
ML Interview Q Series: In which situations is Grid Search preferred over Random Search, and vice versa, for tuning hyperparameters?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Grid Search systematically explores a predefined set of hyperparameter values by constructing a grid of possible configurations and evaluating the model performance at each grid point. By contrast, Random Search randomly samples from the hyperparameter space according to specific distributions within a given range. Both approaches aim to uncover good parameter choices, but they differ in coverage efficiency and practical suitability for certain scenarios.
Mechanics of Grid Search
Grid Search is exhaustive within the chosen parameter grid. If a hyperparameter takes on discrete values, the total number of possible combinations grows quickly as more hyperparameters and discrete values are added. The size of the parameter space can be expressed in text form as product of all chosen discrete values across parameters. For many deep learning settings, this becomes extremely large and computationally expensive.
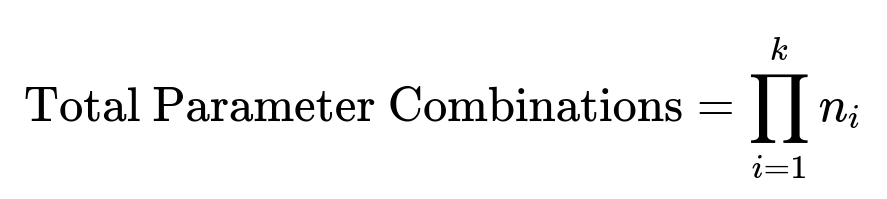
Here, k is the number of hyperparameters you are tuning, and n_i represents the count of discrete values to test for the i-th hyperparameter. If k is large or if each parameter has many possible discrete values, this product can explode in size, making Grid Search infeasible. However, when the search space is relatively small or domain knowledge suggests a precise set of values, Grid Search can thoroughly examine every possible configuration in that bounded space.
Mechanics of Random Search
Instead of exhaustively searching a predefined grid, Random Search picks parameter values by sampling from probability distributions over the ranges you specify. This approach often covers the space more effectively, especially when there are many parameters or when some parameters have a more significant impact on performance than others. By sampling stochastically, you can find strong parameter settings much more quickly in practice.
An important detail is that Random Search tends to avoid the curse of dimensionality better than Grid Search. In high-dimensional spaces, many grid points can be “wasted” in less relevant corners of the space. Random Sampling more evenly probes the space and might discover high-performing regions that a coarse grid could miss.
When to Use Grid Search
Grid Search is preferable when:
The hyperparameter space is small or low-dimensional.
You want to perform an exhaustive check of a range of discrete values.
You possess strong domain knowledge that indicates a limited set of values for each parameter.
You can afford the computational cost of evaluating every single combination.
When to Use Random Search
Random Search is beneficial when:
The hyperparameter space is large or high-dimensional.
There is limited knowledge about which hyperparameter values are most promising.
You want to quickly identify a region of strong configurations rather than evaluate all configurations.
You have constraints on computational resources or time and cannot evaluate every possible option.
Practical Example
Suppose you want to tune the learning rate and number of hidden units in a neural network:
Using Grid Search, you might specify a grid of learning rates
[0.001, 0.01, 0.1]and hidden units[64, 128, 256, 512]and evaluate each combination. This is manageable (12 total evaluations) if you have enough GPU time.For a deeper network with additional parameters like momentum, dropout rates, or batch sizes, the grid can expand to impractical proportions. In this case, you could switch to Random Search with well-chosen distributions (e.g., log-uniform for the learning rate) over a broader range to sample a certain number of trials. This often yields strong results without exhaustive search.
Additional Insights
The choice between the two methods also depends on how you handle parallelization. Parallelization can speed up Grid Search if you can evaluate multiple points of the grid simultaneously. However, Random Search is also parallelizable: each random sample can be a separate process or job. Therefore, if parallel resources are abundant, you could explore either method more aggressively.
Both Grid Search and Random Search can be further enhanced or replaced by more sophisticated approaches like Bayesian Optimization, which adaptively guides the search based on previous results. In modern practice, Bayesian Optimization or Tree-structured Parzen Estimators (TPE) are quite popular, especially when function evaluations (model training runs) are expensive.
Potential Follow-Up Questions
How do you decide the discrete values for the hyperparameters in a Grid Search?
In a Grid Search, you must pick a small set of values for each hyperparameter to keep the total combination count manageable. Usually, these choices are influenced by domain knowledge or preliminary experiments. For learning rates, for example, you might pick exponential steps (like 0.001, 0.01, 0.1) because learning rates often span orders of magnitude. For other parameters like number of hidden units, you might space them in powers of two (e.g., 64, 128, 256) to reduce the search space and stay consistent with typical neural network architectures.
If you select too many values per parameter, you risk an explosion in the total number of combinations. If you pick too few values, you might miss optimal points in the parameter space. Balancing these considerations is key to effective Grid Search.
In high-dimensional spaces, how would you justify switching to Random Search?
When dealing with high-dimensional parameter spaces, Grid Search often becomes infeasible because it requires evaluating every combination in a massive grid. The dimensionality makes it likely that many grid points do not meaningfully sample the space. Random Search mitigates this by distributing trials more flexibly. Over many random draws, you can explore different parts of the space with fewer wasted evaluations. Empirical studies suggest that Random Search often finds comparably good or better solutions in fewer evaluations.
How do you incorporate prior knowledge about parameter importance into Random Search?
When you suspect certain parameters are more influential than others, you can sample them more finely or with different distributions. For instance, if the learning rate is known to be critical, you might use a log-uniform distribution with narrower bounds to more thoroughly explore that dimension. Meanwhile, other parameters might be sampled uniformly over a broader range but with fewer total trials. This way, you allocate more search effort to the most impactful hyperparameters.
Could you provide a short code snippet showing how to implement Grid Search and Random Search in Python?
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
from scipy.stats import randint
# Example dataset
X_train = ...
y_train = ...
# Define a model
model = RandomForestClassifier()
# Grid Search setup
grid_params = {
'n_estimators': [50, 100],
'max_depth': [5, 10, None]
}
grid_search = GridSearchCV(estimator=model, param_grid=grid_params, cv=3)
grid_search.fit(X_train, y_train)
print("Best parameters (Grid Search):", grid_search.best_params_)
# Random Search setup
random_params = {
'n_estimators': randint(50, 200),
'max_depth': randint(1, 20)
}
random_search = RandomizedSearchCV(estimator=model,
param_distributions=random_params,
n_iter=10,
cv=3,
random_state=42)
random_search.fit(X_train, y_train)
print("Best parameters (Random Search):", random_search.best_params_)
In this example, GridSearchCV exhaustively checks all combinations in grid_params, while RandomizedSearchCV draws random samples for each parameter from the specified distributions in random_params. This approach highlights how Grid Search is methodical but can become computationally heavy, whereas Random Search quickly explores different areas of the parameter space.
Why might you consider Bayesian Optimization or other advanced methods over Grid or Random Search?
Bayesian Optimization and related methods exploit information gleaned from past hyperparameter evaluations to build a probabilistic model of the objective function (e.g., validation accuracy). Then they use an acquisition function to select the next promising point to evaluate. This adaptive strategy can be much more sample-efficient than blindly searching grid points or sampling randomly. It is especially beneficial when each model training run is very expensive, such as large-scale neural network training. However, Bayesian methods have their own complexity, requiring careful setup and higher compute overhead per iteration.
What if you still want exhaustive coverage but have limited computational resources?
You might reduce the dimensionality of the grid, using a coarse set of values for less influential hyperparameters and a more detailed set for the most crucial parameters. Alternatively, you could consider a two-stage approach. First, run a Random Search or coarse Grid Search to narrow down regions of interest. Then, apply a more fine-grained search (Grid Search or Bayesian Optimization) within that region. This hybrid method can help balance coverage with computational feasibility.