
ML Interview Q Series: Joint Density Integration for Device Lifetime Expectation and PDF

Browse all the Probability Interview Questions here.
An electronic device contains two circuits. The second circuit is a backup for the first and is switched on only when the first circuit has failed. The device goes down when the second circuit fails. The continuous random variables X and Y denote the lifetimes of the first and second circuits, respectively, and have the joint density function

a. What is the expected value of the time until the electronic device goes down (that is, E(X + Y))?
b. What is the probability density function of the time X + Y?
Short Compact solution
From the given joint density, one can compute the expected value of the sum X + Y by integrating:
Rewrite (x + y) * 24 / (x + y)^4 as 24 / (x + y)^3 and use iterated integrals from 1 to ∞ with respect to x and y.
The integral evaluates to 6. Hence,

For the probability density function of T = X + Y:
Notice X + Y cannot be less than 2 because each variable is greater than 1. Therefore, for t <= 2, the cumulative distribution function for T is 0, implying the PDF is 0 there.
For t > 2, one calculates P(X + Y > t) by integrating the joint density in the region x + y > t, x > 1, y > 1.
Differentiating the resulting survival function gives the PDF:

Comprehensive Explanation
Overview of the Problem The device uses two circuits in series with respect to time: the second is operational only after the first fails, and the total operational time is X + Y. Here, X is the lifetime of the primary circuit, Y is the lifetime of the backup once it is switched on. We are given a joint density for X and Y, valid only when both exceed 1.
Reason X + Y >= 2 Since X > 1 and Y > 1, the smallest possible value for X + Y is 2. Hence, any calculations of distributions for T = X + Y below 2 will lead to probability 0.
Computing E(X + Y) To find E(X + Y), one sets up:
T = X + Y. We use the double integral:
E(X + Y) = ∫(x=1 to ∞) ∫(y=1 to ∞) (x + y) [24 / (x + y)^4] dy dx.
Inside this integral, (x + y) * 24 / (x + y)^4 = 24 / (x + y)^3. One can integrate in any convenient order:
Fix x and integrate over y from 1 to ∞.
Then integrate the resulting function over x from 1 to ∞.
The computations simplify step by step until the final numeric value 6 is obtained. Thus,
E(X+Y)=6.
Finding the PDF of T = X + Y We define g(t) = d/dt [P(T <= t)]. Since T = X + Y >= 2, we have:
For t <= 2, P(T <= t) = 0, so g(t) = 0.
For t > 2, we compute P(T > t) = ∫ f(x, y) dx dy over the region x > 1, y > 1, x + y > t. Then the PDF is obtained by differentiating 1 - P(T > t).
After careful integration and differentiation, the result is:

One can verify g(t) integrates to 1 over t from 2 to ∞ by breaking it into partial fractions or by direct integration.
Key Intuition The joint density is concentrated in the quadrant x > 1, y > 1, but more heavily weighted (due to the (x + y)^4 in the denominator) as x + y gets larger. The random variables are not independent but correlated through their joint PDF that depends only on x + y. Finding the distribution of T = X + Y is facilitated by geometry (integrating in a region x + y > t). Once we have the survival function, taking the derivative gives the PDF.
Practical Interpretation The device’s total lifetime cannot be below 2 because each component on its own lasts at least 1 time unit. In large-sample testing, on average the sum of these times is 6, which makes sense given the strong decay from the (x + y)^-4 factor.
Handling Potential Confusion A common pitfall is to forget the support region x > 1 and y > 1, or to assume T >= 0. In fact, T >= 2. Another subtlety is ensuring that the integral for E(X + Y) is handled carefully, avoiding mixing up domains or bounds in the iterated integrals.
No Contradiction with Independence One might wonder if X and Y are independent. They are not. The given joint distribution is not a product of separate factors for x and y. Instead, it has a dependence on (x + y). Despite that, X + Y is well-defined and the integrals can be approached in a straightforward manner once the domain is recognized.
Checking the PDF Normalizes to 1 It is often good to verify that ∫(2 to ∞) 24(t-2)/t^4 dt = 1. This check ensures that g(t) is a valid PDF. The partial fraction decomposition or direct integration confirms the result.
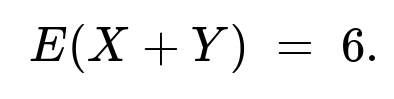


Potential Follow-up Question: Why does the PDF start at t=2 rather than t=0?
Because X must exceed 1 and Y must exceed 1. Therefore, their sum X + Y must exceed 2. This makes the support of T start at 2, not 0. That is why g(t) = 0 for t <= 2.
Potential Follow-up Question: How can we verify that 24(t-2)/t^4 integrates to 1 over (2, ∞)?
We split 24(t - 2)/t^4 = 24/t^3 - 48/t^4 after factoring out t^4 in the denominator. Integrate each term separately from t=2 to ∞:
∫(2 to ∞) 24/t^3 dt = 24 ∫(2 to ∞) (1/t^3) dt = 24 [ -1/(2t^2 ) ] from t=2 to ∞ = 24 * (1/8). Similarly, ∫(2 to ∞) -48/t^4 dt = -48 ∫(2 to ∞) (1/t^4) dt = -48 [ -1/(3t^3) ] from t=2 to ∞ = -48 * (1/24).
Summing these evaluated terms yields 1, confirming that g(t) is a valid PDF.
Potential Follow-up Question: Could we have used a transformation approach (U = X + Y, V = X or Y) with Jacobians?
Yes, one can tackle it by introducing the transformation U = X + Y, V = X (or V = Y). The region of integration transforms to U > 2, V in [1, U - 1], etc. The Jacobian for (x, y) -> (U, V) is 1. Then we would integrate the resulting function in terms of U and V over the appropriate domain. Eventually, we would identify the marginal PDF for U. The final expression would match g(t) = 24(t - 2)/ t^4 for t > 2.
Potential Follow-up Question: What if the lower bound for X and Y was 0 instead of 1?
In that scenario, the sum X + Y could start at 0. The entire setup would change because the joint density f(x, y) might need to be normalized differently, and we would not have a guaranteed minimum sum of 2. Hence, the distribution of X + Y and its support would differ significantly. All the integrals and resulting expressions would need recalculation.
Below are additional follow-up questions
What is the hazard function for T and how do we interpret it in reliability terms?
The hazard function h(t) is often used in reliability analysis to characterize the instantaneous failure rate at time t, given survival up to that time. Formally, for a continuous random variable T with PDF g(t) and survival function S(t) = P(T > t), the hazard function is:
h(t) = g(t) / S(t), for t > 2 in this scenario (because T ≥ 2).
To derive h(t), we first recall that:
g(t) = 24 (t - 2) / t^4 for t > 2.
S(t) = P(T > t) = ∫(t to ∞) 24 (u - 2) / u^4 du, for t ≥ 2.
One can compute S(t) explicitly by integrating 24 (u - 2) / u^4 from t to ∞. Typically, we decompose (u - 2)/u^4 into partial fractions:
(u - 2)/u^4 = 1/u^3 - 2/u^4.
Then multiply by 24 and integrate from t to ∞. After we get the closed-form expression for S(t), we divide g(t) by S(t) to obtain h(t).
Interpretation:
The hazard function at time t represents how likely it is that the device will fail instantly after t has elapsed, provided it has survived until time t.
In reliability terms, if h(t) increases with t, it indicates an aging effect (the longer it runs, the more likely it is to fail soon). A decreasing h(t) suggests the opposite, while a constant h(t) would indicate a memoryless or exponential-like property.
By inspecting the functional form (which will not be constant), we see this device does not exhibit memoryless behavior; its hazard rate depends on t in a more complex way due to the (x + y)^-4 weighting.
Can T be memoryless? If not, why?
A memoryless distribution implies P(T > s + t | T > s) = P(T > t). The continuous memoryless distribution is the exponential distribution. However, from the form of g(t) = 24 (t - 2) / t^4 for t > 2, we can see that T does not resemble an exponential distribution on [2, ∞).
Reasoning:
A continuous distribution is memoryless only if its PDF is of the exponential type, i.e., λ e^(-λ(t - a)) for t ≥ a.
Here, the PDF 24 (t - 2) / t^4 clearly is not of that exponential form, indicating that T is not memoryless.
This aligns with the intuition that T = X + Y, where each of X and Y is at least 1, and the joint distribution depends on x + y in a polynomial manner. That structure typically does not produce a memoryless sum.
How might we simulate random samples from T = X + Y given the joint density?
Simulation Approach:
One way is to directly simulate X and Y from the joint density f(x, y) = 24 / (x + y)^4 for x > 1, y > 1. Then compute T = X + Y.
Generating (X, Y) from this joint distribution is not trivial because we cannot factorize f(x, y) into a product of separate marginal densities. However, we can use a transformation method:
Let U = X + Y and V = X (for example).
Then (X, Y) = (V, U - V). We restrict V ≥ 1, U - V ≥ 1, so V ≤ U - 1, and U ≥ 2.
The Jacobian for (U, V) → (X, Y) is 1. The transformed PDF becomes something proportional to 24 / U^4 over the region U ≥ 2, 1 ≤ V ≤ U - 1.
We can then employ an accept-reject method:
Sample U from the marginal distribution of U (which is g(t) = 24(t - 2)/t^4 for t ≥ 2).
Conditioned on U = u, pick V uniformly from [1, u - 1].
This gives (X, Y) with the correct joint distribution.
Alternatively, if we only need T, we could directly sample T from g(t). Then we do not require X and Y individually.
Potential Pitfalls:
Numerical instability in sampling from the distribution if not carefully implemented. For example, we need a precise method (inversion or accept-reject) to handle the tail.
Ensuring we do not mix up the domain constraints (V must ensure x > 1 and y > 1).
Handling floating-point overflow or underflow for large t values when computing acceptance probabilities.
What if we considered the correlation between X and Y?
Because f(x, y) depends only on (x + y)^4 in the denominator, X and Y are not independent. Yet, it’s instructive to assess whether X and Y are positively or negatively correlated:
Intuitively, if x is large, then y is “forced” to be somewhat large to maintain the same high density region or vice versa. We can investigate correlation ρ = Cov(X, Y) / (√Var(X) √Var(Y)) by computing Var(X), Var(Y), E(XY) from the joint distribution.
The integrals for E(XY) can be computed similarly to how we computed E(X + Y). But we must do: E(XY) = ∫(x=1 to ∞) ∫(y=1 to ∞) x y [24 / (x + y)^4] dy dx.
After obtaining E(X) = E(Y), E(X^2), E(Y^2), and E(XY), we can plug these into Corr(X, Y) = [E(XY) - E(X)E(Y)] / [√(Var(X)Var(Y))].
Possible Pitfalls:
Doing these integrals by hand is prone to error because the region x > 1, y > 1 plus the factor (x + y)^-4 can be tricky. One must ensure the iterated integral bounds are correct.
Numerical integration might be used as an alternative, but it requires careful sampling over an infinite region.
Interpreting Correlation:
If the correlation is positive, that suggests large values of X coincide more often with large values of Y. If negative, it indicates a trade-off. Given the structure 1 / (x + y)^4, it usually leans toward negative dependence: having a very large x makes x + y large, which might shift the density to smaller values for y. But the precise sign is not obvious without actual calculation; it requires the integral approach to be certain.
How do we handle the boundary at x=1 or y=1 if real-world data indicates slight deviations (e.g., x≥1.001 or y≥0.999)?
Real-World Considerations:
The model states x > 1 and y > 1 exactly. In practice, a device part might have a minimum guaranteed lifetime close to 1 but not exactly 1. If data shows some lifetimes slightly below 1 or exactly 1, the model becomes approximate.
If we suspect that 1 is an approximate threshold rather than an absolute cutoff, we might want to generalize the distribution or incorporate a slight shift: for example, let X' = X - 1, Y' = Y - 1, forcing X', Y' ≥ 0, and adjust the density accordingly.
Alternatively, we can accept a small modeling error, especially if the probability that X < 1 or Y < 1 is negligible.
Pitfalls:
Making a strict domain assumption (x > 1, y > 1) when real data can violate that slightly. This mismatch could impact reliability estimates.
Overcorrecting the model by ignoring the domain constraint entirely might lead to inaccurate tail behavior or misrepresentation of how soon circuits can fail.
How could we extend this to the case of more than two circuits in sequence?
Extension to n circuits:
Suppose we have circuits C1, C2, ..., Cn, each turning on when its predecessor fails, with random lifetimes X1, X2, ..., Xn, respectively. The total device lifetime T would then be the sum X1 + X2 + ... + Xn.
A key question is whether the n-dimensional joint density depends only on (x1 + x2 + ... + xn), or if it has other dependencies. If it’s a generalized version where f(x1, x2, ..., xn) = K / (x1 + x2 + ... + xn)^(n+2) (just as an example), we would integrate over x1 > 1, x2 > 1, etc. The sum T would then start at n.
The approach to finding E(T) would be an n-fold integral, and the method for obtaining the distribution of T would generalize the geometry of the region x1 + x2 + ... + xn > t.
Pitfalls:
The complexity of the integrals grows quickly with n. Analytical solutions might become unwieldy or impossible for large n.
One might resort to simulation or numeric integration.
Real-World Interpretation:
Many devices have more than two layers of redundancy. Understanding how the distribution scales with n is vital. If each circuit must be at least 1 in lifetime, T≥n in that scenario.
The tail behavior might drastically change with more circuits, as each new circuit in series extends the total lifetime but also complicates the correlation structure among all Xi.
Could we compute conditional expectations like E(X | X + Y = t)? What does that tell us?
For a sum T = X + Y, sometimes we want to know E(X | T = t), which is the expected value of X given X + Y = t. In principle:
E(X | X + Y = t) = ∫ x f(x, t - x) / g(t) dx, where x ranges from 1 to t - 1 (because x>1, y>1, so x< t if y is to remain >1).
Here, f(x, t - x) = 24 / (t)^4 when x>1 and t - x>1. That implies 1 < x < t - 1, and also t>2.
We would normalize by g(t) = 24 (t - 2)/ t^4.
Interpretation:
This conditional expectation can tell us how the lifetime of the first circuit typically compares to that of the second circuit, given that their sum is exactly t.
It can be a way to explore the relative contribution of X vs. Y to the total operational time for a device that lasted exactly t.
Potential Pitfalls:
We must ensure t > 2 so that x can lie in [1, t - 1]. If t is near 2, the integration range is small.
We need to keep the domain constraints in place: x>1 and y>1 => x>1 and t - x>1 => x< t - 1.
Such conditional expectations can yield insights into how the device’s subcomponents share the total time to failure when the sum is fixed.
If real-world data suggests X and Y have different minimal lifetimes, say X>0.5 and Y>1.5, could we adapt the distribution?
Yes, the given model f(x, y) = 24 / (x + y)^4 for x>1, y>1 is specifically calibrated to the domain x>1, y>1. If in practice circuit 1 can fail after 0.5 time units, and circuit 2 can fail only after 1.5 time units, the domain is now x>0.5, y>1.5. We would need to ensure:
The new domain matches x>0.5, y>1.5.
The function 24 / (x + y)^4 might no longer be the correct density because it may not normalize properly over x>0.5, y>1.5. We would recalculate the normalizing constant.
Alternatively, if we still keep the same functional shape 1 / (x + y)^4 but want to enforce x>0.5, y>1.5, then the constant in front (currently 24) must be adjusted so that the total probability integrates to 1 over the new region.
Pitfalls:
Failing to normalize over the new domain leads to an incorrect PDF.
The shape of the distribution might need reconsideration if circuit 1 and circuit 2 differ drastically in typical lifetimes. Sometimes separate parameters or distinct distributions are more appropriate than a single form that only depends on x + y.
If we only have partial data on X in practice, how can we estimate the distribution parameters?
Suppose we know the sum T = X + Y for each device but only have limited or noisy measurements of X. This introduces incomplete data:
We might adopt a maximum likelihood approach but must integrate out the missing variable. Because Y = T - X, we would incorporate the joint density f(x, T - x) into the likelihood and sum or integrate over the unobserved x.
If we have repeated observations T1, T2, ..., Tn, and partial data on X (or Y), we might use the EM algorithm (Expectation-Maximization). The E-step would compute expected log-likelihood given the partial data, and the M-step would update the parameter (here, the normalizing constant or any shape parameters, if we generalize 1 / (x + y)^4).
Challenges:
The domain constraints x>1, y>1 => x>1, T - x>1 => 2< T, x in (1, T-1).
This can complicate the integrals, especially when T is large.
Real data might not perfectly fit the model’s domain constraints. We might have to treat out-of-domain observations carefully or discard them if they are obviously outliers or not explained by the model.
These considerations highlight the complexity of fitting parametric forms to partial or incomplete observations in real-world reliability contexts.