
ML Interview Q Series: How would you explain the distinction between a matrix and a tensor, and how do they fundamentally differ?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
A matrix is typically recognized as a 2-dimensional grid of numbers. It can be visualized as having rows and columns. By contrast, a tensor is a more generalized concept that extends beyond two dimensions. In machine learning and deep learning, we often use the term “tensor” to describe multi-dimensional arrays of any rank, including vectors (rank-1), matrices (rank-2), or higher-rank entities that have three or more axes.
Mathematically, one way to represent a matrix is:
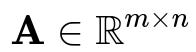
where m represents the number of rows, and n represents the number of columns.
A tensor can be represented similarly but generalized to N dimensions:

where d_1 through d_N are the dimensions (or shape) across each axis of the tensor. If N=2, we get a matrix. If N=1, it is a vector. If N=3 or higher, it is a higher-order tensor.
In practice, matrices are widely used for linear algebra operations such as matrix multiplication, eigenvalue decomposition, and so on. Tensors allow deeper representations; in modern deep learning frameworks like PyTorch and TensorFlow, you can create and manipulate higher-dimensional tensors, which is crucial for handling multi-channel images, batched sequences, or stacked embeddings.
From a computational viewpoint, tensors provide a consistent way to describe shapes and batch dimensions. For example, images might be stored as a 4D tensor with batch_size, channel, height, and width. Matrices are generally a special case of tensors when you only need two dimensions.
Below is a minimal code snippet in Python (PyTorch) that shows how we create a matrix and a higher-dimensional tensor:
import torch
# Creating a 2D tensor (matrix)
matrix = torch.tensor([[1.0, 2.0],
[3.0, 4.0]])
print("Matrix shape:", matrix.shape) # Output: torch.Size([2, 2])
# Creating a 3D tensor
tensor_3d = torch.tensor([[[1, 2], [3, 4]],
[[5, 6], [7, 8]]])
print("3D Tensor shape:", tensor_3d.shape) # Output: torch.Size([2, 2, 2])
Matrices (2D) and tensors (N-dimensional) share common operations (like slicing, reshaping, or arithmetic), but tensors can have any number of dimensions, each dimension referring to a different organizational axis of the data.
How do higher-order tensors appear in real-world data?
In many cases, especially in computer vision or signal processing, data may have more than two dimensions. For instance, a single RGB image has three dimensions: height, width, and color channels. If you combine a batch of multiple images, you add an additional axis for the batch size, resulting in a four-dimensional structure. In natural language processing with attention mechanisms or recurrent architectures, you can end up with 3D or 4D structures for sequences, hidden states, and potential feature channels.
What are some practical differences in memory usage?
A matrix is simply stored with a single stride in memory for rows and another for columns (row-major or column-major order). Tensors with more axes need to keep track of additional strides or shape information. Practically, this means that computations on tensors can become more complex, and memory layout can be a concern for large, high-dimensional data. Many performance optimizations in deep learning libraries revolve around efficient handling of these multidimensional structures.
How do deep learning frameworks handle matrices vs. tensors?
Frameworks like PyTorch or TensorFlow internally store multi-dimensional data as tensors with a known shape. Even a 2D object in these libraries is referred to as a “tensor” of rank-2. The frameworks optimize operations like convolutions, matrix multiplications, and reshaping to work on any rank, often leveraging vectorized operations that handle batches of data in parallel on GPUs. This unified model (everything is a tensor) simplifies the way we write code, so we don’t typically need separate data structures for vectors, matrices, or higher-rank tensors.
How do operations like matrix multiplication generalize to higher-order tensors?
Matrix multiplication (2D x 2D) has a direct generalization to batches of matrices (3D x 3D) and so on. In many deep learning libraries, you can perform batched matrix multiplication by passing two 3D tensors that correspond to a stack of matrices. The operation is then automatically broadcast across the batch dimension. A similar concept applies for element-wise additions or multiplications, where each dimension is aligned and the operations are applied across all matching or broadcastable dimensions.
When would you use a matrix rather than a tensor?
You might stick to a matrix representation if you’re working in “pure” linear algebra contexts, such as a classic linear regression model with a design matrix of shape m x n, or for simpler transformations in 2D. Once you introduce additional dimensions (multiple feature channels, time steps, or batch size), a tensor becomes the necessary representation. However, conceptually, you can think of both as the same structure, with a matrix simply being a rank-2 tensor.
What is the rank of a matrix vs. the order of a tensor?
Sometimes the term rank in linear algebra refers to the dimension of the vector space spanned by its rows (or columns). For matrices, rank has a specific meaning (the maximum number of linearly independent columns or rows). However, when referring to tensors, the word rank often changes meaning to indicate the minimum number of separable components (in factorization contexts), and the term order or mode is used to describe how many dimensions the tensor has. Be careful to distinguish between the concepts when discussing matrix rank versus tensor order or tensor rank in advanced decomposition topics.
Could a matrix be considered a tensor?
Absolutely. A matrix is often called a second-order tensor because it has two dimensions. Similarly, a vector is a first-order tensor (one dimension), and a scalar is a zeroth-order tensor (no dimension). The difference is largely about generalizing to more dimensions. In applied deep learning, people just say “tensor” to mean an array that might have any number of axes (including 0D, 1D, 2D, or ND).
Are there any common pitfalls when transitioning from matrices to higher-order tensors?
One common pitfall arises in shape mismatches and broadcasting rules. When someone is used to matrix multiplication, they may forget to check that their rank-3 or rank-4 tensors are compatible in specific dimensions. Another pitfall is memory explosion, as each new dimension can exponentially increase the size of data. Also, the overhead in thinking about multi-dimensional indexing can lead to subtle off-by-one or shape alignment errors when implementing advanced algorithms.
Could you illustrate a subtle usage scenario?
Consider a language model that uses attention across multiple heads. Each head can be considered a dimension. If you have a batch dimension, a sequence length dimension, a hidden size dimension, and a head dimension, it’s easy to mix them up when coding. If you treat everything as a matrix, you might flatten dimensions incorrectly, causing a mismatch in shape or a misinterpretation of the data structure. Using a tensor with clearly tracked dimensions helps maintain clarity, although you must handle permutations, reshapes, and broadcasts carefully.
How do advanced factorization techniques differ for matrices vs. higher-order tensors?
Factorizations for matrices include SVD, eigen-decomposition, and QR. For tensors, there are advanced decompositions like CP (CANDECOMP/PARAFAC), Tucker decomposition, and Tensor-Train decomposition. These techniques extend the idea of capturing latent factors or low-rank structure into higher-dimensional data. However, the algorithms and their computational cost can be significantly more complex, and they often require specialized implementations.
Could you summarize the key takeaway?
The key takeaway is that a matrix is a 2D structure, whereas a tensor is a more general, multi-dimensional concept. A matrix is a special case of a tensor, specifically rank-2, and in practice, tensors are essential for representing the higher-dimensional data encountered in real-world machine learning and deep learning tasks.