
ML Interview Q Series: In which cases might you choose not to apply ensemble methods for classification tasks?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Ensemble classifiers combine multiple models into one aggregate predictor. The intuition is that if models have diverse error patterns, their combined output can produce more stable and accurate results. However, there are scenarios where using an ensemble might not be advantageous:
Challenges with Very Limited Data
Ensemble methods typically train multiple base learners. If data is already scarce, splitting it further to train multiple models can lead to underfitting, as each individual learner may not have enough examples to capture the underlying data distribution. Moreover, the variance of each individual model’s estimate could increase because each learner is effectively seeing fewer samples.
Interpretability Constraints
Certain applications demand highly interpretable models, such as healthcare or legal domains where decision transparency is critical. Ensemble models (like Random Forests or Gradient Boosting) can become opaque, making it difficult to explain why a particular prediction was made. A simpler model, such as a single decision tree or logistic regression, might be preferred if interpretability is paramount.
Real-Time Inference and Computation Overheads
Ensemble methods often require multiple models to run at inference time. This can be computationally heavier than deploying a single model, especially if each base learner is large or if an intricate voting mechanism is used. For real-time systems with strict latency constraints, the overhead of running multiple models might be prohibitive. Additionally, memory constraints could be a bottleneck when each model in the ensemble is large.
Risk of Diminishing Returns
Ensembling usually boosts performance, but there can be diminishing returns if the individual models are not sufficiently diverse or if their errors are highly correlated. Training and maintaining a complex ensemble might not justify the marginal performance gains, particularly when simpler, faster, or cheaper approaches produce comparable results.
Potential Overfitting and Complexity
Although ensembles often reduce overfitting compared to a single complex model, some ensemble strategies—especially if poorly tuned—can end up overfitting. For example, overly complex boosting procedures can fit noise in the training data if hyperparameters (like the learning rate or number of boosting rounds) are not carefully optimized. In that scenario, the model might generalize poorly, undermining the benefits of ensembling.
Situations with High Cost of Maintenance
An ensemble can be complicated to maintain and update. For instance, when new data arrives, retraining multiple models can be time-consuming and computationally expensive. Some production pipelines value simplicity and shorter iteration cycles, making a single, well-regularized model more practical.
Voting Mechanism in Ensemble Classifiers
A core way that ensembles combine their individual predictions is via a voting scheme. For classification, each model h_i predicts a class, and a weighted or unweighted majority vote is used to produce the final output. A simplified weighted voting can be expressed as:
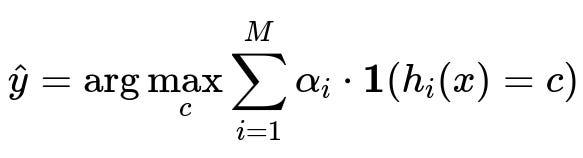
Here c represents a possible class label, M is the total number of base learners, alpha_i is the weight assigned to the i-th learner (often learned during training), h_i(x) is the predicted label for instance x by the i-th learner, and 1(...) is an indicator function that is 1 if h_i(x) equals c, and 0 otherwise.
Even though this aggregated output often improves predictive performance, the logistical or interpretational drawbacks outlined above may outweigh its benefits in certain circumstances.
Follow-up Question: How do interpretability demands affect the decision to use an ensemble?
When the application domain imposes strict explainability requirements, a highly interpretable model might be indispensable. Even though techniques like feature importance plots or model distillation (where you approximate the complex ensemble with a simpler surrogate) can provide some insight, these methods might not suffice for regulatory or user-facing settings. In such environments, it is typically safer and more effective to use simpler models like a single decision tree, linear model, or a rule-based system, because these can be easily inspected and understood.
Follow-up Question: What if we require real-time predictions but still want ensemble benefits?
One approach is to use smaller or more efficient base learners in the ensemble, such as shallow decision trees or lightweight neural networks. Techniques like model pruning or quantization can also help. Another possibility is to deploy a two-step system where a fast model operates by default, and a heavier ensemble is called only when the simpler model’s confidence is low. This way, you can meet the real-time requirement while selectively benefiting from the ensemble’s improved accuracy.
Follow-up Question: Are there ways to handle data scarcity yet still use ensembles?
Strategies like cross-validation-based ensembles or approaches such as Bootstrap Aggregation (Bagging) might help. In bagging, resampling with replacement allows each individual learner to train on different subsets of data. This can sometimes mitigate data scarcity by reusing samples. However, if data is severely limited, even bagging might not bring enough diversity to justify the overhead. Transfer learning or data augmentation could be more effective solutions in scenarios with extremely small datasets.
Follow-up Question: How do we prevent overfitting in ensemble methods?
Proper hyperparameter tuning is crucial. In boosting methods, adjusting the learning rate, the number of boosting rounds, and the depth of individual trees is key to controlling complexity. In bagging-based ensembles, limiting the depth of trees or applying constraints (like maximum number of features) can help. Early stopping is another important tactic in many boosting frameworks to stop training when validation loss starts to rise again.
Follow-up Question: Is there a scenario where a single, simpler model is strictly better?
Yes. When the dataset is simple enough or linearly separable, or when the domain needs real-time predictions on constrained hardware, or when transparency is the highest priority, a single model is often more practical. In these scenarios, the complexity of an ensemble does not provide additional meaningful benefits and can become an unnecessary operational burden.
In summary, while ensemble classifiers can significantly boost performance, they are not always the best choice. Trade-offs such as training cost, interpretability, data availability, and real-time inference constraints can make simpler approaches more appealing in certain real-world settings.