
ML Interview Q Series: Is the LASSO approach a feasible way to select base learners in an ensemble model?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
LASSO (Least Absolute Shrinkage and Selection Operator) is a well-known technique primarily applied to linear or generalized linear models to shrink certain coefficients toward zero, effectively performing variable selection. In the context of ensemble learning, one can think of each potential base learner as a “feature,” with the associated coefficient dictating how heavily that base learner influences the final prediction. When the L1 penalty is large, some coefficients naturally become zero, effectively discarding those base learners from the ensemble.
One can formulate an ensemble learning objective enhanced by an L1 penalty, where the goal is to minimize a loss function subject to a penalty on the sum of the absolute values of the learner coefficients. A typical formulation might look like:
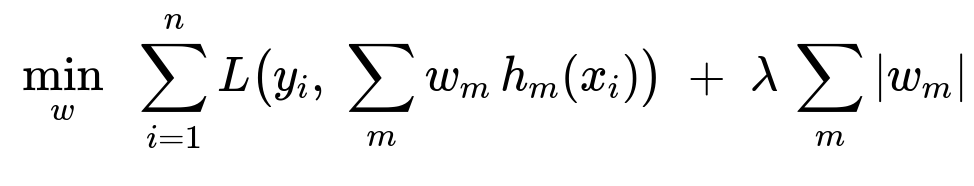
Here, w is the set of coefficients (one per base learner), h_m represents the m-th base learner, y_i is the true label for the i-th data instance, and L is a loss function such as mean squared error or logistic loss. The hyperparameter lambda controls the strength of the L1 penalty. As lambda increases, the magnitude of some w_m terms tends to shrink to zero, removing certain base learners altogether.
When using LASSO for base learner selection, you focus on identifying the subset of learners that remain with non-zero coefficients. This allows an ensemble to contain only the most critical learners, leading to a sparser model that is often more interpretable and potentially less prone to overfitting.
However, there are some nuances to consider: If multiple base learners are highly correlated, LASSO might arbitrarily keep just one of them in the model while shrinking others to zero. Also, choosing the lambda hyperparameter requires careful cross-validation or another model selection strategy. If lambda is too high, you might end up removing too many learners, leading to underfitting. If lambda is too low, you might not remove enough, failing to benefit from the intended sparsity.
In practice, LASSO for base learner selection can be more computationally expensive for very large ensembles. Nonetheless, it remains a valid approach whenever the ensemble’s search space is not prohibitively large. Depending on the framework (like scikit-learn or specialized libraries), you can implement LASSO-based selection easily by treating predictions from each base learner as an input feature to a linear model with an L1 penalty.
Illustrative Python Example
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Suppose we have predictions from M base learners
# X.shape = (n_samples, M) where each column is the prediction from a base learner
# y is the true target vector of shape (n_samples,)
X = np.random.rand(100, 5) # Example with 5 base learners
y = np.random.rand(100)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lasso_model = Lasso(alpha=0.1) # alpha is our lambda hyperparameter
lasso_model.fit(X_train, y_train)
selected_coefficients = lasso_model.coef_
print("Coefficients assigned to each base learner:", selected_coefficients)
print("Non-zero coefficients correspond to selected base learners")
y_pred = lasso_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("MSE on test set:", mse)
In this example, each column in X is a base learner’s prediction. By applying the Lasso model, certain columns might be assigned zero coefficients, effectively excluding those learners from the ensemble. We then measure performance using MSE as an example metric.
Why It Works
By imposing an L1 penalty, LASSO encourages coefficients to become exactly zero. This property is extremely useful for model selection when we want to filter out unimportant features or in this scenario, drop unnecessary base learners.
Potential Risks
Overly aggressive regularization. If lambda is set too high, all or most coefficients might be forced toward zero, leading to a degenerate ensemble.
Collinearity problems. If several base learners are highly correlated, LASSO might drop all but one, which could be an issue if each base learner encodes unique nuances about the data. Techniques like Elastic Net, which combines L1 and L2 penalties, may mitigate this issue.
Model stability. LASSO solutions can vary dramatically with small changes in training data or hyperparameter tuning if the base learners are highly correlated.
Best Practices
One typically performs cross-validation over a grid of lambda values to find the optimal regularization strength. This approach balances bias and variance to yield a final ensemble that is both sparse and accurate.
When base learners are correlated, or if you suspect the data is highly multicollinear, it is wise to compare LASSO with alternatives like Ridge Regression (L2 penalty) or Elastic Net (L1 + L2). The latter can stabilize feature (or base learner) selection by balancing both forms of regularization.
Ensuring a good distribution of base learners. If your ensemble includes many similar or identical learners, LASSO might pick only one. It’s best to diversify the base learners to maximize the gain from the selection process.
What If We Need Probabilistic Outputs?
If your model requires probability estimates (e.g., a classification task), you can still apply LASSO-based selection but with a logistic or another classification loss in the objective. The same principle of L1 regularization remains applicable, helping to set certain coefficients to zero.
Follow-up Questions
Could LASSO completely eliminate too many base learners and harm accuracy?
This possibility exists if the lambda hyperparameter is chosen poorly. An excessively large lambda shrinks most coefficients to zero, underfitting the data and hurting performance. A systematic cross-validation or information-criterion-based approach typically helps you identify a suitable lambda that balances sparsity and predictive capability.
Does LASSO handle correlations among base learners effectively?
Not always. LASSO tends to pick one among multiple correlated base learners and zero out the others. If the correlated learners each contribute some unique aspect, losing them might affect performance. Techniques like Elastic Net, which adds an L2 term, can spread out the coefficient weights among correlated learners instead of zeroing them out.
Are there practical constraints on the number of base learners we can use with LASSO?
LASSO can still be applied with a large number of base learners, but it might become computationally expensive as the number grows. The fitting process typically uses coordinate descent or similar optimization, which is efficient but can be lengthy if you have very many learners. In extremely large-scale scenarios, alternative methods of dimensionality reduction or specialized parallel solutions might be more practical.
How do we interpret the coefficients if the base learners are not linear?
Even if the underlying base learners are non-linear models, the LASSO framework simply treats each learner’s output as an input feature. The interpretability then lies in which base learners are retained (non-zero coefficient) and how large or small that coefficient is. It does not directly interpret the complex internals of a neural network or other non-linear learners but simply the final linear combination.
Is LASSO always the best choice for base learner selection?
It is a strong candidate when you want an easily interpretable ensemble with a clear mechanism for dropping less useful learners. However, in some applications, other approaches (like greedy selection based on performance improvement or Bayesian model averaging) can also be effective. The choice depends heavily on your data characteristics and desired trade-offs between interpretability, accuracy, and computational cost.