
ML Interview Q Series: In what way can you determine the eigenvalues for a given matrix, and would you demonstrate a practical example?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Eigenvalues are scalars associated with a square matrix that characterize how this matrix acts on certain special vectors known as eigenvectors. Specifically, an eigenvector of a matrix A remains parallel to its original direction after A is applied, merely scaled by some factor (the eigenvalue).
A common method to find eigenvalues is to solve the characteristic equation. For a square matrix A of size n x n, we often look for values lambda such that the determinant of (A - lambda I) is zero. This is the condition that ensures the existence of a non-zero vector x satisfying A x = lambda x.
Here is the central formula for computing eigenvalues:
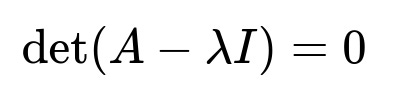
where A is the matrix in question, I is the identity matrix of the same dimension as A, and lambda is a scalar. By expanding this determinant, we end up with a polynomial in lambda (often called the characteristic polynomial). The roots of this polynomial are the eigenvalues.
To illustrate, consider a 2 x 2 matrix A = [[2, 1], [0, 3]] as a simple example. This matrix is upper triangular. The eigenvalues of an upper (or lower) triangular matrix are simply the elements on the main diagonal. So one can see right away that the eigenvalues are 2 and 3. Alternatively, applying the formal approach:
We write (A - lambda I) = [[2 - lambda, 1], [0, 3 - lambda]], and then compute det(A - lambda I) = (2 - lambda)(3 - lambda). Setting this to 0 gives (2 - lambda)(3 - lambda) = 0, which yields lambda = 2 or lambda = 3.
In more complicated scenarios, we typically expand the determinant as a polynomial in lambda and solve that polynomial equation. For large matrices, numerical methods (e.g., power iteration, QR decomposition approaches) are often used in practice to approximate eigenvalues efficiently.
Below is a Python snippet showing how one might use NumPy to compute eigenvalues for a 2 x 2 matrix.
import numpy as np
# Example matrix
A = np.array([[2, 1],
[0, 3]])
# Compute eigenvalues and eigenvectors
eigenvalues, eigenvectors = np.linalg.eig(A)
print("Eigenvalues:", eigenvalues)
print("Eigenvectors:")
print(eigenvectors)
The eigenvalues output from this snippet will be [2, 3].
How do we handle repeated eigenvalues, and what implications do they have?
When the characteristic polynomial has repeated roots, it means the matrix has repeated eigenvalues. If an eigenvalue has multiplicity k, it may or may not have k linearly independent eigenvectors. A repeated eigenvalue that does not yield a full set of eigenvectors indicates that the matrix is not diagonalizable. However, even in such cases, one can represent the matrix in a Jordan Canonical form, which reveals the geometric and algebraic multiplicities of each eigenvalue. Repeated eigenvalues can lead to subtleties in numerical computations (stability issues) and interpretability, since the eigenvectors might not form a complete basis.
Can matrices have complex eigenvalues?
Yes. Any real square matrix can have either purely real or complex conjugate pair eigenvalues. Symmetric real matrices, however, have the special property of guaranteeing real eigenvalues. If the matrix is not symmetric (or not Hermitian in the complex case), its eigenvalues can appear in complex conjugate pairs. In practical applications, it is not unusual to see complex eigenvalues when dealing with rotation-dominated transformations.
What are some numerical techniques for large matrices?
When matrices are large, directly solving det(A - lambda I) = 0 by symbolic or naive methods is not efficient. Instead, iterative techniques are used:
Power iteration: Finds the largest eigenvalue in magnitude by repeatedly multiplying a random vector by the matrix, then normalizing. QR algorithm: A classic approach that uses orthogonal transformations to iteratively converge to an upper triangular form (the Schur decomposition), from which eigenvalues can be read off the diagonal. Lanczos method (for symmetric matrices) or Arnoldi method (for general matrices): Used for sparse, large matrices to get a handful of dominant eigenvalues (e.g., the top largest ones in magnitude).
What happens if a matrix is not diagonalizable?
A matrix that is not diagonalizable can be transformed into its Jordan normal form. This representation uses Jordan blocks along the diagonal, which reflect the eigenvalues and how many eigenvectors exist for each eigenvalue. Even though it can’t be made purely diagonal, the Jordan form still provides a systematic way to analyze the matrix’s spectral properties.
How do eigenvalues relate to real-world applications?
Eigenvalues appear in countless applications. Some common areas include:
Dimensionality Reduction (PCA): The directions of maximum variance in principal component analysis correspond to eigenvectors of the data covariance matrix. The eigenvalues indicate the magnitude of variance along those eigenvectors. Stability Analysis: In differential equations or dynamic systems, the signs of the real parts of the eigenvalues determine the system’s stability behavior. Spectral Clustering: Graph Laplacians’ eigenvalues can reveal clusters or connected components in network/graph data. Singular Value Decomposition (SVD): For a matrix that is not necessarily square or symmetric, SVD is a related concept where the singular values (square roots of eigenvalues of A^T A) help interpret low-rank approximations, among other use cases.
These examples demonstrate the fundamental importance of eigenvalues in both theoretical and practical aspects of linear algebra, data science, and beyond.