
ML Interview Q Series: How you can extract useful features from Date and Time column if any?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Extracting meaningful features from date and time data can significantly enhance the performance of a model, especially when the target variable exhibits temporal patterns or trends. The process involves decomposing raw timestamps into more informative or interpretable attributes.
Extracting Basic Features
Date and time columns can often be decomposed into simpler components. For example, one can extract the year, month, day, hour, minute, second, or day-of-week. These features can help capture seasonality or cyclical trends in data.
Year can capture long-term trends. Month can reflect seasonal behavior (e.g., peak sales in December). Day-of-month can capture monthly periodicity. Day-of-week can capture weekly cycles. Hour-of-day can capture daily fluctuations (such as user activity peaking in the morning or evening).
Cyclical Encoding
Some of these features, like day-of-week or hour-of-day, are cyclical. For instance, hour=23 is actually very close to hour=0 (one hour apart), but numerically the values 23 and 0 seem far apart. This can lead to inaccuracies if we treat time as purely linear. A common approach is to transform time-based features using sine and cosine transformations to reflect their cyclical nature.
Below is a key mathematical representation of cyclical encoding for a time-related value t in the interval [0, T), where T might be 24 (hours in a day) or 7 (days in a week):
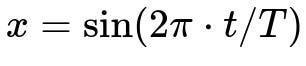

In these formulas:
t is the raw time value (e.g., hour-of-day from 0 to 23, or day-of-week from 0 to 6).
T is the period (24 for hours, 7 for days of the week, 12 for months in a year, etc.).
x and y become two new features that place t on a unit circle, so hour=23 and hour=0 end up being adjacent points in the 2D plane.
Handling Time Zones and DST
When timestamps span multiple regions, time zones and daylight savings time (DST) shifts become important. One approach is to convert all timestamps to a common reference such as UTC. Another approach is to store both the local time and the UTC offset so that models can learn the effect of local time directly.
Rolling and Lag Features
For time series tasks, engineers often create lag features. For instance, if you are predicting daily sales, you might add the sales value from the previous day or previous week as a new feature. Similarly, rolling means or sums over a window can help capture short-term trends.
Example in Python
Below is a simple demonstration of how to transform a Pandas datetime column into various features. This sample shows year, month, day-of-week, hour, minute, day-of-year, and cyclical transformations for hour-of-day.
import pandas as pd
import numpy as np
# Example DataFrame
df = pd.DataFrame({
'timestamp': pd.date_range('2025-01-01', periods=5, freq='6H')
})
# Convert timestamp to datetime if not already
df['timestamp'] = pd.to_datetime(df['timestamp'], utc=True)
# Extract basic features
df['year'] = df['timestamp'].dt.year
df['month'] = df['timestamp'].dt.month
df['day_of_month'] = df['timestamp'].dt.day
df['day_of_week'] = df['timestamp'].dt.weekday
df['hour'] = df['timestamp'].dt.hour
df['minute'] = df['timestamp'].dt.minute
df['day_of_year'] = df['timestamp'].dt.dayofyear
# Cyclical encoding for hour (T=24)
df['hour_sin'] = np.sin(2 * np.pi * df['hour'] / 24)
df['hour_cos'] = np.cos(2 * np.pi * df['hour'] / 24)
print(df)
In this example, the two columns hour_sin and hour_cos represent cyclical versions of the hour-of-day feature.
Potential Follow-Up Questions
How do you handle missing or partial time data?
If timestamps are missing or incomplete (e.g., no hour/minute information), one strategy is to extract only the components that you can reliably derive. If you only have the date, you can still extract day-of-week, day-of-year, and so on. For missing timestamps, you might treat them as a separate category or try to impute them if there is enough domain knowledge. In time series data, one might use interpolation methods based on surrounding values.
Why is cyclical encoding important for time-based features?
If you encode hours or days of the week as numeric values (e.g., 0 to 23 for hours), standard distance-based models would interpret hour=23 as very different from hour=0. However, we know that hour=23 and hour=0 are only one hour apart. The sine-cosine transformation solves this by placing them close to each other on a circular space. Without cyclical encoding, the model could learn incorrect distance relationships among time values, potentially harming performance.
What are advanced ways to represent seasonal patterns in time series?
In addition to sine-cosine transformations, more advanced methods include Fourier series expansions that capture multiple frequencies of seasonality. Some time series models, such as SARIMA or Prophet, can automatically handle multiple seasonalities by decomposing the time component into different frequencies. Neural networks can also learn seasonality if provided with relevant transformations, or if they are structured as temporal models (like LSTMs or Transformers) that include positional or temporal encodings.
How do you handle time zone differences in multi-region data?
It is often best to standardize all timestamps to a single reference time zone (such as UTC). This makes it simpler to align data from different regions. Additionally, you can preserve the local offset in a separate feature to help the model learn behaviors tied to local times. If daylight savings changes occur, either keep track of DST transitions (storing a binary indicator for DST vs. non-DST) or convert everything to standard time (UTC) and include location-based features so the model can account for regional variations.
How can feature extraction from date-time data affect model performance?
Depending on the nature of the problem, time-based feature engineering can dramatically boost predictive power. For instance, if the target variable exhibits daily cycles (like website traffic or energy consumption), properly engineered date-time features often help the model capture those repeated patterns. Conversely, over-engineering or incorrectly handling time zones or DST can inject noise, so it is crucial to consider domain knowledge and correct usage of time transformations.
Below are additional follow-up questions
How do you handle date-time features when dealing with extremely large datasets where memory and computation become bottlenecks?
When working with very large volumes of data, date-time feature extraction can become an expensive operation, especially if you repeatedly parse timestamps into multiple components. It is often beneficial to convert timestamps into numeric representations (like UNIX epoch time in seconds or milliseconds) ahead of time, then compute the derived features in a batch-oriented manner. This can minimize repeated parsing overhead.
You can also consider distributed processing frameworks such as Spark or Dask to distribute the workload of parsing and feature engineering across multiple workers or machines. Another strategy is to store pre-computed date-time attributes (for instance, store year, month, day-of-week directly in the data warehouse) so that these transformations do not have to be performed in real-time.
Memory-wise, you might avoid storing all intermediate transformations at once; instead, generate and store each feature sequentially, dropping large intermediate structures if they are no longer needed. If you are using a streaming context, you would compute features incrementally in small batches. The key is to design a pipeline that does not repeatedly parse or transform the same timestamps and to leverage efficient data representations (such as numeric timestamps) whenever possible.
How do you deal with domain-specific time features such as holidays, business hours, or special events?
Domain-specific time features are often critical for capturing patterns that are not strictly cyclical but occur according to cultural or organizational schedules. For instance, shopping behavior may spike during public holidays or follow a different pattern on weekends. In such cases, you might create custom flags or binary indicators for these events, such as a is_holiday flag, or store partial business hour windows as a separate feature (e.g., within_business_hours is 1 if the timestamp falls between 9 AM and 5 PM).
For holidays, you can maintain a reference calendar that lists holidays for each region and merge that with your dataset. This helps models learn that certain dates might have different behavior than typical weekdays. Special events such as product launches or promotional sales periods can be handled similarly by adding features indicating these event time windows. Real-world pitfalls arise when events or holidays differ across geographic regions, which requires carefully matching each timestamp with the appropriate holiday calendar.
In a real-time or streaming environment, how do you continuously incorporate new date-time data without reprocessing your entire dataset?
In streaming or real-time scenarios, you often have a pipeline that ingests each new record (or micro-batch) as it arrives. Once you convert the timestamp to a date-time object, you can immediately extract features such as hour-of-day, day-of-week, or cyclical transformations. Because this is done record by record, you avoid having to reprocess your entire historical dataset. You simply maintain the same transformations as part of your real-time pipeline.
If you also have time-based aggregations or rolling features, you can maintain a rolling window in memory (or in a stateful store) to compute means, sums, or lags without scanning the entire dataset. Systems like Apache Flink, Spark Structured Streaming, or Kafka Streams provide built-in capabilities for maintaining stateful windows that allow the incremental computation of these time-based features. The main challenge is keeping track of partial windows when the stream experiences delays or out-of-order events, so you need to decide how to handle late-arriving data. For strictly real-time predictions, you may accept some data might come after the prediction is made, or you may design a small time buffer to accommodate minor delays.
How might date-time features introduce data leakage, and how can you mitigate it?
Data leakage occurs when information from the future leaks into the training data, inadvertently giving the model hints it would not realistically have at prediction time. One subtle example is extracting the day-of-year or hour-of-day from timestamps that actually come after the event you want to predict. Another scenario is when the date-time is correlated with the target in a way that the model can overly rely on temporal clues rather than true causal factors.
To mitigate this, ensure that any feature derived from time is something that would be genuinely known at the moment of prediction. For example, if you predict daily demand, you can safely use yesterday’s date-time features but not tomorrow’s. Similarly, be cautious with lag or rolling features: a 7-day rolling mean must not leak future values into the training data. Splitting your data according to time (train on past data, validate/test on future data) is a robust way to check for potential leakage. You can also carefully define your pipeline such that each transformation step only accesses data up to the prediction timestamp.
How do you handle time-related features in unsupervised learning tasks such as clustering?
In many clustering contexts, you might want to group data points based on time-of-day usage patterns or seasonal behavior. A straightforward approach is to generate the same date-time features (hour-of-day, day-of-week, cyclical encodings, holiday flags, etc.) and feed them into the clustering algorithm. For time-series datasets, you might also consider sequence-based methods that handle entire time windows at once (e.g., dynamic time warping for sequence similarity) rather than working with single points.
When preparing features for clustering, it is crucial to scale them appropriately. For instance, if you convert a timestamp into a day-of-year number, that raw integer may overshadow other smaller-scale numeric features. You might apply standard normalization or use sine and cosine transformations for cyclical features. Another subtlety is deciding whether to cluster entire time windows or individual data points. Clustering windows (e.g., daily patterns) can reveal distinct seasonal groupings, while clustering individual timestamps usually highlights within-day cycles. An edge case arises if your dataset spans multiple years, because the same calendar day in different years might have different underlying conditions (such as economic changes). You can address that by including the year or using time normalization if you want to compare patterns across multiple years consistently.