
ML Interview Q Series: How would you maximize your chances of selecting the highest-valued piece from 100 unique, sequential artworks?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
This problem is essentially known as a classic optimal stopping problem (often called the “Secretary Problem”). The objective is to pick the most valuable art piece out of 100 distinct items arriving in a random order, with the constraint that you must decide immediately about each piece and cannot return to any passed item.
Intuition
An intuitively strong strategy is to first observe a certain number of items without selecting any of them, carefully noting the best (highest-priced) piece among this initial segment. Then, as soon as you encounter a piece that surpasses the best of that initial group, you pick it. This threshold-based strategy has been mathematically shown to be optimal in terms of maximizing the probability of selecting the absolute best item.
Optimal Threshold (Approximation)
When the number of items n is large, the optimal fraction of items to skip at the start is roughly 1/e (where e is approximately 2.71828). Therefore, one might skip around 36 or 37 pieces when n=100. More precisely, the number of items to skip is approximately:
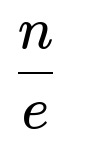
Here, n is the total number of pieces, and e is the base of the natural logarithm.
After skipping and observing this initial segment (to get a sense of the “quality” range), you select the first item that exceeds all the previously observed pieces. Following this plan yields a success probability close to 1/e (about 37%) of identifying the best piece.
Why This Works
By ignoring the first n/e items, you obtain a benchmark for the values without risking early picks on suboptimal ones. If you skip too few, you increase the chance of selecting from a small reference window and missing out on better items that appear later. If you skip too many, you risk running out of items, never seeing one that’s better than the benchmark before the process ends.
Probabilistic Outcome
By applying the skip-then-select rule, the success probability (the probability of picking the single most valuable piece) asymptotically approaches 1/e as n increases. For n=100, it is slightly higher than 1/e, but in practical terms, the difference is not huge.
Example Simulation in Python
Below is a straightforward simulation demonstrating how one could empirically test this strategy for n=100. We randomly generate 100 unique values, randomly permute them, then use the threshold approach to see how often we end up picking the maximum.
import random
def simulate_optimal_stopping(n=100, trials=100000):
import math
skip_count = int(round(n / 2.71828)) # approximate threshold
success = 0
for _ in range(trials):
# Generate unique random values (e.g., from 1..n)
values = list(range(1, n+1))
random.shuffle(values)
# Mark the best in the first skip_count
reference = max(values[:skip_count])
# After skipping, pick the first that exceeds the reference
chosen = None
for v in values[skip_count:]:
if v > reference:
chosen = v
break
# If no chosen item is found, pick the last one in the sequence
# (though in standard approach, you'd have to pick the final item).
if chosen is None:
chosen = values[-1]
# Check if the chosen item is the actual max
if chosen == max(values):
success += 1
return success / trials
prob = simulate_optimal_stopping()
print(f"Probability of selecting the highest-valued piece: {prob:.4f}")
This code helps validate that the strategy consistently yields a success probability around the expected 1/e value.
Potential Pitfalls
• Over-Skipping: If you skip more than approximately n/e items, you might risk not encountering any item better than your reference in time. • Under-Skipping: If you skip too few items, your reference might not be a strong benchmark, causing you to lock onto a piece too early. • Small n: For small sample sizes, the theoretical 1/e rule might not be perfectly optimal. Exact analytic or dynamic programming solutions can be more precise when n is small, but the skip-then-select method is still robust. • Non-Uniform Distributions: If the item values have known structures or distributions that are not uniform random permutations, adjustments to the strategy might be necessary.
Follow-Up Questions
If the number of artworks is not known in advance, can we still apply a similar strategy?
One approach for the scenario where n is unknown is to treat any new piece beyond some “time horizon” as if it belongs to a sequence of unknown length. One might attempt a “look-then-leap” approach, where you observe items for a certain duration (or fraction of total time) to set a benchmark, then proceed to pick the next item surpassing that benchmark. However, the exact mathematical derivation gets more complicated since you lack a precise n value.
How would we adapt if we wanted to pick not just the top item, but the top k items?
When trying to pick the top k items instead of just the single best, the strategy requires multiple stopping rules. One possible extension uses dynamic programming, where you keep track of how many items you’ve picked so far and how many remain. The decision at each step is more complex, as you must decide whether to pick or skip based on the value of the current item and how many picks are left. There is no simple fraction-based formula for this scenario, and the solution might be computationally heavy for large n and k.
What if each piece of art costs a small fee to view, so skipping too many becomes expensive?
Introducing a cost mechanism changes the reward structure. Instead of purely maximizing the probability of selecting the highest value, you might need to weigh the expected net gain after deducting the cost of skipping. This transforms the problem into an optimal stopping problem with payoffs that balance the probability of success against the cost of skipping. The mathematics would involve expected value calculations of net utility, factoring in both the expected item value and skipping costs.
Is there a way to guarantee selecting a “good” piece even if it isn’t guaranteed to be the best?
If your objective is to pick an item that is likely within a certain percentile (like top 10%) rather than strictly the top 1 out of 100, you can modify the skip-then-select method to define a benchmark that represents that percentile. Once you have a reference from the initial portion and you see an item that meets or exceeds that standard, you choose it. The specific fraction of items to skip and the threshold for selection can be determined using distribution-based assumptions and simulation.
These follow-up concerns illustrate the range of practical adaptations and deeper questions that might arise in an interview, demonstrating that the foundational skip-then-select strategy is powerful but not strictly universal for all situations.
Below are additional follow-up questions
What happens if the items do not arrive in a purely random order?
In scenarios where the order is not uniformly random, the skip-then-select rule might not yield the same probability of success. For instance, if there is some adversarial ordering or a distribution favoring higher-valued items earlier or later, the classical 1/e threshold may become suboptimal. One practical adjustment is to gather some side information on how items are likely ordered—for example, if high-value artworks are more common in the middle of the sequence—and shift the skip window accordingly.
A subtle pitfall is assuming randomness without verifying it. If the distribution is adversarial, the strategy could perform far worse than expected. Real-world data might also reflect correlation structures (e.g., “clusters” of artwork types, each with characteristic value ranges), so it is best to evaluate the nature of the order before applying a theoretical model.
How do we approach the problem when certain artworks can have extremely high but rare values?
If some pieces can have outlier values far exceeding the typical range (often called “heavy-tailed” or “long-tail” distributions), the optimal strategy may need to weigh the risk of skipping potentially massive payoffs against the classical 1/e approach. One potential solution is to combine a Bayesian prior on the expected value distribution with dynamic programming, so that when you spot an exceptionally large value (even among the first few), you might deviate from the skip-then-select rule and select it immediately.
The pitfall is underestimating the effect of outliers. If your distribution’s tail is heavy, you might want a smaller skip window because even seeing one or two extremely large values early on can be worth locking in immediately. Conversely, if you overestimate the frequency of large outliers, you might be too quick to grab a moderately high value instead of waiting for something better.
If we're allowed to gather partial information about the next items, how does that affect the strategy?
In some real-life scenarios, you might glean partial signals or indicators about future artworks (e.g., you know the approximate category or region they come from). This partial foresight can make the problem dynamic, in that you can adapt your threshold if future items have a higher or lower expected value than those you have already seen.
A possible approach is to update the benchmark based on new information, effectively blending skip-then-select with an online learning component that refines its estimate of the distribution. A pitfall is relying too heavily on incomplete signals; if your partial information is highly noisy, frequent re-adjustment of the threshold can degrade performance. Balancing the confidence in your prior beliefs with observed data becomes essential.
How would the strategy differ if we had a limited number of “free passes” instead of a strict one-shot skip rule?
In a modified version of the problem, you might be allowed to pass on a limited number of artworks (say k times) but must pick from the rest. This changes the entire structure because you can no longer skip freely until you encounter a candidate that beats the benchmark. Instead, you must consider the trade-off between using up one of your limited passes versus committing to a piece that might not be optimal.
A potential approach is a dynamic programming solution in which the state tracks how many passes remain and how many artworks remain to be seen. At each artwork, you decide to pass or pick based on the expected value of future opportunities. One subtlety is the risk of running out of passes too early, forcing you to pick an inferior piece late in the sequence. Another edge case is if you rarely need to use all your passes and could have afforded a more refined skipping policy.
What if each artwork has a time-varying value that changes the longer you wait?
Sometimes, the perceived or actual value of items can fluctuate with time (e.g., an artwork’s resale market might get more saturated as time goes on). The classical approach assumes a static value, but now you have a moving target. This transforms the objective into picking not merely the highest among static values, but the best time to lock in an art piece given how its value might evolve.
The solution might rely on setting a dynamic threshold that factors in both the observed maximum thus far and your projections of how values might shift over time. A real-world pitfall is incorrectly modeling time decay or appreciation. If your time model is too simplistic, you could end up skipping items that either quickly devalue or ignoring items that might soon become more valuable.
How do we handle multiple rounds of selection with elimination rules?
Consider a setup where the best items from an initial round are carried over into a subsequent round, and so on, until a final pick is made. Each round might resemble a smaller version of the optimal stopping problem, but the dynamic across rounds complicates things. You must evaluate when it’s worthwhile to commit an item to the next round versus searching for better items in the current round.
A major pitfall here is overcomplicating the strategy without a clear dynamic programming framework. If you take a naive approach (e.g., treat each round independently), you might fail to account for the fact that suboptimal picks in earlier rounds can limit your final choices.
How do we adapt if we only want to beat a certain threshold rather than necessarily picking the single highest value?
Sometimes, the objective is to do “good enough.” For example, you might have a certain value in mind that is acceptable (e.g., at least 80% of the best you believe is out there). In that case, you can set an absolute or relative threshold based on your knowledge of the distribution. The strategy might involve calculating an approximate upper bound and selecting the first artwork that meets or exceeds (0.8 * upper_bound).
The subtle pitfall is setting the threshold too high (resulting in never selecting an item if the distribution was overestimated) or too low (resulting in a trivial early pick). In practice, you could estimate the upper bound from historical data or early observations and adapt your threshold as items arrive.
What if the artwork values are not strictly distinct, and ties are possible?
The original problem states each piece has a different dollar amount. However, if ties are allowed, you may find multiple artworks sharing the same top value. In that scenario, simply looking for something strictly higher than your benchmark no longer suffices. One approach is to pick the first artwork that is greater than or equal to the maximum from the skip phase. But if you do that, you might pick a piece that ties with your benchmark but isn’t the overall best if there’s a strictly greater one coming later.
In practice, you could choose a tie-breaking policy that’s more nuanced—for example, only pick an item that’s strictly greater than the benchmark until the final few items, at which point you would accept an item that ties the benchmark to ensure you don’t end up with something worse. A tricky edge case is that you might hold out for a strictly better piece and miss your opportunity to pick the tying piece if the distribution is not favorable.
Is there a scenario where we might leverage a “rollback” option?
Sometimes, systems might allow a limited rollback—perhaps you can revisit the previously skipped item only if the next item is not better. Although this modifies the problem substantially, the principle of setting an informative benchmark can still apply. You might skip a certain number of items, keep track of the best among them, and if you see something in the next position that is better, pick it; if not, you revert to your best from the skip phase.
A major pitfall is incorrectly counting on multiple rollbacks if the rules only allow one or if each rollback has a cost. Dynamic programming can handle these added complexities, but the calculation grows more demanding, and you must be careful not to exceed realistic time or computational constraints in real applications.
How can we statistically test the effectiveness of a chosen strategy using limited data?
One might rely on online A/B testing or Monte Carlo simulations to evaluate various stopping strategies. In practice, you collect a dataset of random permutations of the art pieces, apply your chosen policy, and compute the frequency of success (i.e., picking the maximum). Then, compare this frequency to baseline strategies (like picking randomly or always picking the first item above some percentile).
A subtle pitfall is insufficient test coverage. If the distribution of artworks or their order is diverse, you need to sample enough permutations to see if the policy adapts properly. Another issue arises if the simulation environment does not accurately reflect the real-world process; the performance measured in tests might deviate significantly from production results.