
ML Interview Q Series: Is it possible to utilize autoencoders for creating features? If so, how can this be achieved?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Autoencoders are specialized neural architectures designed to learn a compressed representation of the input data (often referred to as the latent space or bottleneck) by minimizing the discrepancy between the original input and its reconstructed output. They prove beneficial for feature generation because the latent representation extracted from their bottleneck layer captures essential, discriminative characteristics of the input.
Autoencoders operate by coupling an encoder and a decoder network. The encoder transforms the input data into a lower-dimensional representation. The decoder then attempts to reconstruct the input from that representation. During training, the network updates its parameters to minimize reconstruction error.
Below is the central objective for a typical autoencoder. For each input x, the network outputs x-hat, and we minimize the difference between x and x-hat.
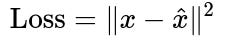
Here x represents the original input (for instance, a vector of dimension d), and x-hat represents the reconstructed input produced by the decoder. The double vertical bars indicate the squared norm. Minimizing this measure encourages the autoencoder to find a latent representation that captures the most informative aspects of x.
The encoder part of the autoencoder creates the features that can be further employed in other tasks, such as classification, clustering, or anomaly detection. After training, one can discard the decoder and use the encoder’s output (the bottleneck representation) as a distilled feature vector.
Why This Latent Representation is Useful
In many real-world applications, raw data can be high-dimensional and contain redundant or noisy information. By constraining the neural network to compress the data into a lower-dimensional vector, autoencoders are incentivized to discard less relevant noise and retain only the core patterns. As a result, the bottleneck layer naturally becomes a feature extractor.
This is particularly valuable because it can enhance performance in downstream tasks. For example, a classifier that operates on these compressed features typically requires fewer parameters and often generalizes better than a classifier trained directly on the raw high-dimensional input.
Practical Steps to Use Autoencoders for Feature Generation
One commonly used approach is:
Train an autoencoder on your dataset in an unsupervised fashion by minimizing the reconstruction error. Once training is complete, retain the encoder portion of the network as a feature extractor. For any new sample, pass it through the encoder to obtain the compressed latent representation. Use that latent representation in various downstream tasks, such as feeding these features into a supervised learning model (e.g., a simple feed-forward classifier, random forest, SVM, or other methods).
Below is a minimal Python code snippet using PyTorch to illustrate how one might define and train a simple autoencoder, then extract features from the encoder.
import torch
import torch.nn as nn
import torch.optim as optim
# Example Encoder
class Encoder(nn.Module):
def __init__(self, input_dim=784, hidden_dim=64, latent_dim=32):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
# Example Decoder
class Decoder(nn.Module):
def __init__(self, latent_dim=32, hidden_dim=64, output_dim=784):
super(Decoder, self).__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
# Full Autoencoder
class Autoencoder(nn.Module):
def __init__(self, input_dim=784, hidden_dim=64, latent_dim=32):
super(Autoencoder, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def forward(self, x):
z = self.encoder(x)
x_recon = self.decoder(z)
return x_recon
# Instantiate and train
autoencoder = Autoencoder()
criterion = nn.MSELoss()
optimizer = optim.Adam(autoencoder.parameters(), lr=1e-3)
# Suppose X is your input batch
# X would be shape [batch_size, input_dim] for a fully connected layer
# For demonstration, create dummy data
X = torch.randn(64, 784) # e.g. 64 samples of flattened 28x28 images
for epoch in range(10): # small number of epochs for illustration
optimizer.zero_grad()
X_recon = autoencoder(X)
loss = criterion(X_recon, X)
loss.backward()
optimizer.step()
# Extract features from the trained encoder
with torch.no_grad():
# Suppose test_data is some new data
test_data = torch.randn(16, 784)
features = autoencoder.encoder(test_data)
# 'features' can be used for downstream tasks
In this approach, once the network converges (or at least demonstrates good reconstruction on validation data), the encoder network alone can be preserved for producing feature vectors. These feature vectors (of dimension latent_dim) can then be utilized in classification or regression models.
Edge Cases and Considerations
Choosing the Dimensionality of Latent Space Selecting the size of the latent space is non-trivial. If it’s too large, the autoencoder might memorize noise rather than focus on genuinely useful features. If it’s too small, critical details may be lost, diminishing downstream task performance.
Risk of Overfitting Autoencoders can learn to merely copy the input if the bottleneck is insufficiently narrow or if the network architecture is excessively overparameterized. Regularization techniques, such as denoising (where random noise is added to the input and the autoencoder is asked to reconstruct the clean version), or sparse autoencoders (where an additional penalty encourages sparsity in the hidden units), can help mitigate this risk.
Data Requirements Like most deep learning methods, autoencoders require substantial data for effective training. Insufficient data might lead to poor-quality features that do not generalize.
Network Architecture Choice Various autoencoder variants exist, such as Convolutional Autoencoders for image data, Recurrent Autoencoders for sequential data, or Variational Autoencoders (VAE) for learning a continuous latent distribution. The nature of the data guides the choice of architecture.
How Autoencoder-Generated Features Are Used in Practice
In real-world pipelines, feature extraction using autoencoders is often part of a multi-stage process. For example:
Pretrain an autoencoder on unlabeled data, thereby learning representations that capture the domain’s inherent structure. When labeled samples are scarce, these representations can be especially valuable. Feed the learned representations into a classifier or clustering algorithm. Because the data is compressed into a more discriminative subspace, it may improve performance, reduce overfitting, and lead to more robust models.
Additional Follow-up Questions
How do we evaluate whether the autoencoder-generated features are truly beneficial for downstream tasks?
One can take these learned features and feed them into a validation pipeline for tasks such as classification or regression. Compare the performance (e.g., accuracy, F1 score, RMSE) against baselines that use raw input features or other dimensionality reduction approaches. If the autoencoder-based features outperform alternative methods, that is solid evidence they are beneficial.
Do autoencoders only work well with numeric data, or can they handle other data types such as text?
They can handle various data modalities as long as the input is transformable into a suitable numeric form. For instance, autoencoders have proven useful in natural language processing tasks when combined with embeddings for textual data. Recurrent or transformer-based layers are often employed for sequence modeling. For purely categorical data, one might embed the categories into continuous vectors and then apply an autoencoder-like approach.
Can autoencoder-generated features help reduce data dimensionality in a more interpretable way compared to other methods like PCA?
Autoencoders can capture nonlinear relationships that linear methods like PCA might miss. However, interpretability is not always straightforward. The latent dimensions in an autoencoder do not inherently correspond to meaningful human-understandable concepts. If interpretability is essential, techniques like variational autoencoders that encourage disentangled latent representations, or additional constraints that align features with certain domain factors, might provide better interpretability.
Is it possible for the autoencoder to ignore crucial features of the data during compression?
Yes, especially if the network configuration or training setup is poorly chosen. For instance, if the latent layer is too narrow or if there is an imbalance in the training distribution, the network might disregard minority features. Monitoring reconstruction error across different subgroups and adjusting training strategies can help address this issue.
How might we improve generalization if the autoencoder overfits to our training data?
Several approaches can reduce overfitting:
Use denoising autoencoders, where noise is added to the input and the autoencoder is trained to reconstruct the clean version. This makes the model more robust to perturbations. Incorporate regularization (e.g., weight decay, dropout) in the encoder/decoder layers. Employ a more modest latent dimension so that the network is forced to learn only the most salient features. Provide additional data augmentation techniques, ensuring the autoencoder sees varied samples.
These practices usually strengthen the learned representations, making them more transferable and robust for downstream tasks.
Below are additional follow-up questions
What if your data distribution changes significantly over time? Can you still rely on the autoencoder’s learned features?
When the distribution shifts (often termed dataset drift), the features learned by the autoencoder might no longer capture the new patterns effectively. Since autoencoders learn to minimize reconstruction error over the training distribution, a significant shift in the underlying data distribution could lead to poor reconstruction for newly observed data. Consequently, the latent representations might not align with the new structure of the data.
This mismatch can manifest in several ways. If there is a gradual drift, performance may degrade slowly over time, which can be monitored by tracking reconstruction error on recent samples. If there is a sudden shift (e.g., a complete change in data-collection protocols), the autoencoder might fail dramatically because it is encoding features relevant to a previous version of the data.
One possible remedy is to periodically retrain or fine-tune the autoencoder with newly collected data so that it can adapt to changing patterns. Another approach is to maintain a buffer of recent samples and employ incremental or online learning strategies, allowing the autoencoder to incorporate new patterns without forgetting earlier knowledge.
How can you deal with outliers or anomalies when training an autoencoder for feature extraction?
Outliers or anomalies can skew the reconstruction objective since the autoencoder attempts to minimize the mean reconstruction error across all samples. If a subset of data points are extreme outliers, the network might allocate a portion of its capacity to reconstruct these rare cases, thereby weakening its ability to capture the core distribution of normal data.
A simple but effective strategy is to first perform data cleaning or outlier filtering using robust statistical approaches (e.g., interquartile range filtering) before training. Another technique is to use robust loss functions (like L1 norm) instead of a pure squared-error loss, thus placing less emphasis on large errors. Denoising autoencoders can also help; by intentionally adding noise to the input, the model emphasizes learning the general structure rather than exact details that might arise from outliers.
However, one must remain cautious with discarding outliers, especially if they might be relevant for certain downstream tasks like fraud detection. In such scenarios, you may intentionally train the autoencoder primarily on “normal” data, and use reconstruction error to detect anomalies. But for pure feature generation, it is typically best to remove or reduce the influence of outliers during training to ensure stable and representative features.
How do you pick the right network depth and width for the encoder and decoder?
Choosing network architecture can be tricky. If the encoder and decoder are too shallow or too narrow, the model may lack capacity and struggle to minimize reconstruction error, producing latent features that do not fully capture the data’s complexity. If the architecture is too large, the autoencoder might overfit, learning an identity mapping that does not generalize well.
Typically, one starts with a configuration in which each layer has progressively decreasing dimensionality in the encoder (down to the bottleneck), and the reverse progression is used in the decoder. Hyperparameter tuning (e.g., random search or Bayesian optimization) is often employed to find a suitable combination of layer depths, widths, and activation functions.
Evaluating different autoencoder architectures should be done not just on reconstruction error but also on how well the resulting latent representations perform on downstream tasks (classification, clustering, etc.). Cross-validation can provide insight: if larger architectures consistently yield better downstream performance while avoiding severe overfitting, they might be the right choice. Conversely, if validation metrics plateau or degrade, a smaller model may suffice.
Could the learned features be overly specific to certain classes or subgroups in the data?
Yes. If the dataset contains imbalances or certain subgroups dominate, the autoencoder may bias its learned representation toward these frequent patterns. Underrepresented classes or subgroups might be poorly reconstructed, and thus yield latent features that are less discriminative for those cases. This leads to suboptimal performance in downstream tasks, particularly for minority groups.
One approach to mitigate this is data balancing, where you sample more instances of minority classes or augment the data to ensure the autoencoder sees a representative distribution. Another strategy is to adopt loss weighting or specialized sampling during training so that the autoencoder dedicates proportionate emphasis to minority segments.
Analyzing reconstruction error across subgroups can help identify bias. If reconstruction error is significantly higher for certain classes, it is a signal that the features might be skewed. Remediation involves rebalancing the training set, adjusting architecture hyperparameters, or exploring specialized methods such as conditional autoencoders that explicitly incorporate class labels in the latent representation.
How do you handle situations where the latent space is not interpretable, yet the application domain requires explainability?
Autoencoders, especially deep ones, produce latent representations that can be highly abstract and not inherently interpretable. In domains like finance or healthcare, transparency in decision-making may be mandatory. If direct interpretability is crucial, vanilla autoencoders might not satisfy regulatory or stakeholder requirements.
One partial remedy is to use approaches such as Variational Autoencoders (VAE) with disentangling techniques (like beta-VAE), which encourage latent dimensions to represent more independent factors of variation. While not perfectly interpretable, these techniques can at least isolate certain data-generating factors. Another path is to integrate domain knowledge into the autoencoder structure, for instance by designing specific bottleneck neurons to represent known factors. Yet this demands advanced domain expertise.
For post-hoc interpretability, one might investigate gradient-based attribution or local surrogate models (e.g., LIME/SHAP) that approximate which input features heavily influence the learned representation. Even then, bridging the gap between abstract latent dimensions and direct interpretability remains a challenge.
What are the computational considerations when training large-scale autoencoders for feature generation?
Training autoencoders on massive datasets can become computationally expensive because the model must process large numbers of samples while learning an appropriate compression. This can lead to long training times and high memory usage for both model parameters and intermediate activations.
Scaling tactics include:
• Distributed or parallel training: Splitting the data across multiple GPUs or machines and aggregating updates. • Mini-batch training: Ensuring that batch sizes fit into memory while still preserving stable gradient estimates. • Model pruning or distillation: Once the autoencoder is trained, one can prune redundant weights or distill the representation into a smaller model that is cheaper to run at inference time. • Mixed-precision training: Exploiting half-precision or other lower-precision arithmetic to speed up computations on compatible hardware.
Monitoring speed versus reconstruction quality helps find a balance between a network large enough to capture relevant features and one that is efficient in both training and inference. Additionally, specialized architectures like convolutional layers (for images) or transformer layers (for sequences) might be more suitable for certain data types, potentially reducing the parameter count compared to naive fully connected designs.
How do you maintain consistency between the encoder outputs and the decoder inputs when you only plan to use the encoder for feature generation?
During training, the decoder feedback forces the encoder to produce latent representations conducive to reconstruction. Once training is done, you may discard the decoder. Even though the decoder is no longer used, its influence during training was vital to ensure that the latent features were meaningful.
However, a pitfall can arise if post-training modifications are made to the encoder architecture, or if the system is placed in an environment with data quite different from the training set. Without the decoder’s active reconstruction feedback, there might be a drift in feature semantics. A thorough validation on out-of-sample or real-world data is crucial to confirm that the features remain robust.
Some practitioners keep a small portion of the decoder to validate that the encoder is still producing valid internal representations. Alternatively, you could periodically check reconstruction error on a validation set to make sure the encoder has not strayed from generating representations that reflect genuine patterns in the data.