
ML Interview Q Series: How would you address Facebook's finding that more friends lead to less post activity in "people you may know"?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
One way to think about the situation is to first verify the relationship between total friend count and posting frequency, and then investigate whether that observation is causal or correlated due to other factors. A typical step might involve measuring correlation—specifically Pearson correlation—between number of friends and posting activity. This is often expressed with a coefficient r that describes how related these two variables are. If you want to quantify that linear relationship, you might compute the correlation coefficient using the following formula:
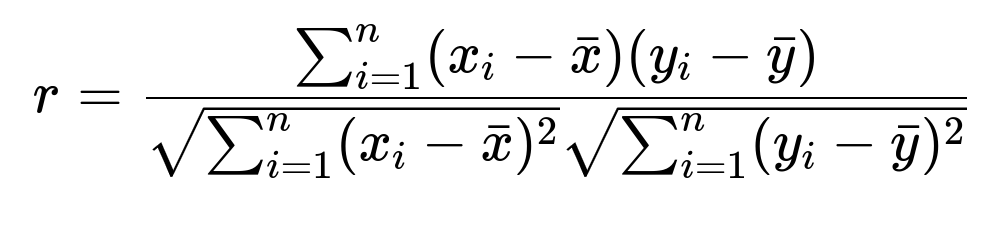
In this expression, x_i is the friend count for user i, y_i is the posting frequency for user i, n is the total number of users in the sample, bar{x} is the average friend count across these users, and bar{y} is the average posting frequency. A value of r close to 0 means little linear relation, while a value near 1 or -1 indicates a strong positive or negative linear relationship.
However, correlation alone does not imply causation. It’s possible that users who already tend to be heavy social connectors might feel they get sufficient social interaction through direct messaging or feed browsing, so they choose to post less. Alternatively, a user who sees a large amount of content in their feed could be overwhelmed, leading them to engage passively rather than creating original posts.
After confirming the existence of a meaningful correlation, you would consider:
Analyzing user segments. Segmenting by demographic information, region, and behavioral patterns could help identify subgroups for which this relationship is stronger or weaker. For instance, younger users might add many friends quickly but still post frequently, while another demographic might behave differently.
Examining the user’s overall experience. It may be that as someone accumulates more connections, they receive a lot of notifications or feed content, and they might feel less inclined to post. Alternatively, they might prefer other platforms or mediums (groups, stories, messaging) that are not captured in the traditional “posting” metric.
Looking for hidden confounders. Factors such as age of the account, typical browsing behavior, presence of alternative content-generation features, time spent on platform, or privacy settings can all affect the direct friend–post relationship.
Experimenting with intervention. One could pilot a personalized feed or specialized prompts for users who have many friends but show reduced posting behavior. For example, an A/B test could show a new design for the “people you may know” feature that includes suggested ways to post or engage with new connections.
Adjusting your recommendation objective. If you find that simply adding more friends sometimes causes posting frequency to drop, you might consider adjusting your recommendation algorithm to optimize not just for friend connections but also for user engagement signals, such as likes, comments, or direct posts. A multi-objective approach can better balance friend growth and content creation.
Building a better user model. Using machine learning approaches, you could create user embeddings that incorporate friend count, feed engagement, time spent, and other interaction metrics. This model might help you predict the user’s willingness to post if recommended new connections with certain attributes.
Validating with caution. After implementing a revised recommendation strategy, ongoing monitoring is essential to confirm that the new approach does not reduce user satisfaction or cause other unintended consequences, such as users churning because they feel pressured to post.
Follow-up Question: How would you confirm that the act of adding more friends genuinely causes a reduction in posting, rather than being just a correlation?
You can design controlled experiments or quasi-experiments. A typical approach might be to identify a random subset of users for whom the “people you may know” suggestions are limited or altered, while another subset sees the standard recommendations. If the group that sees the modified friend suggestions ends up with fewer new friends on average, and the difference in posting behavior between the two groups emerges in tandem with that difference in new friend counts, it provides stronger evidence for a causal relationship.
It is also possible to use techniques such as difference-in-differences if there is a staggered rollout of a new feature or a natural experiment. In that scenario, you measure posting behavior before and after the intervention for both the treatment group and a control group, ensuring that confounding influences are addressed. This approach helps isolate whether friend growth itself triggers a decline in posting or if there are alternative explanations (like user’s personal circumstances or concurrent product changes).
Follow-up Question: Could there be a scenario in which having more friends might indirectly encourage higher-quality posts, even if the frequency goes down?
Absolutely. A user with a large audience might post less frequently but invest more effort into crafting each post, aiming for higher-quality content. This scenario suggests that one might need to track quality-related metrics such as post reach, likes, comments, shares, or dwell time. A user with many friends could be more selective in how often they post, resulting in more engaging content that receives higher interactions.
In such a case, if the real business objective is to increase user engagement and platform health, fewer high-impact posts might still be beneficial. Hence, any attempt to encourage more frequent posting should be weighed against potential reductions in the post’s quality and engagement. Tracking a variety of engagement signals (likes, comments, conversation threads, or total watch time for videos) could offer a more nuanced perspective than pure posting frequency.
Follow-up Question: How would you handle issues of bias in your recommendation engine when optimizing both friend growth and post frequency?
One approach is to incorporate fairness and diversity constraints into the recommendation system so that certain users or user groups are not disproportionately affected by changes. By introducing re-ranking or optimization steps that ensure equitable distribution of friend recommendations across different demographics or user behaviors, you reduce the chance of skewing the platform toward only certain types of users.
In addition, regular audits and fairness checks can help identify biases. For instance, if the system over-recommends certain accounts that lead to large but shallow networks, the system might inadvertently reduce meaningful posting activity. Monitoring key fairness metrics (like how well each user segment is served by the friend suggestion system) would allow you to refine the recommendation logic to balance friend growth, user engagement, and equitable outcomes.
Follow-up Question: If your final objective is to keep people actively engaged by posting or consuming content, how would you measure success after making changes to the “people you may know” feature?
Measurements should be holistic. Beyond simple metrics like daily active users (DAU) or monthly active users (MAU), you would look at posting frequency and posting quality signals (for example, average engagement on posts). You might also track user retention over time, average session duration, number of feed interactions, and other relevant product metrics that capture longer-term platform health.
A/B testing would be the standard tool for evaluating success. By randomly assigning new features or adjusted friend recommendations to different user groups, you can compare how each cohort’s metrics evolve. You would want to ensure that your test design accounts for user behaviors over a reasonable period, considering that friend-adding and posting behavior can unfold gradually.
Additionally, you would continuously watch for negative indicators such as an increase in spammy posts or user dissatisfaction. It is crucial that in aiming to boost posting frequency, you do not degrade the overall user experience or quality of content on the platform.
Follow-up Question: What are potential pitfalls when rolling out changes designed to boost posting frequency among users with large friend networks?
One subtle issue might be spamming or low-effort content if users feel nudged to post more than they naturally want to. Another pitfall is that you could create an echo chamber effect where users with large networks become even more insulated within their existing friend clusters, thus reducing their overall content diversity.
There is also a risk that artificially increasing posting prompts user backlash if they sense the platform is pushing them to behave unnaturally. In some cases, new friend connections may not be real friends but acquaintances or tangential connections, possibly causing the user to lose interest if the feed becomes cluttered.
To mitigate these pitfalls, you would conduct small-scale user acceptance tests, monitor feedback closely, and analyze the quality of posts and overall engagement. You might introduce or expand user controls, allowing people to fine-tune or snooze the recommendations if they find them distracting.
Ultimately, any intervention should carefully balance friend growth, post frequency, and user satisfaction, ensuring that no single metric is optimized at the expense of the broader user experience.
Below are additional follow-up questions
How would you incorporate real-time user feedback from the “people you may know” feature to adapt your recommendation approach, given the correlation between large friend networks and fewer posts?
A potential strategy is to capture immediate user reactions to suggested friend recommendations. For instance, if users frequently dismiss certain suggestions or provide explicit feedback like “Not interested” or “I don’t know this person,” these signals help refine the algorithm. On the other hand, if they hover, click through profiles, or add the suggested friend right away, this indicates a positive signal. Over time, you could dynamically update your recommendation model to rely more heavily on signals that correlate with higher post engagement.
A subtle challenge arises if real-time signals are sparse for certain users. In that case, you might have a “cold start” scenario for recommending friends to them, especially if they have not engaged with such features in the past. One mitigation strategy is to incorporate indirect signals (like mutual group membership or comments on the same posts) to enhance the quality of friend suggestions without relying solely on direct user feedback.
Another edge case is that short-term user feedback might differ from long-term user behavior. Users sometimes accept random friend requests impulsively, but in the long run, that does not necessarily encourage them to post more. You would likely need to compare short-term acceptance or rejection rates against longer-term changes in posting frequency. This comparison can guide whether your recommendation engine should be more cautious or more adventurous in suggesting additional connections.
A final pitfall is conflating a user’s acceptance of a friend suggestion with genuine interest in deeper interactions. Some users might simply accumulate connections without ever interacting with them, so you must track deeper engagement signals to ensure you are not optimizing for superficial network growth at the expense of true user satisfaction and posting activity.
How could user privacy or regulatory compliance (e.g., GDPR, CCPA) concerns arise when analyzing or intervening in the correlation between friend count and posting frequency?
One issue is that to study the effect of friend count on posting frequency, you might need detailed user data (e.g., friend graph, posting history, demographic info, and engagement patterns). Regulations such as GDPR in Europe or CCPA in California place constraints on how user data can be collected, processed, and stored. You would have to ensure that all analyses are permissible under these frameworks, potentially requiring updated user consent mechanisms or additional anonymization steps.
Another subtlety is that when you identify a segment of users with large friend networks who post infrequently, you are effectively creating a subgroup based on behavioral data. If you use this information to tailor interventions or suggestions, you must confirm that those actions are in line with the user’s consent about how their data is employed. If the user did not explicitly consent to having their friend-network data used for individualized content nudges, you might risk compliance violations.
In addition, any A/B testing that specifically manipulates how many friend suggestions are shown to certain user groups could be sensitive if the underlying user data is personally identifying. You would need to store or process such data in a secure manner, incorporate robust access controls, and ensure timely data deletion or aggregation to remain compliant. The worst-case scenario is a data leak exposing personal connections or posting habits that could harm user trust and attract regulatory scrutiny.
How would you measure the long-term impact on user-generated content quality if interventions to increase posting frequency are introduced?
You could track engagement metrics such as likes, comments, and shares per post over extended periods, comparing them before and after the intervention. If frequent posting is achieved but each post garners less interaction, you might be diluting content quality or user interest. Conversely, if posting frequency increases alongside stable or improved engagement, it suggests the content quality remains acceptable or is even enhanced.
A significant complication is that measuring “quality” is inherently subjective. You might rely on proxies like comment sentiment or the ratio of comments to views, but these proxies may not perfectly capture user satisfaction. In some cases, user surveys or feedback forms could be introduced to gather qualitative data about perceived content value.
An edge case arises when certain types of user-generated content (e.g., memes or short text updates) receive many quick reactions but do not necessarily contribute meaningful discussion. You might see high engagement metrics yet fail to capture deeper interactions. This scenario highlights the importance of balancing quantitative signals (like reaction count) with more nuanced indicators of healthy conversation or positive user sentiment. Furthermore, you should be wary of spam or low-effort posts that inflate the raw count of content but provide little value.
Another subtlety is that changes in the platform environment—such as major product updates or external societal events—could overshadow the observed impact on post quality, making it challenging to attribute changes solely to your friend suggestion interventions. You would need a robust experiment design and possibly a longer observation window to isolate these confounding effects.
How would you handle scenarios where users shift from feed posts to other platform features (like Stories, Reels, or Messenger) as they accumulate more friends?
First, recognize that feed posting is only one form of content creation. Modern social media users often switch to ephemeral or private channels as their friend networks expand, because they feel it’s more personal or more aligned with current social trends. If you only focus on feed posts, you risk an incomplete picture of user engagement.
To address this, incorporate analytics on alternate content channels. For example, measure how many Stories a user publishes or how many private messages they initiate. If the user is highly active in direct messages or ephemeral formats, the fact that feed posts decline may not be worrisome. It could simply mean the user finds the new format more convenient or perceives it as safer for sensitive content.
A subtle edge case is that you might inadvertently push users away from feed posts by aggressively recommending new friends. If the user’s feed becomes overwhelming, they may switch to smaller group chats or ephemeral content to regain a sense of privacy. This shift might show up as a spike in daily active users for Messenger or group postings, which could mask any negative trend in feed engagement unless you are holistically tracking usage across the platform.
Another pitfall is that in an effort to increase feed posting, you might neglect the user experience in these other channels. If you push too hard on feed-based interactions, you might cause friction for users who naturally prefer ephemeral or private messaging. Ultimately, you would want a balanced approach that acknowledges different engagement formats and respects diverse user preferences.
How could external events or trends overshadow attempts to influence the friend–post relationship, and how would you distinguish those effects?
External events—such as global news, major holidays, or trending social topics—can prompt spikes or drops in posting behavior that have nothing to do with how many friends a user has or how many suggestions they receive. For instance, during a significant world event, users might post more frequently to share news or opinions. Conversely, during holiday seasons, certain demographics might stay offline and post less.
One way to distinguish these external effects from your interventions is through controlled experimentation and time-based segmentation. You might run tests in different geographical regions or user segments that are less affected by a certain event. If the correlation between friend count and posting frequency remains stable in unaffected groups but shifts in the affected regions, you can reasonably conclude that an external factor is at play.
Another approach is to use interrupted time series analysis, where you collect data over a long period and then mark the moment an external event occurs. You can observe whether there is a pronounced change in posting behavior or friend acceptance rates coinciding exactly with that event. If the shift is abrupt and widespread, it likely stems from external drivers rather than internal product changes. A subtlety here is that multiple external events can overlap (e.g., seasonal holidays intersecting with global events), making it challenging to tease apart their individual effects without careful segmentation.
Yet another edge case is that external trends can produce lasting cultural changes in how users engage with social media. Even after the event recedes, user behavior might not return to the old baseline. This means that short-term dips or spikes can morph into new long-term patterns, which complicates your platform-level analytics and the fine-tuning of your friend recommendation algorithms.
How might scaling up the “people you may know” feature globally introduce unforeseen challenges when trying to manage the friend–post dynamic?
When rolling out to a global user base, cultural differences and usage patterns can greatly affect how people respond to friend suggestions. In some regions, the concept of “friend” can be more selective, and users might be wary of adding acquaintances or strangers. In other regions, social norms might favor rapidly building large networks, making friend acceptance more likely but potentially diluting the quality of interactions.
Language differences can also lead to mismatched or irrelevant friend suggestions if your recommendation model does not properly account for local linguistic signals. If the algorithm heavily weights text-based indicators that do not translate well across languages or rely on content categories that are region-specific, you could see lower acceptance rates or lesser posting activity in certain locales.
Another subtlety is regulatory diversity. Certain countries have stricter data protection and content moderation rules. You might face technical constraints on storing user data or analyzing friend graphs, potentially limiting your ability to fully implement the same interventions everywhere. This could result in inconsistent user experiences that affect your overall metrics.
Lastly, as you scale, the computational costs and latency of generating personalized friend recommendations grow. If the “people you may know” feature starts lagging or showing stale suggestions, users may lose trust or interest, negating the positive impact on posting behavior. Monitoring system performance and ensuring an efficient pipeline for updating recommendations is crucial. Even a small delay in refreshing suggestions for millions of users can compound into a significant problem that undermines your entire approach for tackling the friend–post correlation.