
ML Interview Q Series: Iterative Error Analysis for Refining Models on Edge Cases

📚 Browse the full ML Interview series here.
Error Analysis and Iteration: After deploying a model, you notice it consistently makes errors on a specific subset of cases (for example, images with poor lighting or a particular category of user input). How would you conduct error analysis to improve the model on these edge cases? *Describe a process: collect and examine mispredictions, identify patterns or commonalities, decide whether to get more training data for those cases, engineer new features, or adjust the model (or even create a special-case model). Emphasize the iterative nature of model improvement based on real-world feedback.*
High-Level Approach to Error Analysis and Model Iteration
Error analysis revolves around systematically examining where a trained model fails, identifying commonalities in those failures, then improving the model or data in a targeted manner. The general idea is to find a pattern in mispredictions, hypothesize why the model might be going wrong, and then address those issues with data strategies or model adjustments. This iterative process continues until errors are significantly reduced or better understood.
Identifying Mispredictions and Collecting the Data
It is useful to collect all instances where the model fails and to store or label them in a separate subset. Within a production environment, each time a user query or an incoming data sample leads to a poor prediction, that instance can be automatically logged. Once a sufficiently large subset of failing cases is collected, the next step is to group and manually inspect them to see whether there are recurring features or data conditions that cause the model to fail.
Searching for Patterns and Clusters of Errors
Once mispredictions are isolated, it helps to look for patterns. For image-based tasks, you might observe that poorly lit images or images with certain artifacts cause more confusion. For NLP tasks, you might find that certain language styles, slang, or domain-specific jargon result in incorrect outputs. One approach is to visually or programmatically cluster the mispredictions:
You could compute embeddings (for instance, using the latent representation from a neural network) for each erroneous sample and use a clustering algorithm (like k-means) to group them. Clusters that emerge might show that the model systematically struggles with a particular concept or data domain.
Root Cause Analysis
When a pattern is identified, the next step is to reason about the cause. It can be a data distribution shift, meaning the training data distribution did not match these special cases. Or it can be a lack of key features in the input. It might be that the architecture is not well-suited to handle certain variations (e.g., poor lighting conditions in images). Another possibility is that the model is overfitting to the most common patterns in the data and failing to generalize to rare scenarios.
Sometimes, an initial question is whether the label itself was correct or consistent. Especially in large-scale systems, label noise or annotation errors can cause a portion of mispredictions. Therefore, one aspect of root cause analysis is verifying the ground-truth labels to ensure the model isn’t “correctly” predicting an apparent mismatch because of human or mechanical annotator errors.
Data Gathering Strategies
If the primary issue is insufficient or poorly representative data for the problematic subset, acquiring or generating more examples of those edge cases can be extremely beneficial. This might involve:
Collecting more real-world samples from production, specifically focusing on the underrepresented edge conditions. Applying data augmentation. For instance, for images with poor lighting, you can systematically reduce brightness or add synthetic noise to the training images.
When applying data augmentation or seeking additional data, the aim is to ensure the model sees enough variety to generalize to the real-world distribution.
Feature Engineering
Model failures may arise because critical features are missing or not effectively utilized. This often requires domain expertise to think about new potential inputs. For example, if the problem arises in speech recognition under noisy conditions, you might consider additional acoustic features or specialized denoising steps. If the problem is in text classification for a particular domain, you might incorporate domain-specific lexicons or more advanced tokenization steps. These new features should be tested to confirm that they help reduce errors in the problematic subset.
Model Adjustments
Sometimes model architecture or hyperparameter tweaks can help. For instance:
Using a more robust loss function or adjusting class weighting if the failing subset belongs to a minority class. Increasing model capacity if the subset is consistently being misclassified and the model shows signs of underfitting. Using a specialized architecture, such as a different CNN configuration for images that handle low-light conditions better, or a domain-specific transformer in NLP tasks.
In certain scenarios, elaborate techniques like transfer learning can help if you have a pretrained model specialized for the type of data distribution your edge case belongs to.
Creating Specialized Models
Occasionally, it is more effective to create a separate specialized model for a known, consistently problematic domain. For example, if your application must handle typical daytime images and also nighttime images, you can train a dedicated nighttime model that focuses on the specific challenges of low-illumination. At inference time, a simple classifier (or a preliminary decision process) could decide which model to use. This approach can be more complicated operationally, but it can yield improvements if the original single model struggles with widely divergent distributions of data.
Iterative Feedback Loop
As soon as new data arrives or as new error modes are discovered, the error analysis process is repeated. The model can be retrained with additional data or new features. It is important to maintain an iterative loop:
Collect new mispredictions. Analyze and diagnose. Improve data or model. Deploy and collect further feedback.
Eventually, performance will plateau or will become good enough to meet the product or deployment requirements. Ongoing monitoring is recommended to catch regressions if the data distribution changes.

In practice, you might keep a separate misclassification set S (all samples where the model predicts incorrectly) and measure:
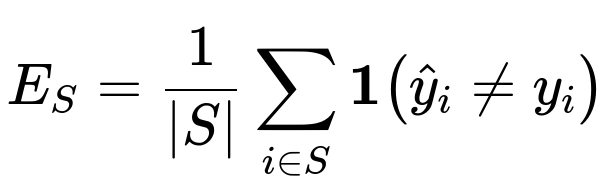
as the error specifically within that subset to monitor whether targeted improvements help reduce the error there.
Code Example for Error Collection and Analysis in Python
import numpy as np
import torch
# Assume we have a PyTorch model and a DataLoader 'loader' that yields (inputs, labels).
# We'll collect mispredictions in a list.
mispredictions = []
model.eval()
with torch.no_grad():
for inputs, labels in loader:
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
# Compare predictions with labels
incorrect_indices = (predicted != labels).nonzero(as_tuple=True)[0]
# Store the mispredicted samples and relevant info
for idx in incorrect_indices:
mispredictions.append((inputs[idx], labels[idx], predicted[idx]))
# Now, 'mispredictions' can be analyzed further to look for patterns.
One might then visualize these mispredictions, group them by label or metadata, and see if certain categories appear repeatedly. If it is an image dataset, you might display them in a grid to visually inspect them. For text-based tasks, you might store them with the input text and the predicted vs. true label for further inspection.
How would you handle highly imbalanced edge cases or rare scenarios?
When the edge case is exceedingly rare in production data, it might be difficult to gather enough training samples. This can lead to underrepresentation of that scenario in the training set, causing the model to ignore or fail to learn it properly. Potential solutions include oversampling, data augmentation, or generating synthetic data that resembles the real rare scenario. If feasible, a targeted data collection campaign that specifically seeks out the rare scenario can boost robustness. Another approach is to use class weighting or cost-sensitive training where mistakes on the rare class are penalized more heavily than on the majority classes.
In some instances, the model may show improved performance simply by artificially balancing the dataset. But it is critical to ensure that you are not introducing unrealistic distributions that cause your model to degrade in general scenarios. The balancing (or any data manipulation) must reflect the real domain as closely as possible.
What if you discover that the model is performing well on most metrics but fails on these edge cases that only affect a small fraction of users?
Even if the overall metrics (accuracy, F1 score, etc.) look good, an important aspect of product quality is ensuring that all user segments receive satisfactory performance. If the problematic subset belongs to high-value clients or can lead to disproportionate brand impact, the error analysis is crucial. You can:
Set up specialized monitoring and alerts to detect errors in the targeted subset. Conduct targeted improvements (data augmentation, specialized features, model ensembling) just for that subset. Conduct user acceptance testing or domain expert review specifically for those edge cases.
From a system-level perspective, you need to decide if investing in separate models or specialized tuning is justified. This depends on whether the cost and complexity of an additional specialized pipeline is offset by the gains in user experience or revenue.
Could you explain when it makes sense to build a separate model for edge cases versus continuing to rely on one comprehensive model?
A separate model might be more suitable if the edge cases represent an entirely different distribution or domain that is seldom encountered by the main model. For instance, if your main model processes standard English text but occasionally sees text in a niche dialect that it was never trained on, you might do better with a separate model tuned to that dialect. Another scenario is if you have an extremely large base dataset that has little to do with the special subset, and it becomes difficult for a single model to “pay attention” to the minority domain.
However, multiple models complicate deployment, maintenance, and monitoring. If you can incorporate domain-specific data into a single model through robust data augmentation and architecture changes, it might be more efficient to maintain one model. Typically, a specialized model approach is used for high-stakes or very distinct categories of data where the domain shift is too large for a single model to handle effectively.
How do you prevent overfitting when adding new data specifically for edge cases?
Overfitting can happen if you incorporate a small but specialized set of samples into your training process without careful validation. One strategy is to maintain a validation subset that includes a balanced mix of typical cases and edge cases. Monitoring performance on both the overall distribution and the specialized edge subset helps ensure you are not over-optimizing for those edge cases at the expense of general performance. Early stopping, regularization (such as dropout for neural networks), or using cross-validation can help detect if the model begins to fit noise in the new data.
Another consideration is using data augmentation or domain-consistent transformations to expand the volume of the newly acquired edge case data. This can reduce the risk of the model simply memorizing the small set of new samples.
How do you know when to stop iterating and improving on these edge cases?
The decision is product-driven: once errors on the edge cases fall below an acceptable threshold (based on user feedback, business requirements, or cost-benefit analyses), or additional model improvements become too costly compared to potential gains, you might pause iteration. There is a point of diminishing returns where collecting more specialized data or adding model complexity might not justify the improvements in performance.
If your system is mission-critical (like in medical diagnostics), you might never truly “stop” but instead continue to monitor performance and re-train on new data if drift or new edge cases arise. The iterative process is ongoing as long as performance or domain requirements evolve.
When would you consider advanced techniques for error analysis beyond basic grouping of mispredictions?
Simple grouping and visual inspection are often enough for smaller datasets or when you can easily see the patterns. However, in large-scale systems, advanced techniques such as embedding-based clustering, dimensionality reduction (e.g., t-SNE or UMAP), and interactive labeling interfaces become very valuable. These methods help reveal subtle structures or subgroups in the mispredictions that are hard to detect manually. You might also use advanced metrics like calibration error to see if the model is systematically over- or under-confident in certain subsets.
Furthermore, if you integrate external knowledge graphs or domain-specific constraints, you might discover that certain domain rules are consistently violated in mispredictions. This can be a powerful way to discover hidden or high-level reasons for errors, especially in NLP or structured data tasks.
Can you describe a strategy to handle changes in the distribution of data over time that lead to new edge cases?
This is typically referred to as dataset drift or distribution shift. The best practice is to build a pipeline that continuously monitors the distribution of incoming data. When new edge cases arise, you collect them, label them if necessary, and retrain the model. A champion-challenger approach can be used, where the existing “champion” model remains in production while a new “challenger” model is trained on the updated distribution. If the challenger shows improved performance on both the old and new distributions, it replaces the champion.
Active learning can also help in scenarios where labeling costs are high. The model can flag uncertain or potentially novel samples, focusing human labeling effort on the most ambiguous or drifting data regions. This ensures that the training dataset evolves alongside the real-world data distribution, reducing future mispredictions related to newly emerged edge cases.
How might you balance engineering resources when dealing with rare but severe failure modes?
This largely depends on the severity of the error and its impact. For example, in autonomous driving, even a rare failure mode can be catastrophic. You would likely invest a lot of engineering effort to ensure that your model can handle those edge cases. Conversely, if it is a minor inconvenience for a small set of users, you may choose to address it less aggressively. In practice, you can set up a priority system where each subset of errors is ranked according to frequency, severity, and business impact. This ensures resources are allocated to the areas that provide the best trade-off between effort and improvement.
The guiding principle is always balancing the cost of data collection, annotation, and model development against the potential gains in reliability and user satisfaction. In high-stakes applications, you often invest in advanced error analysis and specialized solutions for even the smallest subsets of errors.
Below are additional follow-up questions
How would you handle a situation where the mispredictions vary across multiple slices of data, making it hard to pinpoint one single root cause?
When errors appear in different contexts, you can begin by categorizing mispredictions according to metadata such as input size, source device, or time of day. If multiple slices each have distinct failure modes, start by prioritizing those that have the greatest user or business impact. Look for commonalities across the slices: sometimes subtle or compound issues (like data preprocessing steps that behave differently for certain input types) cause failure in multiple seemingly separate slices.
A practical technique is to tag each sample with a set of attributes (like domain, user type, or environment conditions) and then slice the error data across these tags. You can visualize the performance for each attribute combination, potentially revealing multi-factor interactions. This multi-slice approach also highlights conflicting patterns (for example, a fix that helps “nighttime, high-motion images” but worsens “daytime, high-motion images”). The key is a systematic grouping strategy so no potentially important subpopulation remains hidden.
One pitfall is devoting too much effort to extremely rare slices that might be overrepresented in your error set simply because you are specifically collecting mispredictions there. Always confirm whether a slice truly represents a meaningful proportion of your real-world use cases, or whether it is a negligible anomaly. Another subtlety is that some errors might span categories or be caused by interplay between dataset biases, model architecture limitations, and training hyperparameters. You might end up implementing a layered solution that addresses each slice differently, or you might unify them with a more flexible model architecture once you see a shared root cause in data representation or model capacity.
What if the errors seem to occur under transient or ephemeral conditions that are difficult to replicate—like temporary user behavior changes or sudden environmental changes?
Ephemeral conditions, such as a sudden spike in unusual user inputs or environmental changes (e.g., a lighting anomaly in a camera feed that only happens under rare weather conditions), can be tricky. The first step is to confirm that these conditions were genuinely ephemeral rather than part of a larger distribution shift. If they are truly short-lived, a quick fix might be to filter or flag them, but for more persistent changes, a deeper solution is needed.
One approach is to implement a rolling buffer of training data to capture recent distributions. For example, if your application experiences random surges of user interest in specific topics, your model might need an adaptive training scheme that updates its parameters more frequently (online or continual learning). You might also incorporate data augmentation to simulate ephemeral conditions. If the ephemeral scenario is related to user behavior (like a meme or trend that spikes for a short time), you could adopt an active learning strategy that quickly labels these new inputs and retrains a portion of the model.
The biggest pitfall is overfitting to ephemeral data. If you quickly adapt or over-weight these unusual samples, you can damage performance on the core, stable distribution. Maintaining multiple versions of the model (or using domain detection) can help ensure that ephemeral changes do not permanently distort the model.
How do you address errors that only surface under high concurrency or heavy system load, which might not manifest in offline evaluations?
When errors appear under load conditions, you must verify that the problem is indeed with the model’s predictive quality rather than a system integration issue (for example, timeouts causing incomplete data, concurrency locks dropping packets, or latencies that disrupt feature extraction pipelines). First, gather logs of real-time inference: capture not only the raw input and output but also metadata such as request timestamps, system resource usage, or any internal timeouts.
By comparing predictions made during high load vs. normal conditions, you can see if the input data stream changes or if the model might be skipping certain computations when resources are constrained. If your model’s predictions degrade under heavy load, you might consider optimizing the model’s inference pipeline or scaling up resources to ensure stable data flow. In certain real-world pipelines, concurrency can cause race conditions that reorder data streams or lead to partial features, so you might implement synchronization checks to confirm your model is receiving the same type of input in heavy-load scenarios as in normal conditions.
A common pitfall is to immediately blame the model’s architecture or data when the root cause is in the surrounding system. Another subtle scenario is that under load, certain caching or approximate computations (like approximate nearest neighbors in recommendation systems) might be used, leading to inferior inputs that hamper performance. Debugging calls for detailed logging, plus stress tests in staging environments that replicate high concurrency.
How do you proceed if data collection for the problematic edge cases is heavily restricted by privacy or regulatory constraints?
When privacy rules limit data collection, you must rely on other tactics for improving performance on edge cases. Techniques like differential privacy can help glean aggregate insights while minimizing the risk of exposing personal data. Federated learning might be used if data cannot leave a user’s device: the model is trained locally on user devices and only aggregated updates are centralized. If these are not feasible, you can sometimes work with anonymized data or apply strict data de-identification pipelines.
One subtlety is ensuring that anonymized data still accurately represents the problematic edge case. Over-aggressive anonymization might strip away key features (like location or time) that are crucial for understanding the problem. Another challenge is regulatory compliance that might prevent you from storing raw data logs. In that situation, adopting in-place error analysis—where you run your analytics on user devices without streaming raw data back—can help. Methods like synthetic data generation that mirror the regulated domain can also be explored, but you must confirm that synthetic distributions capture the real nature of the edge scenario.
How do you determine if the model’s architecture is inherently not capturing complex data interactions, and how do you validate that hypothesis?
You can begin by analyzing residual errors using interpretability methods or by looking at the distribution of feature importance. If you notice that certain features or combinations of features systematically appear in the misclassified subset, and your current model architecture does not handle these interactions well (for example, you are using a shallow linear model on highly non-linear data), this may be a sign that the architecture is insufficient.
One strategy is to prototype a deeper or more expressive architecture (such as upgrading from a simple CNN to a more advanced architecture in image tasks) and see if that directly reduces errors on the problematic subset without detrimental overfitting. Another strategy is to incorporate domain-specific knowledge or richer feature engineering to see if that resolves the complexity. If you see consistent gains from these more expressive approaches, that is evidence the original architecture was a bottleneck.
However, switching architecture might not always be the right remedy. Sometimes the issue is data coverage or labeling inconsistency rather than the model’s representational capacity. So it’s crucial to run ablation studies on new architectures while controlling for data improvements. If the new architecture with the same data fails to fix the errors, it might suggest you need better data or labels, not necessarily a fancier model.
How would you incorporate interpretability or explainability methods specifically into your error analysis to identify root causes for failures?
In vision tasks, you can apply saliency maps or Grad-CAM to highlight which parts of an image the model attends to. If the mispredicted samples consistently show the model focusing on irrelevant regions (like the background instead of the subject), that suggests a data or training approach issue. In NLP tasks, attention heat maps or feature attribution methods can reveal whether the model is ignoring crucial tokens or over-weighting noise words.
By systematically generating these interpretability outputs for your mispredictions, you can look for patterns: maybe the model focuses on shadows in poorly lit images instead of the actual object. Or in text classification, it might be ignoring domain-specific jargon. If you see such patterns, you can refine data collection (e.g., gather more examples with varied backgrounds) or feature engineering (e.g., ensure domain-specific tokens receive enough representation).
Pitfalls include over-interpreting these visualizations, as they do not always perfectly reflect the model’s decision process. Also, some interpretability techniques can be computationally expensive, so you might sample a subset of the errors to analyze in-depth. Another subtlety is that for highly complex models with multiple attention layers (like large Transformers), a single interpretability tool can provide only partial insight, so you might combine multiple explainability methods.
How do you ensure model performance remains consistent across iterations while you focus on improving specific edge cases?
To maintain consistency, you need robust regression tests and versioned evaluation protocols. Each time you train a new model iteration, you evaluate on both the standard test set (covering the overall distribution) and a curated edge-case test set. You then compare metrics (accuracy, F1, precision/recall, or specialized metrics) across versions to ensure you have not regressed on the core distribution while enhancing edge-case performance.
Additionally, you can create a stable “golden set” that includes representative data from all important segments. For tasks like image classification, keep a carefully labeled set with examples from each known category and environment condition. Ensuring consistent performance means not only measuring aggregate metrics but also measuring them per category or subpopulation. Sometimes, you might use a weighted metric that emphasizes performance on critical edge cases more heavily.
A subtlety is deciding how to trade off small performance drops on the overall set against major gains on crucial edge cases. If you do not have a product-level weighting of these trade-offs, you risk flipping back and forth in performance across model versions. Clear acceptance criteria that specify allowable performance deltas for each segment can guide the iteration process.
How might you apply advanced debugging techniques, like integrated gradients for images or attention head analysis for NLP, to discover deeper reasons for model mispredictions?
Integrated gradients can show how each pixel (for images) or token (for text) contributes to the model’s output by integrating the gradients from a baseline input to the actual input. By running integrated gradients on your misclassified samples, you observe which parts of the input have the greatest influence on the prediction. If you see that the influences focus on extraneous areas (like a watermark on an image rather than the main subject) or random tokens in text classification, that indicates the model is learning spurious correlations.
Attention head analysis in Transformers for NLP can reveal if certain heads are focusing exclusively on punctuation or numerical tokens when they should be focusing on domain keywords. If you detect that multiple heads are ignoring the relevant domain terminology in the failing samples, you might incorporate specialized tokenizers or domain-adaptive pretraining.
A subtlety is that these explanations do not always map cleanly to human understanding. Some heads can be essential in ways not obvious from the raw attention patterns. Thus, it is often best to combine interpretability methods with manual domain expert review. Another subtlety is that running integrated gradients or attention analysis at scale can be computationally heavy, so you may need to sample or adapt your approach.
What strategies do you recommend for addressing potential bias or discriminatory behavior uncovered during error analysis?
If your analysis reveals that certain protected groups or demographic segments are disproportionately misclassified, you must investigate whether the training data is unbalanced or if the model is picking up sensitive attributes as a proxy for labels. One approach is to measure performance metrics stratified by demographic groups, ensuring parity or minimal disparity. If disparities are identified, you might use techniques such as re-weighting, balanced sampling, or debiasing regularization in the training process.
You can also adopt fairness constraints that require certain statistical parity or calibration across subgroups. Another step is to carefully audit your training data: perhaps it lacks enough samples from certain subpopulations. Correcting data representation is usually the most direct way to address bias. If data cannot be collected, you might consider synthetic oversampling or transfer learning from more diverse datasets.
A pitfall is inadvertently introducing new biases while trying to fix old ones. It is crucial to have domain experts and stakeholder representatives in the loop, especially for sensitive applications like credit scoring or healthcare. Another subtlety is that some fairness metrics can conflict with each other, so you must choose the definition of “fairness” that fits your application’s requirements.
How do you differentiate errors stemming from the pretrained backbone model (in a transfer learning scenario) versus errors introduced during the fine-tuning phase?
When you use large pretrained models, a portion of errors might be inherited from the pretraining data or pretraining tasks. Another portion might come from how you have fine-tuned on your domain-specific dataset. To distinguish these:
Evaluate the pretrained model on your data without fine-tuning (e.g., by freezing all layers and only updating the classification head). Compare its error patterns to the fully fine-tuned model. If the same samples are misclassified in both scenarios, it could indicate the backbone itself is lacking certain representational capacity for those edge cases. Gradually unfreeze layers. Look at changes in performance. If misclassifications appear or disappear when certain layers are unfrozen, you gain clues about where the deficiency lies. Use domain-adaptive pretraining. If the model’s performance improves significantly just by training on domain text (for NLP tasks) or domain images (for vision tasks), it suggests the root cause was missing domain-relevant context in the pretrained backbone.
A subtle scenario arises when the backbone is robust, but the classification head or the objective function used in fine-tuning is not well aligned with your data distribution. Checking your loss curves and overall data coverage in the fine-tuning set can help you identify whether you simply need more domain examples. Another subtlety is that some pretrained models have known artifacts (for example, a certain vision backbone might be biased towards certain shapes or textures learned from ImageNet). You might partially mitigate these artifacts by adding domain-specific normalization or additional layers that can override the biases in the backbone.