
ML Interview Q Series: How would you go about selecting the activation function for a deep neural network?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Activation functions are crucial in neural networks because they add non-linearity, allowing networks to learn more complex patterns. Without an activation function, the entire network behaves like a linear regression, regardless of depth. There are various activation functions, each with its advantages and drawbacks.
Common Activation Functions
Sigmoid is often represented in plain text as 1 / (1 + e^(-x)). It squashes values into the range (0, 1). However, it saturates for large positive or negative inputs, leading to small gradients and potential vanishing gradient issues.
Tanh squashes values to the range (-1, 1). It is zero-centered, which can sometimes help the training process converge faster than sigmoid. Like sigmoid, it can still saturate for large absolute values of x.
ReLU (Rectified Linear Unit) is defined as taking the maximum of 0 and x. It does not saturate in the positive region, which allows for better gradient propagation. However, its gradient is zero for x < 0, which can cause the “dying ReLU” problem if too many neurons end up with non-positive inputs.
Below is the core formula for ReLU shown with latex:
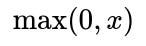
Leaky ReLU modifies ReLU by introducing a small slope for negative inputs instead of completely zeroing them out. This helps mitigate the dying ReLU problem by allowing a small, non-zero gradient for x < 0.
Parametric ReLU extends Leaky ReLU by making that slope a learnable parameter. ELU (Exponential Linear Unit) and SELU (Scaled Exponential Linear Unit) are further variations designed to avoid saturation in the positive region and maintain non-zero outputs for negative inputs.
In many modern architectures (especially those involving transformers), you may see advanced activation functions like GELU (Gaussian Error Linear Unit) or Swish. GELU can yield better empirical performance in certain large-scale NLP tasks, while Swish was introduced by Google to improve gradient flow in deeper networks.
Practical Guidelines
In practice, a good starting choice is ReLU or a ReLU variant (like Leaky ReLU or Parametric ReLU) because it is easy to implement, computationally efficient, and often yields strong performance. If you observe a lot of “dead” neurons (gradients become zero), switching to Leaky ReLU or ELU can help. For tasks dealing with outputs that need to be in a specific range (like probabilities in a final layer), sigmoid or softmax are often used, but typically only at the last layer.
Sometimes, specialized domains might benefit from other activation functions. For instance, recurrent neural networks often use tanh or a gating mechanism (like in LSTM or GRU cells). Large transformer-based networks frequently adopt GELU to improve performance in tasks like language modeling or machine translation.
Example Code Snippet (PyTorch)
import torch
import torch.nn as nn
class SimpleNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, activation='relu'):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
if activation == 'relu':
self.activation = nn.ReLU()
elif activation == 'leaky_relu':
self.activation = nn.LeakyReLU(negative_slope=0.01)
elif activation == 'tanh':
self.activation = nn.Tanh()
elif activation == 'sigmoid':
self.activation = nn.Sigmoid()
else:
self.activation = nn.ReLU() # Default
def forward(self, x):
x = self.fc1(x)
x = self.activation(x)
x = self.fc2(x)
return x
This snippet demonstrates a simple feed-forward network that allows you to easily switch between common activation functions.
Why Activation Functions Matter
Activation functions influence network expressivity, gradient flow, computational stability, and convergence. Issues like the vanishing gradient problem can be alleviated by choosing appropriate activation functions. Also, certain functions help ensure outputs are bounded or unbounded as needed by specific tasks.
Follow-Up Question 1
How can vanishing or exploding gradients affect your choice of activation function?
Vanishing gradients occur when gradients become extremely small, preventing weights from being updated effectively. This is common with activation functions like sigmoid or tanh, particularly when many layers are stacked. Since these functions saturate at large absolute values of x, the network’s gradient flow diminishes.
Exploding gradients occur when gradients accumulate and become excessively large, leading to unstable updates. While exploding gradients can be caused by many factors (including initialization or high learning rates), some activation functions that have unbounded growth can also contribute if not properly handled.
Choosing ReLU or variants such as Leaky ReLU often helps reduce vanishing gradients due to their linear behavior for positive inputs. However, if too many activations remain in the non-positive region for ReLU, dying neurons can become a problem. Proper initialization, gradient clipping, or selecting alternative activations (like ELU or SELU) can further reduce vanishing or exploding gradient issues.
Follow-Up Question 2
Why do we often prefer ReLU as a default activation in deep networks?
ReLU avoids saturation in the positive domain and yields efficient gradient propagation. It is simpler and typically faster to compute than more complex functions like sigmoid or tanh. Empirical results have consistently shown that ReLU-based architectures train faster and converge to better solutions for many tasks, particularly in convolutional neural networks. If a large fraction of neurons die and produce zero outputs, switching to Leaky ReLU or Parametric ReLU can alleviate that problem.
Follow-Up Question 3
When would you use a sigmoid or tanh function in modern networks?
Sigmoid is commonly used in the final output layer for binary classification to output a probability. It is rarely used in hidden layers of a deep network because of saturation issues. Tanh can still appear in recurrent neural networks where the zero-centered nature is beneficial, especially in conjunction with gating mechanisms (as in LSTMs and GRUs). In many feed-forward networks, tanh is less popular for hidden layers, although it can be valuable if the task or architecture specifically benefits from outputs in the (-1, 1) range.
Follow-Up Question 4
How do advanced activation functions like GELU or Swish differ from ReLU?
GELU and Swish both introduce a smoothly varying function that resembles ReLU for large positive inputs but transitions more smoothly around zero, improving gradient flow. GELU uses a Gaussian cumulative distribution term. Swish is x * sigmoid(x). These functions often yield better accuracy in tasks requiring deep models with very large parameter counts, such as large language models. However, they can be more computationally expensive than ReLU, and their benefits might be more pronounced at large scales.
Follow-Up Question 5
What practical considerations are important when choosing an activation function?
Memory usage, computational efficiency, numerical stability, and ease of implementation are all important. For instance, ReLU and its variants are simple element-wise operations that are highly optimized on modern hardware (GPUs and TPUs). Sigmoid or tanh can be more expensive and more prone to floating-point underflow or overflow in extreme cases. When performance is critical, many researchers default to ReLU because of its balance between accuracy, computational efficiency, and stability.
Additional considerations include the domain and range of outputs needed by downstream tasks, potential for vanishing or exploding gradients, and the regularization effect of certain activations (like SELU, which can help enforce self-normalizing properties under certain conditions).
Below are additional follow-up questions
How do normalization layers (e.g., BatchNorm or LayerNorm) interact with the choice of activation function?
Batch normalization or layer normalization can mitigate internal covariate shift by normalizing intermediate activations. This can reduce the sensitivity of a network to certain activation function drawbacks, such as saturation. For example, if you use tanh, which can saturate, applying batch normalization helps keep activations in a range where gradients are less likely to vanish. ReLU variants paired with normalization may reduce the dying ReLU problem because the normalized inputs are less frequently negative or too large. However, you must be aware of the potential overhead of additional parameters and compute costs introduced by normalization layers, especially in large-scale models. In some cases, normalization may reduce or eliminate differences among activation functions, making ReLU, Leaky ReLU, and ELU behave more similarly. However, careful tuning is still necessary, as certain layer-normalized networks might favor smoother activations (like GELU) for stability or performance reasons.
Potential Pitfall: Ignoring the combined effect of activation function and normalization on gradient flow. For instance, combining a high negative slope in Leaky ReLU with batch normalization hyperparameters that are suboptimal can still lead to exploding or vanishing gradients if you do not tune momentum or weight decay properly. Another subtlety is that in recurrent networks, batch normalization can introduce unwanted interdependence among time steps, so other normalization techniques (like layer normalization) are sometimes preferred, which can in turn change the choice of activation function.
What considerations arise when choosing different activation functions for hidden layers versus the output layer?
In many architectures, the hidden layers use activations like ReLU or its variants to capture complex features. Meanwhile, the output layer is often driven by task requirements. For instance, a classification problem with multiple classes typically uses a softmax output layer, a binary classification might use sigmoid at the output, and a regression task might require a purely linear output (no activation) or sometimes a tanh if the target variable is in a certain bounded range. The mismatch between hidden-layer activation ranges and output-layer activation ranges can cause learning instabilities if not handled properly—for example, using a tanh output for an unbounded regression problem can cause the model to struggle when targets exceed the range (-1, 1).
Potential Pitfall: Failing to match output layer activations with the loss function. For example, if you mistakenly pair a sigmoid output with a mean squared error loss for classification, training might behave suboptimally and converge slowly compared to using binary cross-entropy. Similarly, using a linear output for a classification problem can produce poor probabilistic interpretations of the final predictions.
When dealing with gating mechanisms (e.g., LSTMs, GRUs), how does activation function choice come into play?
Gated architectures like LSTM or GRU cells typically incorporate sigmoid and tanh for gates (such as forget gates, input gates, and output gates), because these functions neatly map input values to (0, 1) for controlling information flow. The tanh function is often used to shape the candidate hidden state, taking advantage of its zero-centered nature and limited output range. Despite these common design choices, alternatives like ReLU or Swish can be introduced in experimental architectures to increase expressive power. However, typical RNN gating formulations rely on the bounded range of sigmoids and tanh to implement gating logic, so changing them could alter the fundamental behavior of the recurrent cell.
Potential Pitfall: Replacing standard gating activations with unbounded variants (such as ReLU) might cause unstable recurrent dynamics or exploding hidden states. Additionally, if you switch from a bounded activation to something that does not saturate, the gates may lose their intended on/off interpretability, complicating debugging and interpretability.
Is there any benefit to mixing different activation functions within the same network? How might this be implemented?
Mixing activations can sometimes improve representational diversity. For instance, some advanced convolutional architectures have used multi-branch setups (like Inception modules) that apply different transformations (and sometimes different activations) to the same input. Alternatively, you could randomly assign activation types to different layers or sub-networks. This eclectic design might help the model learn a broader array of features, though gains are not always guaranteed and can depend heavily on the problem and hyperparameter tuning.
Potential Pitfall: Adding excessive complexity can complicate optimization. If you use more than one activation function arbitrarily, it can become difficult to diagnose training issues or to balance gradient flows across different layers. You also risk increasing inference times, which may not be worth minor accuracy gains in production.
How does the choice of activation function impact model interpretability or explainability?
Activations like ReLU produce piecewise linear representations, which can sometimes simplify post-hoc interpretation methods because each neuron either “fires” or remains at zero. In contrast, smooth activations like Swish or GELU blur this boundary, potentially complicating direct interpretation but may yield better performance. When you rely on methods like saliency maps or layer-wise relevance propagation, the shape of the activation function can influence the resulting heatmaps or importance measures. Non-monotonic or bounded activations might be more challenging to dissect in certain interpretability frameworks, but they can sometimes lead to more controlled outputs (e.g., gating signals remain within [0,1]).
Potential Pitfall: Believing that a simpler activation function always yields a simpler interpretation. Even though ReLU is piecewise linear, deep stacks of ReLU layers can create complex, high-dimensional decision boundaries. Conversely, a smooth activation might appear more complex mathematically but could yield easier gradient-based interpretability in some contexts. Always validate interpretability claims by examining real data and possibly comparing multiple methods.
Can the activation function alone influence a network’s theoretical capacity or universal approximation capability?
Neural networks with piecewise linear activations (such as ReLU) are universal function approximators given sufficient depth and width. Similarly, using smooth nonlinear functions like sigmoids, tanh, or Swish does not hinder universal approximation. However, the ease and speed of achieving that approximation in practice can differ greatly. A saturating nonlinearity may prolong or stall training because gradients vanish at extremes of input values. Meanwhile, piecewise linear activations often train faster but may introduce corner-like decision boundaries that require deeper networks to approximate smooth functions.
Potential Pitfall: Believing that any single activation function is universally best. Even though the network can theoretically approximate a wide range of functions, practical aspects like training dynamics, initialization schemes, and hardware constraints still determine final performance. In some specialized tasks (e.g., wavelet-based signal reconstruction), carefully chosen activation functions might better align with domain-specific transformations.
Are there specific activation function considerations for extremely large-scale models or specialized hardware (e.g., TPUs)?
When scaling models to billions of parameters (like large language models), the activation function’s computational cost and memory footprint become critical. ReLU is efficient to compute and memory-friendly. Functions like GELU or Swish might yield small accuracy improvements but are more expensive to compute. On TPUs and GPUs, specialized kernels exist to optimize certain activation functions, so the actual cost might be less than theoretical. Nevertheless, repeated use of complex activation functions can significantly contribute to overall runtime in massive models.
Potential Pitfall: Assuming a small difference in runtime per layer has no effect at scale. In large-scale training, every fraction of a millisecond counts. Even a slight overhead can multiply across thousands of GPUs or TPUs for days or weeks of training. Additionally, some hardware accelerators may have quantization or floating-point precision constraints that interact negatively with certain activation functions, potentially leading to reduced training stability or suboptimal performance if the function outputs or gradients clip or overflow.
How might the input data distribution or preprocessing steps guide the activation function choice?
If your input data is normalized or standardized around zero, zero-centered activations (like tanh or ELU) may behave better initially because they keep outputs near the center of that distribution. If your data has large positive values, ReLU can be straightforward, but you might risk saturating or “dying” units if the distribution shifts over time. In scenarios where data contains negative values with wide variance, a variant like Leaky ReLU or SELU can preserve some information in the negative domain.
Potential Pitfall: Neglecting to maintain a consistent data distribution over time. If your training data is well-centered but the inference data drifts, the chosen activation function might start performing poorly due to mismatch in expected input ranges. Monitoring data distribution in production becomes essential to ensure stable model outputs, especially for streaming applications where distribution shifts can occur.