
ML Interview Q Series: Is 10,000 delivery records from a Singapore beta test sufficient to build an accurate ETA model?

📚 Browse the full ML Interview series here.
Short Compact solution
Since “how accurate is accurate enough” is subjective, it is critical to clarify expectations around the ETA model’s required precision. Once you understand the goal, you can start by creating a baseline model trained on the 10,000 beta-test deliveries and measure its performance using metrics such as RMSE or MAE. This baseline tells you whether 10,000 observations are adequate or if you might need additional data to improve accuracy. If the performance is not sufficient, investigate whether to gather more data, add or refine features (e.g., traffic patterns, supply-demand signals, distance to the restaurant), or simplify the model so it can learn effectively from limited samples. You can then use learning curves to see how additional data influences your metrics. If you discover that model improvements plateau long before you exhaust your data, the issue might lie in feature quality or model complexity. Ultimately, decide if more data acquisition or new features is cost-effective relative to the business impact of more precise ETAs.
Comprehensive Explanation
Clarifying “good enough” ETA accuracy is the first critical step. Different parts of the system might demand different precision levels. For instance, when matching orders to drivers, the platform may require highly accurate timing estimates to minimize driver idle time, while the ETA displayed to customers can tolerate some slack as long as it does not frustrate or mislead them.
After clarifying the desired accuracy, a sensible approach is to construct a baseline model using the available 10,000 beta records. A simple example is a regression that depends on average preparation time at each restaurant and the driving time based on distance. You can evaluate its performance using metrics suitable for continuous predictions. Common metrics include:
Root Mean Squared Error (RMSE)
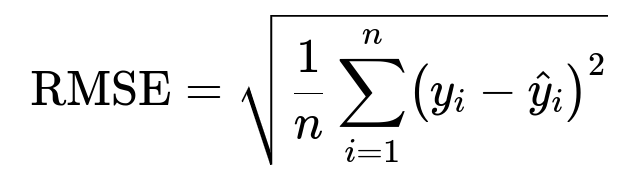

and the coefficient of determination (R-squared), which measures the proportion of variance explained by your model. Once you have the baseline results, you can judge whether 10,000 examples yield enough accuracy for the intended business use.
Learning curves are a valuable way to investigate the relationship between model performance and the quantity of training data. By training on progressively larger subsets of data—say 25%, 50%, 75%, and so on—you can observe how the performance metric changes. If the performance grows substantially with more data and does not plateau, it indicates that collecting or synthesizing additional data is likely beneficial. Conversely, if the model’s accuracy levels off, you might be facing issues related to feature selection, data quality, or model complexity rather than just data volume.
If you find your model remains unsatisfactory, there are several options. You could incorporate new features that better capture relevant signals (for instance, real-time traffic data, supply-demand ratios in the area, or restaurant-specific time-of-day variations). You might switch to simpler or more regularized algorithms that do not require large datasets, or consider dimension reduction if you have too many features relative to your data size. From a business standpoint, also ask whether an imperfect ETA model actually hinders the launch or if it is an issue that can be improved post-launch as more data is collected in production.
Potential Follow-Up Questions
How do you know if 10,000 data points truly suffice?
Look at learning curves and out-of-sample metrics. If your performance is still improving steadily when using all 10,000 data points, it suggests you might gain accuracy by gathering more examples. If performance levels off long before you reach 10,000, you have indications that data volume is not the bottleneck, and it might be more about feature engineering or model selection. You can also consider cross-validation to ensure you are getting a reliable estimate of model performance from the available data.
Why might you use R-squared, and are there other metrics to consider?
R-squared is intuitive because it expresses how much of the variance in the target is captured by your predictions. However, R-squared can sometimes misrepresent model performance if the target distribution is skewed or if there are many outliers. For delivery-time predictions, metrics like MAE or RMSE often map more directly to the real impact on the end user. You could also consider percentile-based metrics, such as checking whether 90% of the predictions fall within a certain threshold from the actual times.
If 10,000 deliveries come from a single city or region, how can you generalize to broader scenarios?
You could transfer knowledge from other markets or regions if you have robust data from places with similar traffic patterns, restaurant density, and consumer behavior. Another possibility is to use domain adaptation methods, or to incorporate external data sources like weather or traffic to reduce overfitting to one city. You can also attempt hierarchical modeling that partially pools parameters across different areas, letting you share statistical strength but still adapt to local differences.
What if new restaurants and new neighborhoods do not appear in your training data?
This is a “cold start” problem. You might build a feature-based approach that relies on generalizable factors such as geographic location, time of day, day of week, typical prep times for similar restaurant categories, or road traffic data. You might also adopt a collaborative filtering approach among restaurants with similar cuisine or average price range. Another strategy is to initialize new entries with population-level averages until enough data accumulates for that specific location or restaurant.
How do you decide when to invest in gathering more data rather than tuning the model further?
You can weigh the cost of collecting or purchasing additional data against the measurable improvements in your model’s performance. If the learning curve suggests you have not reached an asymptote and each data increment meaningfully reduces error, acquiring more data is attractive. But if you see diminishing returns, it may be more prudent to refine features, try more suitable architectures, or incorporate domain knowledge.
How would you practically add more features for the DoorDash ETA prediction?
You can integrate real-time factors such as traffic congestion, expected preparation times for each restaurant at different hours, driver availability in the vicinity, and historical data on how many orders a restaurant handles concurrently. You can also factor in unexpected events (such as weather or local holidays) and see how they correlate with average delays. Automating data pipelines to collect and preprocess these additional signals can be essential for continuously improving the model’s forecasts.
Could you leverage data from other countries or cities where DoorDash operates?
If the underlying drivers of delivery time are similar (traffic, restaurant behavior, driver behavior), you can transfer or adapt models trained on other regions. However, watch out for differences in road infrastructure, local traffic habits, restaurant density, or cultural norms about ordering times. Domain adaptation techniques and region-specific fine-tuning can help calibrate an existing model to local conditions.
How often would you retrain the model and update your ETA predictions?
Retraining frequency depends on how quickly data distributions shift. If you see that the average delivery time or traffic patterns are changing over weeks or months, retraining on new data may be essential. Setting up an automated or semi-automated system that monitors model drift and triggers retraining once performance degrades is a common approach. A real-time or near-real-time update system may be required in fast-changing environments, though that increases engineering complexity and costs.
What are the risks of over-engineering features with only 10,000 data points?
Overfitting is more likely when you have many features but limited data. Your model might appear very accurate on training data but fail on unseen scenarios. Dimensionality reduction or careful feature selection can mitigate this. Another strategy is to start with a simple model that covers the most influential factors and only expand feature complexity once you have validated that each new feature gives a meaningful improvement and you have enough data to support it.
How would you handle large outliers, such as extremely delayed deliveries?
Outliers can bias average-based metrics and complicate model fitting. To address them, you might use robust regression techniques or transform the target variable (for instance, taking a logarithm of the delivery time if appropriate). You can also isolate outliers if they stem from anomalies, such as driver accidents or restaurants temporarily closing, and decide whether to keep or remove them based on the business need to predict such events accurately.
Below are additional follow-up questions
How do you handle real-time updates to ETAs once the order is in progress?
One possible approach is to build a streaming component that re-evaluates the ETA as the driver progresses through each step of the delivery workflow. For instance, if the driver is still waiting at the restaurant and order preparation is delayed, you can dynamically update the ETA. This requires continuous data feeds, such as driver GPS locations and restaurant readiness signals, so that any new information is quickly factored into the existing model. A practical pitfall is ensuring that updates remain stable enough not to confuse users with ETAs that jump around unpredictably. A subtle real-world issue might be the trade-off between responsiveness (reflecting actual conditions as soon as they change) versus a stable, user-friendly interface. If ETAs fluctuate significantly, users may lose trust. One strategy is to introduce controlled smoothing or short-term rolling averages so that ETA changes feel more gradual.
How do you address potential biases in the data collection process?
Bias can arise in multiple ways. Suppose certain neighborhoods or restaurant categories had fewer orders during beta testing, leading to underrepresented data in those areas. This can cause the model to be less accurate for those subsets of deliveries. Another subtle bias might emerge if courier availability varies dramatically among different regions or times of day, and that variation is not captured uniformly in the training data. Handling bias involves collecting more balanced data samples if possible, or applying methods such as sample re-weighting or stratified sampling to ensure fair representation across different segments. You could also analyze how your model’s error metrics differ by location, daypart, cuisine type, or demographic factors if that data is relevant. A major pitfall is ignoring these biases and inadvertently deploying a model that performs poorly for certain customers, thereby affecting satisfaction and trust.
How do you deal with an imbalanced temporal distribution of deliveries (e.g., most orders at peak times)?
Real-world data often clusters around lunch and dinner rush hours, leaving certain off-peak times with fewer samples. Models can struggle to generalize to these less-common scenarios. A thorough approach might involve segmenting data by time-of-day or day-of-week, then using these segments to build either separate models or to enrich a single model’s feature set. Another angle is to up-sample off-peak data or down-sample peak data to achieve a more balanced distribution during training. The key pitfall is overfitting to your busiest times and failing to capture the nuances of off-peak situations. You must also be watchful about how you validate the model: a random split might overly favor the majority scenario (peak hours) unless you do a stratified split or time-based split that respects these temporal differences.
When should you incorporate external data sources like weather or local events, and how do you maintain these features over time?
Weather, local events, and even holiday schedules can significantly affect traffic and restaurant operations. A model might greatly benefit from features such as precipitation levels, public holiday flags, or presence of large-scale sporting events. However, pulling in these datasets introduces engineering complexity. You must ensure data reliability: if your weather API or event calendar feed is missing data on a given day, your model might produce skewed or incomplete results. Maintaining these features means having robust pipelines for ingesting, cleaning, and aligning external data with your delivery logs. An edge case might be local street closures due to construction or parades, which are irregular and require specialized data sources. If you cannot guarantee consistency or timeliness, it might be more harmful than helpful to include them.
How do you calibrate the model if it systematically underestimates or overestimates ETAs?
Calibration involves ensuring that your model’s predictions correspond well to actual observed times. For instance, if your model constantly predicts deliveries to arrive five minutes earlier than they do, you could apply a post-processing shift to correct for that systematic bias. A more nuanced method is to use calibration curves or isotonic regression to map raw model predictions to a better-aligned output. A subtle pitfall is relying solely on average errors; if the model’s performance is uneven across different segments—such as certain zip codes or restaurant categories—global calibration may not be enough. You might need segmented calibration that adjusts predictions differently depending on the context. Additionally, calibrating can become cyclical: once you correct the bias, the underlying distribution of residuals may shift again, which means you must monitor the calibration process over time.
How can you address seasonal or sporadic events that cause abrupt distribution changes?
Seasonal shifts, such as a spike in orders during major holidays or a temporary surge in traffic during large conferences, can break a model trained on typical conditions. You can handle this by building models that explicitly include seasonal indicators or by training separate models specialized for certain periods (e.g., a holiday model versus a non-holiday model). Another approach is using online learning or incremental learning algorithms that update as new data flows in, allowing them to adapt to changing conditions. A tricky real-world complication is data lag: you might only realize a big event has caused a shift after it starts happening, and the model may not have enough time to adapt. One possible mitigation is to incorporate external signals that predict these events well in advance (like major holiday schedules or large stadium bookings).
How do you detect and mitigate performance degradation over time?
Performance drift can occur because of changing traffic patterns, new driver behaviors, or restaurant expansions. One common strategy is to set up real-time or periodic monitoring of key metrics like RMSE, MAE, or coverage on different segments. If you detect a significant spike in errors, you can trigger retraining, a more detailed error analysis, or a revert to a previous model version. Maintaining logs of prediction errors is essential for root-cause analysis. A subtle pitfall is not monitoring the performance on all segments. If you only track aggregate performance, you may miss localized degradation in certain areas or certain restaurants. Another subtlety is deciding the threshold for retraining. Retraining too frequently can introduce noise, while waiting too long can erode user trust if predictions become noticeably off.
How might you implement ensemble or multi-model strategies for ETA predictions?
Ensemble methods often boost predictive accuracy by combining multiple models that each capture different aspects of the data. For instance, one model might be a time-series forecaster specialized for short-term traffic conditions, while another might be a general regression capturing restaurant prep times. You can then combine or average their predictions. One challenge is that ensembles can be more resource-intensive for inference, potentially affecting response times on a real-time application. If computing power or low latency is a concern, you could consider lightweight ensemble methods (like blending or stacking with smaller base models). Another pitfall is making sure the models are not overly similar, which reduces the benefit you get from combining them.
How do you cope if your ground-truth data on arrival times has missing or inaccurate timestamps?
Real-world logs can be messy. Drivers might forget to mark an order as “delivered,” or the system might log the restaurant handoff time instead of the actual arrival time at the customer’s door. Missing or inaccurate labels can severely impact regression performance. You can attempt data cleaning: for example, if the “delivered” timestamp is missing, you might approximate it using GPS data or user confirmation times. Another approach is to discard or down-weight uncertain examples if you have enough data, but that risks losing valuable information. Edge cases include partial coverage for delivery steps, leading to inconsistent definitions of “arrival time.” Clarifying business rules on how arrival times are logged, as well as continuously auditing the data pipeline, is key to ensuring label integrity.
How can simulation or synthetic data generation help with rarely observed scenarios?
Certain traffic conditions, extreme weather events, or highly unusual restaurant delays may be so infrequent that your model sees too few samples for generalization. Simulation can fill in these gaps by artificially creating data under hypothetical or extreme conditions, guided by domain knowledge. For instance, you might simulate a scenario where roads have limited throughput or where a driver is delayed by an unexpected detour. This can help the model learn how to handle tail events. A crucial pitfall is that synthetic data might not perfectly reflect real-world correlations. If your simulation is too simplistic, the model might learn patterns that do not translate back to reality. Thorough validation against real, albeit sparse, examples of these events is essential before you rely on simulation-augmented training data.