
ML Interview Q Series: In Reinforcement Learning, how can a reward function be translated into a cost function, and pitfalls?


📚 Browse the full ML Interview series here.
Hint: Consider negative rewards and issues like sparse or delayed rewards.
Comprehensive Explanation
One common practice in Reinforcement Learning is to frame the objective in terms of maximizing the return (sum of discounted rewards) rather than minimizing a cost. However, in some scenarios (for example, certain control problems or contexts borrowed from classic optimal control theory), it can be more intuitive to define a cost function and then minimize it. The simplest way to convert a reward function into a cost function is to take the negative of the reward. If we denote the reward function by R(s, a) for taking action a in state s, then the cost function C(s, a) can be written as:
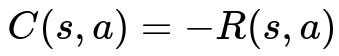
Where:
s is the state in which the agent finds itself.
a is the action taken in that state.
R(s, a) is the reward (potentially including immediate or step reward).
C(s, a) is the corresponding cost.
Minimizing this cost is equivalent to maximizing the original reward. Despite this conceptual straightforwardness, there are pitfalls and subtleties:
Turning Negative Rewards into Positive Costs If the original reward function is significantly negative (for instance, very large negative rewards when certain actions are taken), transforming it directly might yield very large positive costs. This can change the numerical scale of your optimization objective, potentially causing issues with training stability or requiring careful tuning of hyperparameters such as learning rates.
Sparse Rewards If the reward is sparse—meaning the agent only gets a reward after a long sequence of actions—then the cost function will similarly be zero for most of the trajectory until the agent achieves a certain outcome (or not). This poses the same exploration challenges as with sparse rewards. Simply negating the reward does not resolve the fundamental issue of sparse signals.
Delayed Rewards When rewards are delayed, the agent may not see the consequence (either positive or negative) of its actions until much later. Converting the reward function into a cost function by negation does not address or mitigate the delayed nature. The training algorithm must still figure out how to credit or blame an action that led to a reward or cost several steps (or episodes) later.
Interpretation and Convention Reward functions typically reflect how “good” it is to be in a certain state or to take a certain action. Cost functions, on the other hand, describe how “bad” it is. Mixing conventions can create confusion if different parts of the code or different team members interpret the sign differently. Consistency in your codebase and documentation is vital.
Example in Python Below is a simplistic example showing how one might convert a reward-based environment to a cost-based approach in a pseudo-RL setting:
class RewardEnv:
def __init__(self):
pass
def step(self, action):
# Hypothetical next_state calculation
next_state = ...
# Hypothetical reward
reward = self.reward_function(next_state, action)
done = ...
return next_state, reward, done
def reward_function(self, state, action):
# Return a positive reward if certain condition is met
if state == 'goal':
return 10
else:
return -1
class CostEnv:
def __init__(self, reward_env):
self.reward_env = reward_env
def step(self, action):
next_state, reward, done = self.reward_env.step(action)
cost = -reward # Convert reward to cost
return next_state, cost, done
In the CostEnv, we simply replace the original reward with its negative. This is straightforward, but care must be taken in algorithmic design (e.g., using gradient-based methods or planning algorithms) to ensure the environment’s scale and sign conventions match what the RL framework expects.
Follow-Up Questions
How do you handle situations where the scale of the reward function leads to large or small cost magnitudes?
One must ensure numerical stability. If the original reward has very large magnitude (positive or negative), simply negating it might produce excessively large costs that could destabilize learning algorithms. Common strategies include:
Normalizing or scaling the reward before negating it.
Introducing clipped rewards/costs to keep values within a certain range.
Carefully adjusting discount factors and learning rates to account for the transformed scale.
In practice, do modern RL algorithms handle cost functions differently from reward functions?
Most popular deep RL libraries (such as those built on PyTorch or TensorFlow) expect to maximize returns. The underlying algorithms (like Q-learning, policy gradients, or actor-critic methods) traditionally assume a reward formulation. When a cost function is provided, it is typically just negated internally, or the objective is similarly converted so that the algorithm is still maximizing some objective. Conceptually, it is equivalent, but the code’s implementation details often assume “reward” rather than “cost,” so consistent sign conventions are important.
What challenges arise when rewards are sparse or delayed, and does negating them solve those challenges?
Sparse or delayed rewards introduce significant challenges in exploration. Negating the reward does not inherently address these issues. The agent still receives almost no training signal until the end of an episode (in the case of delayed reward) or rarely if the reward is very sparse. Advanced techniques like reward shaping, hierarchical reinforcement learning, curiosity-driven exploration, or distribution-based methods are often used to address these challenges. Merely taking the negative of a sparse or delayed reward leaves you with a sparse or delayed cost, so the fundamental difficulty remains.
Does introducing cost shaping (similar to reward shaping) carry the same caution about altering the optimal policy?
Yes. Cost shaping, like reward shaping, can accidentally modify the optimal policy if not done carefully. If you add a shaping term to your cost function that changes the difference in returns (or costs) between actions in a way that is not purely potential-based, you could drive the policy to suboptimal behaviors. A good rule of thumb is to ensure that any shaping function is a potential function that depends only on the state (or state-action) so that the difference between state transitions remains consistent with the original objective.
Would you ever directly combine both a cost function and a reward function in the same RL environment?
Some specialized environments might define a penalty for certain actions while also providing a reward for accomplishing certain goals. In principle, these can be combined into a single reward or cost signal (e.g., total reward = main_reward + penalty, or total cost = main_cost + penalty). In practice, it is often clearer to combine them into one scalar so that the agent’s optimization objective remains single-dimensional. Keeping them separate is possible, but then your algorithm needs a mechanism to handle multi-objective optimization, which complicates the approach. For instance, multi-objective RL can handle multiple cost and reward signals, but that is more complex to implement and interpret.
Are there any typical discount factor considerations when switching from a reward function to a cost function?
Yes. If your reward-based approach uses a discount factor gamma, it typically scales future rewards by gamma^t. Switching to a cost-based view means you would scale future costs similarly. If the costs become large, you might consider adjusting gamma to ensure that future costs do not dominate or vanish too quickly. The interplay between the magnitude of cost values and the discount factor can influence learning stability, so re-tuning gamma might be necessary.
In real-world control settings, how might a cost function differ from a reward function in terms of design methodology?
In classical control contexts, practitioners often start with a cost function that captures deviations from a desired setpoint, energy consumption, or jerk minimization. The sign convention is chosen from the start. In reinforcement learning contexts, reward is often introduced in a more heuristic manner: “Reward the agent for reaching the goal, penalize it for collisions or actions taken.” When bridging these two worlds, it is essential to maintain consistent sign conventions and ensure that the magnitude of the penalty or cost is aligned with real-world engineering priorities. Sometimes, domain experts will prefer cost-based design for interpretability and alignment with classical control theory (like in linear quadratic regulators), while RL experts might prefer reward-based design because many RL algorithms are described in reward terms.
Below are additional follow-up questions
Could using a cost-based approach cause confusion for domain experts accustomed to thinking in terms of rewards?
When a domain expert is deeply familiar with a reward-based framework, directly switching to a cost-based approach might cause misunderstandings or misalignment in objectives. This is because most Reinforcement Learning formulations present outcomes in terms of benefits (rewards), and domain experts often develop strong intuitions around positive feedback or bonus signals. In cost-based settings, the perspective shifts to penalizing unwanted behavior rather than rewarding desirable outcomes. While mathematically these two views are equivalent (cost = -reward), the interpretation can differ significantly in practice.
A key pitfall is that domain experts may inadvertently design cost functions that are too heavily penalizing, leading to conservative policies. They might also have difficulty tuning what is effectively a “negative reward,” since deciding how large a cost should be is less intuitive if they are used to assigning positive rewards for positive outcomes. In addition, if the environment or the domain is typically described with positive incentives (e.g., a financial bonus for achieving production goals), flipping this into a cost might obscure the real-world motivation. Maintaining clear documentation, involving domain experts in iterative cost tuning, and checking that the final outcomes remain aligned with real-world incentives are crucial steps to mitigate confusion.
How does partial observability affect the design of a cost function versus a reward function?
In partially observed environments (POMDPs), the agent does not have direct access to the true state and must rely on observations that carry limited or noisy information. Whether you use a reward or a cost function, the core learning challenge is the same: the agent must infer the hidden state or rely on belief states to act optimally under uncertainty. However, when designing a cost-based approach, there are a few nuances to consider:
If you implement cost shaping, you can inadvertently mislead the agent more easily because the agent is already unsure about the true state. If the cost is incorrectly attributed (for instance, if an event triggers a penalty at the wrong time because the agent's partial observation lags behind reality), you could see erratic updates in the policy. The partial observability might amplify any issues with the sign or the scale of the cost. If costs are large and the agent only receives them after a delay or when the true state is uncertain, it becomes more difficult to assign credit or blame to the correct actions and states. This can complicate temporal credit assignment.
It’s essential to carefully design how the cost is distributed over states and transitions. Sometimes, domain knowledge can help shape the cost in a way that aligns with partial observability, such as penalizing “dangerous” observations to encourage the agent to gather more information. Yet the fundamental complexities of partial observability—where the agent might not fully realize which states it is in—remain, regardless of using costs or rewards.
How do negative rewards or costs play out in multi-agent RL settings, and what unique challenges arise?
In multi-agent Reinforcement Learning, each agent typically optimizes its own objective while coexisting (and possibly cooperating or competing) with other agents. Using negative rewards or a cost function in such environments can create additional complexities:
Competitive settings If one agent’s reward is another agent’s cost, or if an agent’s success directly translates to another’s penalty, the interactions can become highly adversarial. This can lead to unstable or chaotic training if the magnitude of negative rewards (or costs) is too large, causing agents to repeatedly drive each other into heavily penalized regions with no productive outcome. Balancing the cost scale among multiple agents is a subtle challenge.
Cooperative settings In fully cooperative scenarios, the team might share a global reward or global cost. Converting that global reward into a global cost (i.e., cost = -reward) is mathematically straightforward, but each agent’s partial control and partial observation may mean it is difficult to figure out who contributed to the negative outcome. If costs are distributed unevenly across agents, you risk scapegoating or overshadowing contributions from certain agents.
Mixed settings Many real-world multi-agent settings are neither purely competitive nor purely cooperative. If the environment is designed to penalize conflict behaviors, but also reward certain collaborative behaviors, simply flipping everything to costs can distort incentives. A thoughtful approach could combine local costs or penalties for destructive actions and global shared costs or rewards for cooperative outcomes.
Ultimately, multi-agent RL with cost-based frameworks must address how costs are allocated or shared, ensure each agent interprets the cost consistently, and handle potential emergent adversarial or collusive behaviors.
Does the sign of the reward or cost influence how exploration strategies should be designed?
Most exploration strategies (e.g., epsilon-greedy, entropy-based, or curiosity-driven approaches) don’t inherently depend on whether the environment’s signal is defined as a reward or a cost. They focus on trying out new actions or states to reduce uncertainty about the environment’s dynamics and the value function. However, the magnitude and sign of the feedback can subtly affect how exploration is carried out:
If the cost function frequently yields large penalty values, an agent might become overly cautious, avoiding certain actions prematurely. It can then fail to explore enough of the state space to find potentially beneficial states. If the environment has a mix of small negative rewards and a few large positive rewards, simply negating them means you now have small positive costs and a few large negative costs, which may skew the agent’s exploration in ways that differ from the original reward-based approach. In curiosity-driven strategies, an agent seeks novel states or transitions for an intrinsic reward. If you convert the environment’s external reward into a cost, you must ensure that your intrinsic exploration bonus is still combined in a coherent manner. In some frameworks, the agent tries to maximize (external_reward + curiosity_reward). When dealing with costs, you might have to carefully adjust the formula (e.g., minimize external_cost - curiosity_reward) or something equivalent, which is not always straightforward.
Thus, while the fundamental purpose of exploration remains the same in cost-based or reward-based settings, you may need to recalibrate certain parameters (like the scale of exploration bonuses) or adapt the approach if the cost is strongly negative and overshadowing any curiosity-driven term.
What happens if the agent encounters an infinite negative reward (or infinitely large cost), and how do we prevent unbounded returns?
In some poorly constructed or ill-defined environments, the agent might be able to exploit a loophole to accumulate infinite positive reward or, conversely, might suffer unbounded negative rewards (i.e., unbounded positive costs if we flip the sign). This might occur if there is a cyclical sequence of states and actions that yields repeated negative rewards. Translating to cost terms, the agent could end up in a feedback loop of infinite cost, effectively crippling the learning process:
If the environment transitions allow an agent to keep looping in a cycle that yields negative reward each time, that becomes an infinitely large cost. The agent’s value function might diverge, or the learning algorithm may saturate with large negative updates that overshadow all other experiences. To avoid unbounded returns (positive or negative), environment designers often place constraints such as episode termination after a maximum number of steps, or they clamp reward/cost values within a reasonable range. This bounding ensures that no state-action loop can generate infinite accumulative feedback. From a practical standpoint, many RL algorithms implement stable numerical bounds on advantage or Q-value estimates, or they clip gradient updates to avoid exploding values. Therefore, while the possibility of infinite cost can exist in theory, in real-world or simulation-based training, environment design and algorithmic safeguards typically prevent the agent from ever encountering truly infinite accumulations.
How can one effectively debug when an RL agent fails to learn under a cost-based framework compared to a reward-based setup?
Debugging RL systems is already a non-trivial task, and using a cost-based approach can add extra complexity if your tooling and mental models are more familiar with reward-based signals:
Check sign inversions Ensure that the environment and the algorithm are consistently using cost signals. A common error is mixing up the sign somewhere in the code, leading the agent to do the opposite of what was intended.
Inspect value or Q-function outputs Monitor the learned value function or Q-values (depending on the algorithm). If all values quickly become extremely negative (or extremely positive if you flip signs incorrectly), it signals that the cost function might be too large in magnitude or incorrectly scaled.
Look for overshoot or extremely conservative policies When negative rewards (i.e., cost) dominate, the agent could constantly pick the “least damaging” action rather than seeking to improve. This indicates that either the cost is not balanced, the discount factor is not well-tuned, or the policy update has become unstable.
Visualize trajectories and final policies In environments where you can observe agent behavior, watch how it moves or acts. If it seems overly risk-averse or stuck, that might be due to cost signals overwhelming any incentive to explore. Conversely, if it acts chaotically, your cost might be too small or incorrectly applied.
Test a baseline reward-based environment If you can easily revert to a reward-based environment, do so to confirm that the rest of your learning infrastructure is functional. If the agent learns well with rewards and struggles only when you switch to costs, that indicates the primary issue is in your cost conversion or the sign and scale of the signals.
By systematically tracking the agent’s learned values, its policy behaviors, and potential sign-mismatch bugs, you can isolate whether the cost-based approach itself is flawed or if other factors—like discount rates, algorithm hyperparameters, or environment design—are at fault.