground Truth Labeling and Data Collection
Training and evaluating a classifier for news relevance hinges on having a trustworthy labeled dataset. This typically involves collecting tweets and then employing human evaluators to label whether each tweet is relevant or not. Potential pitfalls might arise if the dataset is biased or doesn’t cover the full spectrum of topics or styles of sharing news on Twitter. In scenarios where the distribution of relevant vs. irrelevant news is imbalanced, special attention is needed to ensure that evaluation metrics are aligned with the actual class distribution.
Classification Metrics
Different metrics highlight different aspects of a model’s performance. Relying solely on a single metric can be misleading, so typically multiple metrics are tracked.
Accuracy and Its Limitations
Accuracy is the fraction of correctly classified samples over the total samples. Although it is intuitive, it can be misleading if the dataset is highly imbalanced. For instance, if only 10% of tweets are “relevant,” a naive model predicting “not relevant” every time can score 90% accuracy but be useless in practice.
Precision and Recall
Precision gauges the fraction of predicted relevant tweets that are actually relevant, while recall measures the fraction of truly relevant tweets that the model correctly identified. These can be expressed as core formulas:
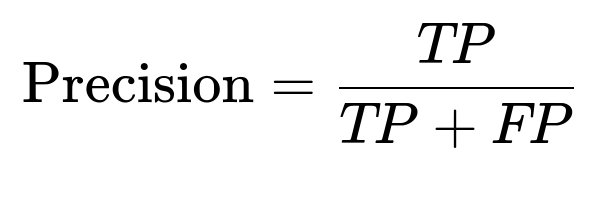

where TP is the count of true positives, and FN is the count of false negatives.
These two metrics are crucial when the cost of misclassification is different for false positives versus false negatives. If the requirement is to ensure that every relevant piece of news is captured, recall becomes more important. On the other hand, if it is more important to avoid falsely flagging irrelevant news, precision is emphasized.
F1 Score
F1 Score is a harmonic mean of precision and recall, offering a single metric that balances both. It is often a go-to metric when seeking an equilibrium between precision and recall.
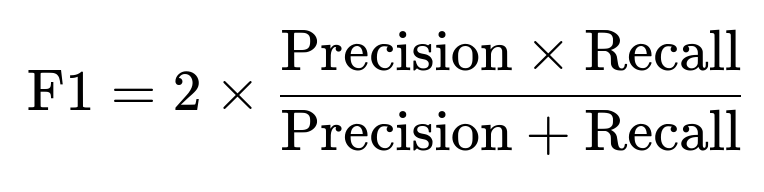
where Precision is as defined above and Recall is as defined above. This metric becomes particularly important if the data is imbalanced, but you still need to capture both false positives and false negatives in a balanced manner.
ROC Curves and AUC
Receiver Operating Characteristic (ROC) curves plot the true positive rate (recall) against the false positive rate at varying thresholds. The Area Under the ROC Curve (AUC) summarizes this performance into a single value between 0.0 and 1.0. A higher AUC indicates that the model is better at ranking relevant items higher than irrelevant ones across various thresholds. However, if the positive class (relevant news) is relatively rare, Precision-Recall curves and their AUC might be more informative than ROC curves.
Cross-Validation Strategy
To ensure that a model is robust and not overfitting, cross-validation can be employed. In K-fold cross-validation, the dataset is partitioned into K subsets, and the model is iteratively trained on K-1 folds while using the remaining fold for validation. This process repeats until every fold has served as a validation set once. The average performance across all folds is then reported. This strategy is particularly useful when dealing with smaller datasets or when you want to ensure that every instance is used for both training and testing.
Handling Imbalanced Data
In many real-world scenarios, most tweets might not be “relevant,” making relevant ones a minority class. Techniques like oversampling the minority class, undersampling the majority class, or using specialized loss functions (for instance, focal loss) can improve performance. Weighted metrics or cost-sensitive learning approaches can also shift the model to focus more on the minority class. If the ultimate goal is finding all relevant news items at the cost of a few extra false positives, recall or the F2 score might be more appropriate than the F1 score.
Business Context and Real-World Constraints
Even if a model shows strong performance on static offline datasets, Twitter is a dynamic platform with trending topics and new vocabulary constantly emerging. Regular re-training or fine-tuning on fresh data may be required. Evaluation should also consider inference latency, interpretability, and how the system will be integrated into a broader product pipeline (for example, automated content moderation or news feed filtering).
Potential Follow-Up Questions
How would you mitigate the risk that the labelers themselves might not agree on the definition of “relevant”?
Labeling disagreements are common, especially in subjective tasks. One strategy is to obtain multiple labels per tweet to measure inter-annotator agreement. Where there is high variance among annotators, the label might be ambiguous, or more clear labeling guidelines could be necessary. Modeling approaches such as probabilistic labeling or building consensus labels can help. Regular training sessions with annotators and clarifying instructions are useful for achieving more consistent labeling.
How would you address the problem of class imbalance if most tweets are irrelevant?
Class imbalance can be tackled by adopting techniques such as: Oversampling the minority class, for example SMOTE (Synthetic Minority Over-sampling Technique), which creates synthetic samples in feature space for the minority class. Undersampling the majority class if you can afford discarding some data. Using weighted loss functions in models like logistic regression, SVM, or neural networks, where you assign higher penalties for misclassifying the minority class. In practice, the choice depends on the magnitude of imbalance, data volume, and how critical it is to capture most relevant tweets (for instance, recall might be more important).
How do you update the model over time as Twitter and user behavior evolve?
A model might become stale if language usage changes significantly or new topics go viral. A practical approach is to periodically collect and label new tweets to fine-tune or retrain the model. Continual learning methods can also be considered, where new information is incrementally learned without forgetting the previous distribution. Monitoring model performance in a production environment with fresh data and setting up triggers for retraining is key to maintaining effectiveness.
How do you evaluate if the predictions are actually aligning with business outcomes?
Metrics like precision, recall, or AUC show how well the classifier performs at a technical level. However, in a business context, the ultimate measure is whether the model’s results align with organizational objectives. This might include user engagement metrics, user feedback on recommended or filtered news, or a decline in the spread of irrelevant or misleading information. If the model is used for alerting users about trending news, you might track how many relevant news items were caught early vs. how many pointless alerts were generated.
How do you choose between F1 Score and Precision-Recall AUC?
If there is a significant class imbalance and discovering every relevant piece of news is paramount, focusing on recall (and possibly F2 or recall at K) might be best. If the goal is to maximize the quality of flagged news while tolerating some misses, precision is more crucial. F1 Score balances both, but if ranking is important and you want to consider different thresholds, the Precision-Recall AUC can provide a more nuanced view of performance across those thresholds.
What are some ways to measure the explainability of the model’s decisions?
Explainability can be approached through local methods like LIME or SHAP to see which features are most important in driving the prediction for particular tweets. Globally, feature importance plots, gradient-based saliency maps (in neural networks), or attention-weight visualizations can show broader patterns in the data. However, these approaches can sometimes be trickier for text data because of the inherent complexity of natural language. Nonetheless, providing some interpretability can build trust and help debug misclassifications.
Below are additional follow-up questions
How would you design or conduct an error analysis to gain deeper insight into model mistakes?
A rigorous error analysis can often reveal underlying issues that aggregate metrics like precision and recall fail to expose. One practical approach is to categorize misclassified tweets based on error type. For instance, you might group them into “false positives due to clickbait headlines,” “false positives due to sarcasm,” “false negatives for tweets lacking explicit keywords,” and “mixed-language tweets.” Once you identify these clusters of errors, you can trace them back to root causes:
• Data Coverage: If most clickbait headlines are missing from your training data, the model might confuse them for valid news. You might need additional labeled examples reflecting such content. • Lexical or Semantic Gaps: Sarcasm is notoriously difficult for models to detect, especially if the language is ambiguous. A targeted approach (like adding sentiment or topic context) might be considered. • Language Models: If multiple languages or slang words are prevalent, the tokenizer or embedding mechanism might be failing to represent them correctly.
By analyzing these recurring patterns, you can direct your efforts toward data augmentation, feature engineering, or more specialized NLP models to address each category of error.
How would you incorporate user feedback to refine the model over time?
One pathway to continuous model improvement is leveraging user feedback loops. Suppose a user has the ability to mark whether a recommended (or flagged) tweet is actually relevant or not. These user labels can then be aggregated and re-introduced into the training pipeline:
• Data Logging: Store the user-corrected labels, along with all the associated features (raw text, metadata, etc.). • Retraining or Fine-tuning: Periodically incorporate these new user labels to retrain or fine-tune the model so it learns from real-world errors. • Addressing Noise: User feedback data can be noisy, particularly if malicious users intentionally mislabel. Including consistency checks or aggregator methods (like majority votes from multiple users) helps mitigate these risks.
This feedback loop not only enhances model accuracy but also tailors the system more closely to end-user requirements, making the classification more relevant in practice.
In what ways can domain adaptation or transfer learning be applied if the model is also used to classify news relevance in other social media platforms?
Twitter is only one social media platform, and each platform has a different style, character limit, and user base. When moving from Twitter to, say, Facebook or LinkedIn, domain adaptation becomes a potent strategy:
• Pretrained Language Models: Models like BERT, RoBERTa, or DistilBERT can be initially trained on massive corpora and then fine-tuned for Twitter-specific text. Adapting to another platform might require re-finetuning with examples from that new domain. • Domain-Specific Vocabulary: Each platform might exhibit unique slang or shorthand that a Twitter-optimized model does not capture. Incorporating data from the target domain prevents vocabulary mismatches. • Multi-Domain Learning: Combining training data from multiple social media sources can sometimes generalize better across domains, though careful attention to data distribution shifts is critical.
Evaluating the adapted model on the target domain—through the same set of classification metrics—ensures that the domain shift hasn’t degraded performance.
How would you account for adversarial manipulation or spamming attempts designed to trick the classifier?
Bad actors might try to slip irrelevant or misleading content through the classifier by using tactics like obfuscating words, inserting random characters, or intentionally altering vocabulary. To deal with such adversarial behavior:
• Robust Preprocessing: Techniques like removing excessive punctuation or normalizing repeated characters can mitigate straightforward manipulations. • Data Augmentation: You can create synthetic adversarial examples during training to improve the model’s robustness. For instance, intentionally scramble non-critical parts of words or insert random symbols, forcing the model to learn semantic rather than purely lexical cues. • Continuous Monitoring: Track any spikes in false positives or anomalies in classification logs. Sudden changes may indicate new adversarial strategies that require immediate model updates or manual intervention. • Ensemble Defenses: Sometimes combining multiple classifiers—each specialized on different feature sets—makes it harder for adversaries to bypass every layer.
What strategies would you use if news relevance is inherently subjective, leading to ambiguous labels?
Some topics straddle the border between relevant and irrelevant, especially if there is disagreement about what “news” entails. Subjectivity might also arise if a tweet references a niche topic that is “relevant” to a certain audience but not to another. Strategies include:
• Crowdsourced Labeling with Multiple Annotators: Gather multiple labels for each tweet and use statistical models (like majority votes or Bayesian modeling of annotator reliability) to derive a confidence score. • Hierarchical or Multi-Level Relevance: Instead of a binary label, define multiple categories (e.g., “highly relevant,” “possibly relevant,” “irrelevant”) and let users or annotators place tweets more flexibly. • Personalization: If relevance depends on user interest, embed user preferences into the model. This transforms the classifier from a generic news relevance model into a personalized recommendation system.
How would you handle a scenario where the volume of tweets is extremely large and real-time predictions are needed?
High-volume, real-time classification demands efficient model architectures and data pipelines:
• Model Optimization: Approaches like model quantization, knowledge distillation, or pruning can reduce computational overhead while preserving accuracy. • Streaming Architecture: Use distributed streaming systems (e.g., Apache Kafka, Apache Flink, or Spark Streaming) for ingesting tweets and applying model inference on-the-fly. • Caching and Batching: In many real-time systems, small delays of a few seconds are acceptable. Batching tweets in micro-batches can drastically accelerate processing on GPUs or optimized hardware. • Scalability: Horizontal scaling (using multiple machines) or specialized inference solutions like TensorRT can handle surges in traffic without throttling performance.
How do you ensure fairness and mitigate unintended biases in the relevance classification?
Even if the task is simply distinguishing relevant from irrelevant news, biases can creep in if certain topics, user demographics, or regions are underrepresented in training data:
• Data Audits: Conduct thorough checks on training data for distribution across various topics, languages, or communities. If certain groups are absent or under-sampled, the model might treat their news as less relevant. • Bias Metrics: Beyond standard performance metrics, examine how the model performs for different user segments or content categories. Identify disparities in false positives and false negatives. • Correction Strategies: Employ re-balancing or domain-specific oversampling. Set up fairness constraints where relevant, such as forcing false-positive or false-negative rates to be comparable across key demographics or topics. • Ongoing Monitoring: Once deployed, keep monitoring classification decisions and collect user feedback specifically targeted toward fairness and inclusivity concerns.
Is there a situation where ensembles of multiple models might yield better performance than a single classifier?
In complex tasks, combining multiple models can capture different nuances that a single model might miss:
• Model Diversity: Use distinct architectures (e.g., an LSTM-based classifier, a transformer-based classifier, and a rule-based system). If each exhibits different error patterns, their combination often improves overall performance. • Aggregation Strategies: Weighted voting or stacking can be employed to merge model outputs. For instance, one model might have high recall but lower precision, while another is the opposite. By adjusting their voting weights, you can achieve a balanced trade-off. • Resource Constraints: The downside is that ensembles require more computational resources, both during training and inference. Carefully consider whether the performance gains justify the overhead in a production context.
How do you handle references to multimedia content in tweets (images, links, or videos) that might provide clues about relevance?
Many tweets about breaking news may include an external link, an attached image, or a video clip. If you focus solely on text, you risk missing signals:
• Metadata Extraction: At minimum, parse the tweet’s metadata to identify if a link points to a known news source or if the image is from a verified news channel. • Image/Video Content Analysis: Advanced setups might use image recognition or even short video analysis to see if the media is consistent with news content (for instance, a well-known channel’s logo or screen captures of news streams). • Hybrid Models: Combine text embeddings from the tweet with image embeddings from a convolutional neural network or a transformer-based vision model. This multi-modal approach typically yields a more comprehensive assessment of relevance. • Resource Implications: Multi-modal models require more computational power and are more complex to deploy, so weigh the performance gains against additional system costs and engineering complexity.
When might semi-supervised or unsupervised approaches be beneficial in identifying relevant content?
If labeling costs are high or if there are rapidly emerging topics, a large portion of unlabeled tweets may exist. Semi-supervised or unsupervised learning can help:
• Clustering: Group unlabeled tweets by semantic similarity, and label entire clusters if they predominantly reflect relevant (or irrelevant) news. This approach is particularly handy for quickly adapting to new events that your model has never seen. • Self-Training: Use the model’s own high-confidence predictions on unlabeled tweets to augment the training set. This is risky if the model is biased or inaccurate, but careful thresholds and iterative retraining cycles can make it effective. • Active Learning: Prompt a human annotator to label only those tweets about which the model is least confident. This way you spend labeling effort where it’s most impactful, helping the model learn from its “blind spots.”