
ML Interview Q Series: How would you describe a Super Learner Algorithm, and what is its fundamental idea in ensemble learning?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
A Super Learner is an ensemble method that systematically combines multiple predictive models (often called base learners) in a way that typically yields better performance than any individual model alone. The method leverages the strengths of different types of learners—such as linear models, tree-based models, and more complex machine learning algorithms—and learns the optimal way to aggregate their predictions. This optimal aggregation is itself learned through a meta-model, which is often trained on out-of-fold predictions of the base learners.
In simple terms, a Super Learner proceeds in two major steps:
It first trains multiple base models on the training data. Each of these base models can be very different in nature (for example, a logistic regression, a random forest, and a gradient-boosted tree).
It then builds a meta-learner that takes as input the predictions of these base models (usually acquired via cross validation) and learns how to optimally weight or combine these predictions.
The essence is that by carefully using cross validation to generate unbiased predictions from each base learner, the meta-learner can learn a combination strategy that generalizes well to unseen data.
Core Mathematical Representation
Below is a central formula for how the Super Learner combines the base learners for a regression task. Let there be k base learners f_1, f_2, ... , f_k, each producing a prediction f_j(x). Suppose we find the optimal set of weights alpha_1, alpha_2, ... , alpha_k that minimize a chosen loss function on the out-of-fold predictions. The final prediction of the Super Learner is represented by:
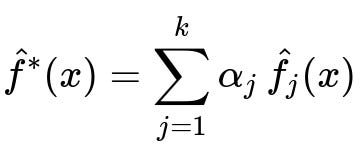
Here, hat{f}_j(x) is the prediction from the jth base model for the input x, and alpha_j is the learned weight for the jth base model. In many implementations, these alpha_j values are found by fitting a secondary machine learning model (the meta-learner) on the base models' out-of-fold predictions rather than by just solving for a simple weighted average.
Key Steps to Build a Super Learner
A typical workflow for building a Super Learner can be outlined in the following way (though this is presented here as descriptive text, not as a numbered list):
Train multiple candidate base models on the training set. These base models can vary in complexity, from simple linear regressors to deep neural networks.
Obtain out-of-fold predictions for each base model by using cross validation. For each model, split the data into folds, train on k-1 folds, and predict on the held-out fold. Collect these out-of-fold predictions across the entire dataset.
Use these out-of-fold predictions as input features to a meta-learner, alongside the original ground-truth labels as the meta-learner’s target. Train the meta-learner to learn the optimal combination of the base models' predictions.
When making predictions on new (unseen) data, generate the new-data predictions from each base model and then feed these predictions into the trained meta-learner to get the final ensemble prediction.
Example of a Python Implementation
Below is a short illustrative example in Python. We will use scikit-learn’s StackingRegressor (or StackingClassifier for classification) as a simplified demonstration of a Super Learner approach. Though true “Super Learners” usually rely on a custom cross-validation mechanism for meta-learning, stacking in scikit-learn captures the same principle.
import numpy as np
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import StackingRegressor
from sklearn.model_selection import train_test_split
# Load a regression dataset (Boston Housing for demonstration)
X, y = load_boston(return_X_y=True)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define base learners
base_learners = [
('lr', LinearRegression()),
('rf', RandomForestRegressor(n_estimators=50, random_state=42))
]
# Define meta-learner
final_estimator = LinearRegression()
# Create the stacking regressor (Super Learner style)
super_learner = StackingRegressor(
estimators=base_learners,
final_estimator=final_estimator,
passthrough=False, # Only pass predictions, not the original features, to meta-learner
cv=5
)
# Train
super_learner.fit(X_train, y_train)
# Evaluate
score = super_learner.score(X_test, y_test)
print("Super Learner R^2 on test set:", score)
In a more general Super Learner implementation, you might manage the out-of-fold predictions yourself to ensure that each base model’s predictions for a given data point never use that data point during training. You would then feed these out-of-fold predictions into any machine learning method of your choice as the meta-learner.
Potential Pitfalls and Real-World Usage
Super Learners are computationally more expensive than training a single model. You are effectively training many base models (sometimes multiple times via cross validation) plus a meta-learner. This can become time-consuming with large datasets or very complex models.
Improperly set cross validation or insufficient data can lead to overfitting. If the meta-learner sees predictions that are overfit or correlated in certain ways, it may learn weights that do not generalize well.
Having too many similar base learners can limit the diversity of predictions. The Super Learner algorithm works best when base learners vary significantly in their inductive biases.
In practice, it’s often helpful to do some form of feature engineering or parameter tuning for each base learner to get them near their best performance. A poor base learner might degrade the ensemble if it introduces confusing signals.
Follow-up Question: How Do We Choose the Base Learners?
It is critical to include base learners that differ in structure or modeling assumptions so they can complement each other. For instance, a linear model that excels at capturing linear relationships might pair well with a tree-based model that captures non-linearities. Including both simple and complex models can also be beneficial. However, it is important to avoid only repeating nearly identical models because the meta-learner might not gain much additional information.
Follow-up Question: Why Is Cross Validation So Crucial for a Super Learner?
Cross validation ensures that each base learner’s predictions used for training the meta-learner are generated without any data leakage. In other words, each prediction is truly out-of-sample. This unbiased prediction is what allows the meta-learner to learn how well each base learner generalizes. Without cross validation, the meta-learner risks seeing overfitted predictions, making the final ensemble perform poorly.
Follow-up Question: How Is This Different from Simple Averaging or Bagging?
Simple averaging or bagging typically combines learners by equally weighting their predictions or by sampling data to train an ensemble of the same model type. The Super Learner, by contrast, uses a dedicated meta-learner to discover the best way to combine each base model. Instead of assuming all models contribute equally, the meta-learner can assign adaptive weights (even zero) to certain models based on their out-of-fold performance.
Follow-up Question: Can the Meta-learner Be Any Model?
Yes, the meta-learner can be any machine learning model capable of regression or classification. Often, a simple linear model is used if the goal is interpretability. But more complex models (like neural networks or gradient-boosting machines) can also serve as meta-learners, which might provide an even better fit if there is sufficient data to train them.
Follow-up Question: What Are Some Edge Cases Where a Super Learner Might Fail?
When the dataset is very small, the cross validation used in the Super Learner can introduce too much variance in estimates of the base learners’ performance. This can lead to a poor meta-learner.
When the base learners are nearly identical or highly correlated, the meta-learner might not find any significant improvement over a single model.
When there is extreme class imbalance or unusual data distributions, specialized techniques may be needed for the base learners or the meta-learner to handle those issues effectively.