
ML Interview Q Series: Independence of Linear Combinations of Bivariate Normals via Zero Covariance

Browse all the Probability Interview Questions here.
Let the random vector (X, Y) have a standard bivariate normal distribution with correlation coefficient rho = -0.5. For which values of a are the random variables V = aX + Y and W = X + aY independent?
Short Compact solution
The covariance of V and W is -0.5 a^2 + 2 a - 0.5. Setting this to 0 and solving yields a = 2 + sqrt(3) or a = 2 - sqrt(3). Hence, V and W are independent for these two values of a.
Comprehensive Explanation
Covariance and Independence
Because V and W are linear combinations of a bivariate normal random vector, independence is equivalent to having zero covariance (for jointly normal variables, zero correlation/covariance implies independence). Specifically, let:
V = aX + Y
W = X + aY
We compute cov(V, W). Since X and Y have mean 0, variance 1, and correlation coefficient rho = -0.5 (which means cov(X, Y) = -0.5), we can expand cov(V, W) as:
cov(V, W) = cov(aX + Y, X + aY).
Using bilinearity of covariance: cov(aX + Y, X + aY) = a * cov(X, X) + a * cov(Y, Y) + cov(aX, aY) + cov(Y, X).
But let’s be systematic:
cov(aX, X) = a * cov(X, X) = a * 1 = a
cov(aX, aY) = a * a * cov(X, Y) = a^2 * (-0.5) = -0.5 a^2
cov(Y, X) = -0.5 (by the correlation assumption)
cov(Y, aY) = a * cov(Y, Y) = a * 1 = a
Combine them carefully:
From (1) and (4): a + a = 2a
From (2): -0.5 a^2
From (3): -0.5
So the sum is 2a - 0.5 a^2 - 0.5. Hence,
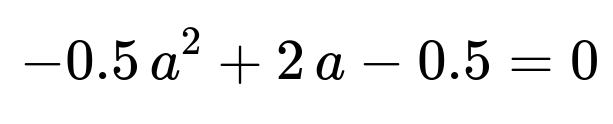
This quadratic equation in a has the two roots:
a = 2 + sqrt(3) and a = 2 - sqrt(3).
Since for a bivariate normal distribution, zero covariance is both necessary and sufficient for independence, these are exactly the values of a that make V and W independent.
Interpreting the Result
Meaning of a: The coefficient a changes how strongly X or Y is weighted in V and W. When a = 2 +/- sqrt(3), the “mix” of X and Y in V versus W is such that the correlation disappears.
Uniqueness: Because for bivariate normals zero correlation means independence, these solutions (2 +/- sqrt(3)) are the only possible values ensuring independence.
Potential Follow-Up Questions
1) Why does zero covariance imply independence here, whereas in general it does not?
In general distributions, zero covariance (or correlation) does not necessarily imply independence. However, if (X, Y) follows a jointly normal (Gaussian) distribution, then any linear combination of X and Y is also normally distributed. For jointly normal variables, zero covariance is not just a measure of linear relationship; it is a sufficient condition for independence. Hence, once cov(V, W) = 0, V and W must be independent.
2) What if the correlation rho were different from -0.5?
If rho were some other value, say r, the covariance formula would become a bit different. Specifically, cov(X, Y) = r. Then the expression for cov(V, W) would be:
a * var(X) + a * var(Y) + a^2 cov(X, Y) + cov(Y, X).
Since var(X) = var(Y) = 1 and cov(X, Y) = r, it becomes:
cov(V, W) = a + a + a^2 r + r = 2a + r(a^2 + 1).
You would set that equal to zero and solve for a in terms of r. For r = -0.5, it matches the specific equation we solved.
3) Could there be any hidden assumptions about X and Y that might affect the result?
The main assumptions are that X and Y are jointly normal, mean 0, variance 1, and correlation -0.5. If they were not jointly normal, then zero covariance between V and W would not necessarily guarantee independence. Also, the direct derivation that cov(V, W) = 0 implies V and W are independent holds specifically under the jointly normal assumption.
4) How do we solve the quadratic equation efficiently by hand or code?
The equation -0.5 a^2 + 2 a - 0.5 = 0 can be multiplied by -2 to get rid of the decimal coefficients:
a^2 - 4 a + 1 = 0.
Then you can apply the quadratic formula a = [4 +/- sqrt(16 - 4)] / 2 = [4 +/- sqrt(12)] / 2 = 2 +/- sqrt(3). Equivalently, one can solve -0.5 a^2 + 2 a - 0.5 = 0 directly using the standard formula. In Python, you might do:
import math
A = -0.5
B = 2
C = -0.5
discriminant = B*B - 4*A*C
a1 = (-B + math.sqrt(discriminant)) / (2*A)
a2 = (-B - math.sqrt(discriminant)) / (2*A)
print(a1, a2)
You would get the numerical values 2 + sqrt(3) and 2 - sqrt(3).
5) In practical machine learning scenarios, how would you implement a check for independence?
Analytical approach: If you know the data generation process is Gaussian and you have explicit formulas for covariance, you would do exactly what we did: compute cov(V, W) and check if it is zero.
Empirical approach: Estimate the sample covariance from data. If the sample covariance is near zero, check if the data is approximately jointly normal. If it appears so, that near-zero sample covariance suggests approximate independence. However, if the data is not normal, a more robust measure (like mutual information) might be necessary to ensure independence.
All of these considerations underscore that the key property here is that (X, Y) is bivariate normal. Once that is established, checking for independence of linear combinations reduces to checking for zero covariance.
Below are additional follow-up questions
In what situations might the quadratic equation give complex roots, and how would that affect our interpretation of independence?
If the correlation between X and Y were set up in a way that the resulting coefficients in the covariance equation lead to a negative discriminant in the quadratic formula, the solutions for a would become complex. For instance, if we had a correlation value that is too large in magnitude or a mismatch in variances, the expression for cov(V, W) = 0 could yield no real solutions. This implies that there would be no real value of a for which V and W could be independent.
In a practical sense, if you ever see a complex root in this context, it flags that you either have made a mistake in your assumptions (for example, the correlation or the variance is incorrectly specified), or that it is simply not possible for V and W to be uncorrelated real-valued random variables under the given conditions.
A subtle pitfall in real data: sometimes estimates of correlation from small samples can be inaccurate, causing you to solve a “no real solution” scenario when, in fact, the true correlation might have allowed real solutions. Hence, careful statistical testing and confidence intervals around your estimated correlation can help you detect whether it is plausible for real solutions to exist.
What happens if X or Y is not centered at zero? How would that alter our expressions for independence?
When X and Y are not zero-mean but still jointly normal, the covariance formula among linear combinations still holds for the centered versions of X and Y. However, to apply the same neat equation cov(V, W) = 0, you must carefully subtract the means first. If X and Y have nonzero means, say E(X) = mu_X and E(Y) = mu_Y, then:
V = a(X - mu_X) + (Y - mu_Y) and W = (X - mu_X) + a(Y - mu_Y)
would be the proper centering for analyzing covariance. You could equivalently expand V and W with the raw values of X and Y, but you would need to incorporate terms that come from E(X) and E(Y).
A real-world subtlety: data often comes with nonzero means, and forgetting to center the variables can lead to incorrect covariance estimates. This might lead you to believe there is no solution for independence when in fact the variables just needed a proper shift to mean zero.
How does the presence of additional dimensions or variables affect the independence of V and W?
In higher-dimensional Gaussian settings, X and Y might just be two coordinates out of many. Here, we focus on a 2D slice with correlation rho, but in reality, X and Y could be marginal distributions of a larger multivariate normal. The independence of V and W still boils down to whether their covariance is zero if the entire joint distribution remains Gaussian.
However, a pitfall arises if the larger joint distribution is not strictly multivariate normal or if X and Y are conditional Gaussians with certain constraints. Independence in a sub-block of variables does not guarantee independence in the full space. Also, if we incorporate more variables and start forming new combinations, the parameter a for which independence holds might change or might not exist at all for certain subcombinations.
In practical data science problems, we often face more than two variables. Ensuring that any pair of transformed variables is independent usually requires considering the entire covariance matrix and the transformations performed on each dimension.
Could nonlinearity in the transformations of X and Y affect the independence of V and W?
Yes. The derivation we use hinges on V and W being linear combinations of jointly normal variables. If we introduced a nonlinear transformation—like V = aX + Y^2—then even if X and Y themselves are jointly normal, V and W would no longer follow a joint bivariate normal distribution in general. Zero covariance would not be sufficient to declare independence.
In real-world applications, variables frequently interact in nonlinear ways. If the transformations used to define V and W are nonlinear, the independence test by setting cov(V, W) = 0 becomes insufficient. One must resort to more general methods of testing independence (for example, checking mutual information or using specialized dependence measures). A common pitfall is to assume linear independence tests remain valid under strong nonlinearities, which can mislead the analysis.
What if the correlation coefficient rho changes sign during an iterative estimation procedure?
In iterative algorithms, such as expectation-maximization or gradient-based optimizations, correlation estimates can fluctuate around positive and negative values before converging. If rho changes sign, it might momentarily create or destroy the condition for real solutions for a. This can happen, for example, when data is sparse or the model is not identified well.
A practical pitfall: if you are dynamically solving for a in each iteration based on an estimated correlation, you could encounter oscillations or even diverge if the correlation swings. Convergence issues might arise if you repeatedly solve a = 2 ± sqrt(3) for a correlation that is drifting. Proper initialization, regularization, or constraints on the parameter space can help.
How does measurement error or noise in X and Y influence the determination of a for independence?
Real data often includes noise beyond the idealized bivariate normal assumption. This extra noise can make your estimates of mean, variance, and correlation for X and Y less stable. As a result, the computed covariance of V and W might not be exactly zero at a = 2 ± sqrt(3) in practice; indeed, it might not even be close to zero if the data is noisy enough.
A subtle issue is that even small biases in measuring X or Y can significantly shift the estimated correlation. When you substitute those estimates into the formula for a, you may get an inaccurate solution. You might interpret your results incorrectly and conclude V and W are independent when they are not, or vice versa.
If measurement error is suspected to be large, you should incorporate it explicitly into your model—possibly using error-in-variables regression or Bayesian methods—to get a more robust handle on the relationship between V and W.
Do finite sample sizes in an empirical study affect how we determine independence?
Yes. In practice, you rarely have infinite data. Even if X and Y come from a bivariate normal distribution with rho = -0.5, a finite sample estimate of correlation might deviate from -0.5, sometimes drastically for small samples. Consequently, the estimated solutions for a could differ from 2 ± sqrt(3).
A subtlety is that if your sample correlation is, say, r_hat, your “best” guess for a to make V and W uncorrelated is based on solving the analogous equation but with r_hat. If r_hat is sufficiently far off from the true value, you may get an a estimate that yields non-independence in reality. Statistical inference and confidence intervals around r_hat can provide insight into how stable that estimate is. In small-sample regimes, those intervals can be quite large, indicating considerable uncertainty.
What if we impose additional constraints such as nonnegativity or integer values for a?
Sometimes in engineering or discrete modeling contexts, the parameter a might be restricted—such as a >= 0 or a being an integer. In that scenario, the “freely computed” solutions 2 ± sqrt(3) might lie outside the permissible domain for a. This means there is no feasible a that satisfies the independence condition.
Alternatively, if you are forced to pick the integer nearest to (2 ± sqrt(3)), then the resulting V and W will only be approximately uncorrelated, not exactly so. The more restricted your parameter space is, the less likely you can achieve exact independence through a simple linear combination. In actual deployments, you might have to compromise: pick the best feasible a that minimizes the absolute covariance, acknowledging that perfect independence is unattainable.
Could heteroskedasticity in the data violate the standard bivariate normal assumptions?
Heteroskedasticity typically refers to the case where the variance of a random variable is not constant across observations or subpopulations (often seen in regression contexts). Strictly speaking, if X and Y are truly standard bivariate normal, their variances are fixed parameters and do not vary across observations. However, in real-world data, the variance of X or Y could depend on time or some latent factor.
This undermines the assumption of identical variance for all observations. If the data is heteroskedastic, the true distribution might deviate from bivariate normality, making the zero-covariance-implies-independence argument invalid. A practical subtlety is that you might see an apparent correlation structure that is actually driven by changing variance over time. Standard correlation estimates can then be misleading. You may want to model the data using generalized least squares or a time-varying covariance approach instead.