
ML Interview Q Series: Mitigating Model Bias: Techniques for Fair Performance Across Diverse Subgroups.

📚 Browse the full ML Interview series here.
Fairness and Bias Mitigation: If you discover that your model is significantly underperforming for a particular subgroup (for example, a vision model has higher error rates for a certain demographic group), how would you address this fairness issue? Discuss approaches like collecting more representative training data, adding fairness constraints or reweighting during training, post-processing the outputs to reduce bias, and ongoing evaluation of model fairness metrics.
Data Representation And Collection
Ensuring that the dataset encompasses a sufficiently broad range of demographics, lighting conditions, viewpoints, and other relevant factors can help the model learn balanced features. Often, a root cause of biased model outputs is that the training data lacks examples of the underrepresented group. This leads to weaker learned representations and higher error rates on that specific subgroup. One approach to mitigate this is to either collect more data from the underperforming subgroup or augment existing data in a controlled manner. When the subgroup is small or difficult to collect, synthetic data generation methods can help, though these must be carefully validated for realism and consistency.
Another factor in data representation is verifying that labeling processes do not inadvertently encode bias. If the labels were generated by human annotators, there is the risk that some systematic labeling bias exists. For instance, in a face recognition dataset, labelers might systematically overlook certain attributes for one demographic group. A thorough auditing of the dataset can expose these biases. If discovered, one can attempt to relabel with improved guidelines, re-annotate via multiple annotators, or use specialized data cleaning algorithms.
Model Architecture And Fairness Constraints
Applying fairness constraints or reweighting strategies during training can help reduce disparate performance across subgroups. Instead of purely optimizing for overall accuracy or a single loss function, fairness objectives can be included. An example is to incorporate a penalty term that captures performance disparity across sensitive attributes. This typically involves measuring a fairness metric, such as demographic parity or equalized odds, and integrating it into the training objective.
When implementing a reweighting strategy, the loss function is typically multiplied by a factor that is inversely proportional to how frequently a subgroup appears. This can help the model pay more attention to underrepresented subgroups. A possible formulation of the weighted loss for each instance can be expressed in a simplified way as:
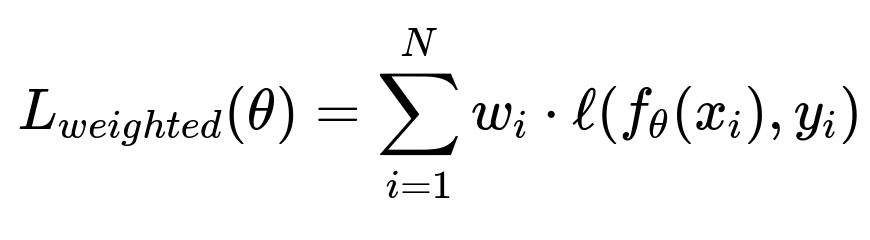
where θ are the model parameters, xᵢ is a training example with label yᵢ, ℓ is the loss term for the prediction, and wᵢ is a weight that is higher for samples from an underrepresented subgroup. Even though the above expression is fairly standard, choosing the proper weighting strategy is critical. If weights are set too high for a particular subgroup, it might degrade performance on the rest of the population.
Fairness constraints can also appear through training methods that specifically optimize for certain fairness metrics. This can involve adversarial techniques that try to remove sensitive attributes from the learned representations. One might, for instance, have an adversarial classifier that attempts to predict the sensitive attribute from the model’s latent space. By minimizing the adversarial classifier's accuracy, one encourages the main model to produce latent representations that do not contain sensitive information.
Post-processing Methods
After the model is trained, there are methods to alter predictions so that certain fairness metrics are satisfied. One approach, known as calibration-based post-processing, adjusts the decision threshold differently for different demographic groups. Another approach might alter the label outcomes so that the fraction of positive predictions is constrained to be equal or nearly equal across groups (satisfying a demographic parity goal). The main advantage of post-processing is that it can be simpler to implement since it does not require re-training the model. However, the disadvantage is that the underlying model might still hold biased representations, and post-processing can degrade overall predictive performance in certain contexts.
The post-processing method typically requires a separate validation procedure for each subgroup to find suitable thresholds or adjustments. If the subgroup is significantly underrepresented, ensuring robust threshold tuning might be challenging because fewer validation examples are available.
Ongoing Evaluation And Monitoring
Once steps are taken to address bias, it is essential to continually monitor fairness-related metrics to see if the intervention helps in practice. Re-collection of new data distributions or shifts in the input domain might cause the model to slip back into biased predictions. Ongoing evaluation often uses a dashboard that displays fairness metrics such as false positive rate, false negative rate, or mean average precision per subgroup in classification tasks. In a vision application, one might measure error rates like misclassification rate, bounding-box mismatch, or segmentation Intersection-over-Union for each group.
These fairness metrics help track where performance might degrade again. If that occurs, the pipeline can be updated with new data or refined approaches. Continual monitoring includes aspects such as drift detection, which checks if there is a distributional shift that significantly impacts certain subgroups. In production, it is often necessary to adopt automated retraining or reweighting procedures that incorporate newly gathered data from underperforming subgroups.
Practical Implementation Example
Here is a simplified snippet illustrating a reweighting approach in PyTorch for classification:
import torch
import torch.nn as nn
import torch.optim as optim
# Suppose inputs are images, labels are classes, and groups identify subgroups
# Let's assume 'groups' is a tensor specifying the subgroup for each sample
model = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3),
nn.ReLU(),
nn.Flatten(),
nn.Linear(16*some_width*some_height, 10) # example classes
)
criterion = nn.CrossEntropyLoss(reduction='none')
optimizer = optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 10
for epoch in range(num_epochs):
for images, labels, groups in dataloader:
outputs = model(images)
loss_per_sample = criterion(outputs, labels)
# Suppose we computed 'weights' offline or dynamically based on subgroup
# For instance, weights = freq_dict[group]^-1 / normalization_factor
# freq_dict is a dictionary with freq_dict[subgroup] = #samples in that subgroup
sample_weights = compute_sample_weights(groups)
weighted_loss = (loss_per_sample * sample_weights).mean()
optimizer.zero_grad()
weighted_loss.backward()
optimizer.step()
In this illustration, one might compute sample_weights in a manner that underrepresented subgroups have higher weights. Alternatively, if fairness constraints are employed, the loss might be augmented with an adversarial or fairness metric term.
Explainable And Transparent Reporting
It helps to provide stakeholders with interpretable metrics and a clear understanding of how the model’s decisions vary across different groups. Visualization techniques can help illustrate the difference in performance. In vision tasks, confusion matrices or specialized performance plots per subgroup can highlight persistent biases. By presenting these differences and the interventions taken, the system becomes more trustworthy and open to external scrutiny.
Fairness does not solely revolve around demographic parity. Depending on context, other fairness definitions such as equalized odds, equal opportunity, or calibration might be more relevant. A thorough approach to fairness is to analyze the application’s needs and choose the fairness definition that best aligns with the real-world implications of the model’s outputs.
Trade-Offs
There are inevitable trade-offs between overall performance, model complexity, and fairness constraints. Sometimes, implementing stricter fairness constraints can reduce the model’s overall accuracy. In many real scenarios, it may be acceptable to have a slightly lower aggregate accuracy if it improves accuracy or reduces error for historically disadvantaged groups. The relative weighting of these considerations depends on the use case, ethical guidelines, and compliance obligations. One also has to consider that some fairness definitions may compete with one another, making it impossible to satisfy all definitions simultaneously.
Maintaining ethical and regulatory compliance is crucial. Some jurisdictions require that automated decision systems meet certain interpretability or fairness standards. These constraints can influence which biases are prioritized for mitigation. One must ensure that the approach to addressing subgroup disparities does not inadvertently harm other protected categories or degrade overall fairness.
Addressing fairness involves continuous work. It is not a one-time fix. The model, the data, and the world evolve over time. Consistent auditing, re-collection of data, improvement of training processes, and robust post-processing checks are necessary to mitigate bias and ensure equitable outcomes.
How Do You Measure Fairness In Your Dataset?
Fairness measurement often depends on the scenario. In classification tasks, one might measure metrics like false positive rate or false negative rate across subgroups. If these metrics differ significantly between groups, that signals bias. Another approach is to check demographic parity, which examines the rate of positive predictions across subgroups. If one group receives a positive outcome significantly more often, that might be unfair unless justified by valid differences in the underlying data.
In vision-based tasks where the output is not a simple label but rather bounding boxes or segmentation masks, you might measure average precision or Intersection-over-Union separately for each subgroup. If a segmentation model systematically under-segments objects for a certain demographic group, it can indicate bias. These metrics can be computed by labeling or grouping your validation set based on demographic attributes, then calculating performance metrics separately for each group.
A potential pitfall is to focus on only one metric, such as overall accuracy. A high overall accuracy can mask poor subgroup performance if the underrepresented group constitutes a small fraction of the dataset.
If The Model Remains Biased After Reweighting, What Can Be Done?
If the model still exhibits bias after reweighting, there are multiple potential next steps. One possibility is that the model architecture or features used do not properly capture the nuances of the underrepresented group. This might require feature engineering, collecting more diverse data that covers varied attributes of that subgroup, or exploring advanced architectures that better generalize to minority groups.
More advanced techniques, such as adversarial debiasing, may be employed. In adversarial debiasing, there is a main network performing the primary prediction task while an adversarial network tries to identify the subgroup from the main network’s intermediate representations. By forcing the main network to produce representations that confuse the adversarial network, you reduce the risk of embedding sensitive attribute information. This can help reduce the gap in performance across subgroups.
One can also employ a multi-objective training setup that simultaneously optimizes accuracy and fairness. This might involve additional hyperparameter tuning to balance the emphasis on each objective. Sometimes, domain adaptation methods can be used if the underrepresented group is effectively treated as a different domain.
How Does One Choose Between Changing The Training Procedure Versus Using Post-Processing Methods?
Choosing between adjusting the training procedure or using post-processing often hinges on constraints like the difficulty of retraining, the scale of the dataset, and system requirements. If you have full control over training and can incorporate fairness objectives into the main loss function, training-based methods can directly reduce biased representations in the internal learned parameters. This is often preferable for deeply-rooted biases since it addresses them at their source.
If retraining is prohibitively expensive or time-consuming, or if the model is a black box from a third party, then post-processing can be an immediate solution. However, post-processing typically only modifies the final output distribution. If the model’s latent representations are heavily biased, post-processing might be less effective or result in a larger trade-off in accuracy.
It can also be beneficial to combine approaches. For instance, one might apply reweighting strategies during training and then do a threshold-based post-processing to fine-tune fairness metrics on certain subgroups.
How Do You Continue Monitoring Bias Once The System Is Deployed?
Deployment monitoring for bias is usually achieved by continuously collecting real-world data and evaluating performance by subgroup. One might set up a pipeline that periodically calculates fairness metrics on fresh incoming data. If the system sees a distribution shift—maybe a new demographic group starts using the service, or the characteristics of existing groups change—this can lead to changes in model performance. Automated alerts can trigger whenever certain disparity thresholds are exceeded.
If bias grows over time, it might require retraining with additional representative data or adjusting the hyperparameters in the fairness constraints. In real-world systems, compliance frameworks or internal governance policies might require documentation of bias monitoring processes, demonstrating how the model is tested over time. This fosters accountability and ensures an immediate response should subgroup performance metrics degrade.
Could Collecting More Representative Data Exacerbate Privacy Or Ethical Concerns?
Collecting more data about sensitive demographic attributes can present privacy risks. In some scenarios, you might need user consent to store demographic information. Even if users consent, storing sensitive data introduces additional responsibilities to protect that data from breaches and to comply with regulations. Organizations often face a paradox: to address bias, they need to analyze performance across sensitive attributes, but storing those attributes can raise ethical and legal questions.
De-identification procedures or secure multi-party computation can help mitigate privacy issues. Another approach is to store the attributes in an encrypted form or use them for model-building in an ephemeral way, without permanently retaining them. It is crucial to comply with local regulations such as GDPR or relevant data protection laws.
How Might You Handle Intersectional Bias?
Intersectional bias refers to performance disparities that appear at the intersection of multiple protected attributes. For example, the model might perform poorly for a particular ethnicity combined with a certain age range. Approaches here generally parallel single-attribute bias mitigation, but the complexity grows because one must analyze (and collect sufficient data for) multiple subgroups across multiple attributes.
Challenges arise when sample sizes become extremely small for certain intersections. Reweighting or constraint-based approaches can become difficult if you do not have enough data to obtain reliable estimates of performance at each intersection. Targeted data augmentation strategies that focus on certain intersectional groups can help. If it is feasible, active learning can also be used to specifically seek out new data from underrepresented intersectional groups.
What If You Cannot Collect Sensitive Attributes Due To Regulatory Constraints?
Sometimes, the model cannot directly access or store sensitive attributes. One technique in such scenarios is to infer probable sensitive attributes indirectly, though this in itself can create potential ethical and legal dilemmas. Another option is to use proxy variables or rely on approximate group membership. But if direct sensitive attribute data is truly unavailable, you may end up performing “fairness through unawareness,” which can be insufficient since many biases can creep in through correlated features.
There are methods, however, that try to reduce representation of any single latent attribute in a learned model. An example is to include an adversarial classifier for any attribute that might correlate with a protected feature. This approach is less effective if you cannot even approximate sensitive attributes, but it can still limit how strongly certain features are represented in the latent space.
Without any way to track performance across subgroups, it is challenging to verify that the model remains fair. From a regulatory perspective, if you cannot gather the data for protected groups, ensuring fairness might require other policy or process-based mitigations outside purely technical solutions.
How Do You Decide Which Fairness Metrics To Optimize?
The choice of fairness metric depends on the application context and the ethical or regulatory constraints. In some cases, focusing on equal false positive rates across groups might be important (for example, a system that flags images for further scrutiny in security contexts). In other cases, ensuring that each group has a similar true positive rate might be a priority. If your system is used for tasks like job hiring or academic admissions, you might need to ensure that each group has similar acceptance rates, aligning with demographic parity.
There is rarely a single metric that captures all dimensions of fairness. Different metrics can conflict. By working with domain experts and considering real-world implications of false positives and false negatives, you can choose metrics that reflect stakeholder concerns. You can also consider multi-objective optimization where you try to maintain performance while satisfying fairness constraints within acceptable margins.
In Practice, Is It Always Desirable To Have Perfect Parity Between Groups?
Perfect parity is often an ideal but can be impractical or even undesirable in certain settings. Real-world differences in data distribution, prevalence of labels, or legitimate subgroup differences can make perfect parity infeasible or counterproductive. For instance, in certain medical diagnostic applications, certain conditions might genuinely be more prevalent in one demographic group. Adjusting the model to produce the same positive rate across all groups might degrade clinical utility.
Designing fairness constraints should be done in consultation with domain experts who can clarify where group differences reflect underlying realities and where they reflect historical disadvantages. Balancing these considerations can be difficult and might require iterative experimentation and stakeholder input.
How Can Adversarial Approaches Help In Reducing Bias?
Adversarial approaches typically involve a main model trained to predict the target task while an adversarial component tries to predict the sensitive attribute from the model’s internal representations. The main network aims to minimize the target loss while also minimizing the adversary’s ability to predict the sensitive attribute. This forces the network to remove or obscure sensitive attribute information in the latent space. The training loop might look something like this:
# Pseudocode sketch
model_output = main_model(x)
adv_input = some_intermediate_representation # e.g., model_output or a hidden layer
sensitive_pred = adversary(adv_input)
main_loss = classification_loss(model_output, y)
adv_loss = adversarial_loss(sensitive_pred, s) # s is sensitive attribute
# Combine them in a way that the main network tries to minimize main_loss + alpha * ( - adv_loss )
# while the adversary tries to minimize adv_loss
If the adversary becomes very good at predicting the sensitive attribute, it means the main network’s representations still embed too much sensitive information. If the adversary can only do no better than random guessing, then the main network’s representations are likely uninformative with respect to the sensitive attribute, potentially reducing biases arising from that attribute.
How Would You Evaluate Whether Fairness Interventions Are Hurting Overall Accuracy?
One of the biggest concerns is whether mitigating bias reduces accuracy for the majority group. To evaluate this, you can monitor standard performance metrics across the entire population as well as subgroup-specific metrics. Compare them before and after applying fairness interventions. If the overall metrics drop substantially, it might indicate a need to reconsider how aggressively you impose fairness constraints or reweighting. In many production contexts, a slight loss in overall performance is considered acceptable if it significantly improves performance for historically underrepresented subgroups.
In practice, you might create a Pareto curve of fairness vs. accuracy. For example, one axis could be disparity in false positive rates, and the other axis overall accuracy. Different training or post-processing hyperparameters produce different trade-off points. Stakeholders can then decide which balance of fairness vs. accuracy is acceptable.
What Are Some Potential Real-World Consequences If These Fairness Interventions Are Not Addressed Properly?
Ignoring fairness issues can cause serious reputational damage, ethical harm, and even legal ramifications if the system makes discriminatory decisions. In computer vision, a facial recognition system that incorrectly identifies or fails to recognize individuals from a particular demographic group can lead to false arrests, denial of access, or other critical mistakes with significant societal implications.
On a practical business level, biased systems can lead to loss of trust and potential lawsuits if protected subgroups face systematic disadvantages. Public sector use cases like law enforcement or social services have stringent requirements to ensure equitable treatment of all citizens. Failure to address bias can also lead to the inability to deploy or scale the technology in regulated industries.
In addition, from a purely technical perspective, any form of bias often indicates inadequate representation of important features or patterns in the dataset. This can negatively impact the model’s overall robustness. If the environment changes or if more data from the underrepresented group starts to appear, the model may fail to adapt well.
How Do You Handle Situations Where Different Fairness Definitions And Stakeholder Priorities Conflict?
Conflicting definitions of fairness or stakeholder priorities can occur. Some stakeholders may insist on equal false positive rates, while others may focus on equal false negative rates or acceptance rates. A typical process for resolving these conflicts involves meeting with domain experts, ethicists, legal advisors, and affected community representatives. The negotiation often includes analyzing the operational impacts of each fairness criterion and discussing acceptable trade-offs.
One strategy is to iteratively experiment with various fairness constraints, measure the outcomes, and then present these results to stakeholders. Explaining the trade-offs with transparent data can help them converge on a compromise. This ensures everyone understands the potential consequences. In high-stakes domains, external regulatory or legal requirements might also override internal preferences.
If You Resolve Bias In One Subgroup, Could That Introduce Bias Against Another Subgroup?
In a multi-subgroup world, focusing on one subgroup sometimes inadvertently leads to performance degradation or new biases for other subgroups. This highlights the importance of evaluating fairness metrics across all relevant subgroups and not only focusing on a single protected class. Intersectionality complicates this further because a model fix targeted at one intersection might harm another intersection that was not originally scrutinized.
Continuous, holistic evaluation of fairness metrics is essential to prevent this phenomenon. If your fairness constraints or reweighting approach only singled out one subgroup, it is prudent to expand the approach to consider multiple subgroups simultaneously. This might mean you adopt a multi-group fairness objective or an intersectional fairness objective from the outset.
How Do You Decide Which Fairness Constraints Are Legally Required?
In some jurisdictions, there are specific guidelines or laws. Certain countries impose guidelines on automated decision-making that require equality of opportunity across gender or race. Others have narrower or broader regulatory frameworks that require clarity on data usage. Working with legal teams to interpret these regulations is crucial. Where regulations do not specify exact fairness metrics, you might adopt widely recognized industry best practices to ensure compliance.
Complex regulatory environments can necessitate specialized compliance features, such as logging each inference result with an audit trail. Data retention policies might specify how long sensitive data can be stored. In certain highly regulated industries like finance or healthcare, fairness can be mandated in ways that require frequent external auditing or certification.
The choice of constraints can also come from ethical guidelines or from the overall organizational mission that aims to reduce discrimination. This might go beyond legal minimum requirements and reflect corporate values or broader social responsibility objectives.
Can You Give An Example Of Post-Processing To Adjust Decision Thresholds For Subgroups?
A practical example of threshold adjustment would be a scenario where a binary classifier outputs a probability for each sample. Suppose you have two subgroups, A and B, and you notice that at a global threshold t, subgroup A has a very different false positive rate than subgroup B. One way to mitigate this is to set distinct thresholds tᵃ and tᵇ for each subgroup such that you align their false positive rates. Concretely, you might search for thresholds that ensure each subgroup’s false positive rate is the same. A toy example in Python:
import numpy as np
pred_probs = model(x_val)
subgroups = get_subgroups(x_val)
labels = get_labels(x_val)
# Suppose subgroups contain A or B for each sample
# We compute different operating points for each subgroup
for group in ['A', 'B']:
group_indices = [i for i, g in enumerate(subgroups) if g == group]
group_probs = pred_probs[group_indices]
group_labels = labels[group_indices]
# We tune threshold for group to achieve a desired false positive rate
best_threshold = find_threshold_for_desired_fpr(group_probs, group_labels, desired_fpr=0.1)
# Then we store it in a dictionary
group_thresholds[group] = best_threshold
def custom_post_process(prob, group):
return 1 if prob >= group_thresholds[group] else 0
This approach ensures each group has an aligned false positive rate (or any target fairness metric you choose to standardize by threshold adjustment). However, it might lead to different acceptance rates across subgroups or other unintended consequences. This is why it is necessary to evaluate multiple metrics, not just the one used for threshold selection.
Below are additional follow-up questions
How would you deal with label noise that disproportionately affects certain subgroups?
Label noise can exacerbate fairness issues if mislabeling is more frequent or systematic for specific subgroups. This could happen when annotators lack familiarity or cultural context, or when automated labeling tools do not generalize well to certain populations. If a subgroup’s labels are inconsistently or incorrectly assigned, the model will train on flawed examples, ultimately reducing performance disproportionately for that subgroup.
To address this:
Data auditing and cleaning: Conduct a detailed audit of data specifically for the subgroup in question. If label noise is discovered, implement more stringent quality checks or rely on multiple annotators for verification. Cross-check label consistency across overlapping subsets of data.
Active re-labeling: Focus re-labeling efforts primarily on the subgroup where label noise is suspected to be highest. Active learning methods can flag uncertain or inconsistent labels for human review.
Robust training techniques: Models designed to handle label noise (e.g., noise-robust loss functions) can help reduce the impact of erroneous labels. For example, approaches that estimate a noise transition matrix or implement bootstrapping can down-weight highly uncertain labels.
Validation set checks: Maintain a curated, high-quality validation set that accurately represents each subgroup and is carefully verified to be free of label noise. Continuously monitor performance on this set to catch discrepancies.
A subtle pitfall is that if only a small proportion of the dataset belongs to the subgroup, label noise corrections might be too minor to significantly shift overall metrics. Thus, focusing on the subgroup alone might lead to minimal changes in aggregated performance. Nonetheless, the fairness gains for that subgroup can be pivotal.
What if the notion of “sensitive attribute” is itself controversial or context-dependent?
In some real-world cases, there can be disagreement about which attributes should be considered “sensitive.” Additionally, certain attributes might be sensitive in one context but not another. For instance, location data might be sensitive in a particular context (e.g., personal safety concerns) but innocuous in others.
Strategies:
Contextual analysis: Work with domain experts and stakeholders to understand the implications of each attribute in the given context. In some domains, certain attributes are legally protected (e.g., gender, race), while others might be ethically sensitive in specific cultural contexts (e.g., religion or political affiliation).
User feedback: In consumer-facing applications, collect user feedback or run focus groups to determine which attributes people are most concerned about. In some situations, user-driven definitions of sensitivity can be more aligned with the system’s practical impact.
Modular approach: Implement a flexible pipeline where potential sensitive attributes can be toggled in or out of the fairness analysis. This can be important in large organizations where multiple teams might have different definitions of what is sensitive, or where regulations evolve over time.
Continuous re-evaluation: Over time, the social and regulatory environment may change, making certain attributes newly recognized as sensitive or vice versa. Regularly re-evaluate which attributes need special handling.
An edge case arises when an attribute is highly correlated with a protected attribute but not explicitly recognized as sensitive. For instance, ZIP codes can correlate with race or socioeconomic status. Even if ZIP code is not deemed “sensitive,” it can still lead to bias. Hence, continuously monitoring model outcomes by relevant groupings is crucial.
How do you account for cultural biases in the data for an international model deployment?
When models are used across multiple regions, cultures, or languages, subtle biases may emerge because the data is dominated by one cultural context. For example, a vision model trained primarily on Western faces may have higher error on non-Western faces.
Possible solutions:
Localization of datasets: Collect culturally or regionally specific data to ensure each locale or demographic is equally represented. This can significantly improve the model’s ability to generalize across varied domains.
Domain adaptation: Use techniques that adapt a base model trained on one domain to another domain with limited labeled data. For instance, fine-tuning on a smaller subset of region-specific data can address cultural nuances.
Translation and annotation: In text-based models, ensuring that translation quality and annotation guidelines are consistent is critical. Cultural context might influence word usage or sentiment in ways that do not directly translate.
Ethnographic audits: Employ domain experts or local communities who can flag data attributes or patterns that might be misinterpreted by the model.
A subtle point is deciding how to unify fairness metrics across drastically different cultural contexts. One society might prioritize equalized false positive rates, whereas another might focus on overall coverage or accuracy. Balancing conflicting norms is an ongoing challenge that often requires region-specific approaches.
In a multi-label classification setting, how do you ensure fairness when multiple labels might correlate with a protected attribute?
In multi-label tasks (e.g., tagging images with multiple attributes), certain tags might be more frequent or relevant for certain demographics. Standard fairness measures for single-label tasks do not directly translate to multi-label situations because each instance can have multiple true labels.
Strategies:
Label-specific subgroup analyses: Evaluate fairness metrics separately for each label-subgroup combination. For instance, if you are predicting different attributes (like “smiling,” “wearing glasses,” “wearing hat”), check how often each label is correctly predicted across each demographic group.
Per-label reweighting: Extend typical reweighting or constraint-based methods to handle each label individually. This can be complex because you must account for label correlations. If you correct one label’s bias, it could introduce or leave unaddressed bias in another.
Hierarchical fairness: If labels are hierarchical or correlated, define fairness at multiple levels. For instance, ensuring fairness for overall detection of faces across subgroups, and then fairness for subsequent attributes within those detected faces.
Monitoring label co-occurrence: Some subgroups might be more likely to have certain label combinations. Failing to address these co-occurrences can lead to intersectional or multi-label bias. Regular data checks can highlight anomalies in label distributions.
One hidden challenge is that multi-label tasks can have incomplete labels—some true labels might be missing. If incomplete labeling is systematically worse for certain subgroups, that leads to even more skewed distributions.
How does transfer learning impact bias, especially when the pre-trained model is trained on a large but non-representative dataset?
Many state-of-the-art vision or language models come from large pre-trained networks. These networks might be trained on large datasets that historically have been skewed (e.g., predominantly English text, or specific geographies for images). When you fine-tune such a model on your own data, the biases learned in the pre-training phase may persist.
Approaches to mitigate:
Pre-training data auditing: Scrutinize the composition of the base model’s training data. Although it can be massive, even partial analysis can reveal severe skews (e.g., underrepresentation of certain languages or dialects).
Domain adaptation with fairness constraints: Incorporate fairness constraints when adapting the pre-trained model to your target data. For instance, apply adversarial debiasing or reweighting that acknowledges the base model’s existing skew.
Debiasing techniques on embeddings: If the transfer learning approach uses fixed embeddings (e.g., language embeddings), you can apply debiasing procedures on those embeddings. For instance, in word embeddings, techniques exist to remove gender or racial stereotypes from vector representations.
Post-hoc analyses: After transfer learning, systematically evaluate whether the model’s biases were reduced or remain intact. Fine-tuning alone does not guarantee the elimination of pre-training bias.
A subtle pitfall is over-reliance on large pre-trained models without verifying their biases against underrepresented subgroups. Because these models are widely adopted, biases can become entrenched if not proactively addressed.
How can one handle a scenario where mitigating bias for a certain subgroup might conflict with compliance or operational constraints?
Sometimes, domain rules or regulations might restrict certain forms of data manipulation. For instance, in finance, you might be legally constrained from changing certain interest rates post-processing to maintain “fairness.” Or in healthcare, guidelines may prohibit the use of protected attributes in model training even if it could improve fairness.
Ways to navigate:
Legal counsel and compliance: Engage legal and compliance experts to understand the permissible range of interventions. There might be specific frameworks that delineate how fairness can be pursued without violating regulations.
Technical and policy synergy: Explore solutions that require minimal direct manipulation of outcomes. For example, you might apply data-level interventions or choose modeling strategies that do not explicitly rely on or reveal protected attributes.
Regular audits and documentation: Document every attempt at bias mitigation and align it with compliance requirements. This demonstrates due diligence and can clarify which interventions are permissible.
Creative re-framing: In some cases, you can incorporate fairness constraints indirectly via robust design or domain-specific features that approximate relevant fairness aspects. For example, if direct usage of a protected attribute is disallowed, you might use a carefully curated feature that partially captures the relevant context without directly revealing the attribute.
The risk here is that a well-intentioned fairness fix might be deemed non-compliant. If so, you might need alternative solutions—like collecting separate data or shifting to a different modeling paradigm.
How would you address “template bias” in a vision system where certain backgrounds or settings are overrepresented for one subgroup?
Template bias refers to scenarios where a model sees recurring backgrounds or environmental contexts that coincide with a demographic group. For instance, if images of one group mostly appear in indoor lighting conditions and another group mostly in outdoor conditions, the model’s performance might degrade whenever the typical context is missing.
Potential approaches:
Contextual data augmentation: Synthetically alter backgrounds or lighting conditions for each subgroup to expand coverage. For instance, place images of individuals from the underrepresented group in varied scenes, ensuring the model sees them in multiple contexts.
Stratified sampling: Carefully ensure that the training dataset has balanced distributions of background settings across subgroups. This might require oversampling certain subgroup-context combinations.
Context disentanglement: If feasible, design the model architecture to separate person-centric features from background features. This can help reduce overfitting to the environment. For example, use multi-stream networks that handle foreground (person) and background (context) differently.
Fine-grained error analysis: Investigate if the misclassification is truly about the subgroup’s physical attributes or about the environments associated with them. This can guide data collection efforts more precisely.
The tricky part is ensuring the augmented images are both realistic and ethically valid. Overly manipulated images might introduce visual artifacts or unrealistic scenarios, which can mislead the model or degrade performance.
How do you handle fairness across time when user demographics or data distributions change?
Data drift can occur when the proportion of subgroups changes or new subgroups emerge. A system might have been fair at launch but drifts away from fairness over time.
Recommendations:
Scheduled retraining: Periodically retrain the model using recent data that reflects the current demographic distribution. If a new subgroup emerges, specifically incorporate that data.
Online learning or incremental updates: In streaming scenarios, incorporate new samples continuously. Fairness constraints can be imposed in an online fashion, adjusting model parameters as distributions shift.
Dynamic weighting: Over time, reweight data from newly emerging or previously underrepresented subgroups to ensure ongoing coverage. This method needs to be balanced so that older data is not completely discarded if it still represents part of the user base.
Monitoring drift: Implement drift detection algorithms that flag shifts in the distribution of inputs or subgroup membership. Once drift is detected, a re-evaluation of fairness metrics should follow.
A subtle corner case arises if historical data becomes stale or no longer relevant for new subgroups. The system might remain accurate for older subgroups but lose accuracy for novel patterns. Continual fairness checks ensure no subgroup is neglected as distributions evolve.
How can you handle real-time fairness checks in high-throughput systems?
In large-scale or real-time systems (such as content filtering or streaming recommendations), explicit fairness checks on every single inference might be computationally expensive or operationally infeasible.
Options include:
Batched subgroup sampling: Periodically sample user interactions and assign them to subgroups for evaluation, rather than checking fairness in real-time for every request.
Approximate metrics: Use approximate methods or hashing-based approaches to group users by sensitive attributes (if known) or proxy attributes. Then compute fairness metrics on aggregated intervals (e.g., hourly or daily).
Caching and thresholding: If certain fairness indicators (e.g., false positive rates) remain stable over short intervals, you might run a fairness evaluation less frequently. Only when anomalies are detected do you perform deeper analysis.
Parallel pipelines: Maintain a parallel validation pipeline that closely tracks real-time traffic. This pipeline might not be used for the live model output but can run continuous checks to update dashboards. If a bias threshold is crossed, the system can trigger an alert or fallback strategy.
An edge case is that some subgroups might not appear frequently enough to get reliable statistics in small time windows. A solution is to apply rolling or cumulative metrics to gather enough data for stable measurement.
What do you do if a fairness metric improves in your offline tests but real-world user complaints about bias persist?
Discrepancies can arise between offline metrics and real-world experiences for numerous reasons. Perhaps offline metrics do not capture nuanced forms of bias that users see. Or the real-world usage scenario differs from the distribution in your test sets.
Possible remedies:
User experience research: Engage directly with users or community groups to understand how the bias is surfacing in practical scenarios. Real-world biases can be more situational than purely algorithmic.
More granular metrics: Standard fairness metrics might be too coarse. Investigate scenario-specific issues—like how quickly content is recommended or how frequently certain groups see undesired outcomes.
A/B testing with fairness instrumentation: In some products, you can run controlled experiments that specifically track performance for subgroups. Compare the new fairness approach with the baseline model in a real environment.
Iterative feedback loop: If real users are reporting issues, incorporate their feedback into further data collection or model updates. This might require building feedback mechanisms directly into the interface.
A pitfall here is focusing on a single fairness definition. The mismatch with user experience could indicate an overlooked dimension of fairness—like interpretability or the specific context in which decisions are made.
How do you mitigate fairness issues in unsupervised or self-supervised learning scenarios?
In unsupervised or self-supervised settings, no explicit labels exist—making it harder to quantify performance disparities. Yet biases can still be learned from patterns in the data, such as which clusters or latent representations form around certain demographic groups.
Mitigation strategies:
Regular cluster analysis: If the model forms clusters, analyze them by subgroup membership. If one demographic group consistently clusters separately in a way that leads to negative outcomes (e.g., isolation from mainstream clusters), investigate the underlying features.
Fair representation learning: Adapt adversarial or reweighting concepts to representation learning. For example, train an embedding space that de-emphasizes the correlation between latent factors and sensitive attributes.
Synthetic validation tasks: Devise proxy tasks that help reveal potential bias. For instance, you could label a small subset of data with sensitive attributes and see if the unsupervised model’s features correlate too strongly with those attributes.
Post-hoc calibration: If the unsupervised model is later used in a downstream (semi-supervised or fully supervised) task, apply fairness checks at that downstream stage. This approach ensures that if the upstream representation is skewed, you might still correct for it in the final model.
A subtlety is that unsupervised methods typically do not track sensitive attributes by default, so you may need domain knowledge or extra annotation to evaluate potential biases.
When is it appropriate to include certain sensitive attributes in the model’s input features to improve fairness?
There is an ongoing debate about whether including protected attributes can help or hurt fairness. In some cases, having explicit knowledge of an attribute helps the model correct for it. In other cases, it could increase the risk of the model learning to rely on that attribute in an undesirable way.
Considerations:
Regulatory environment: In certain legal frameworks, using protected attributes (e.g., race) directly might be restricted or viewed negatively. However, there are contexts—like Affirmative Action—where the law explicitly allows or encourages factoring in certain attributes.
Technical approach: If your strategy is to incorporate fairness constraints (e.g., reweighting or adversarial training), having the sensitive attribute can be beneficial. For instance, adversarial training to remove sensitive information from latent representations depends on explicitly knowing that attribute.
Privacy and ethics: Storing or using sensitive attributes can raise privacy concerns. Thoroughly assess whether you have user consent or if you can anonymize or protect that attribute through secure protocols.
Empirical testing: Sometimes including the attribute can genuinely reduce errors for historically disadvantaged subgroups by letting the model learn offsetting patterns. Rigorous offline testing and real-world monitoring can reveal whether this approach reduces or exacerbates bias.
An edge case arises if a sensitive attribute is heavily correlated with performance: the model might incorrectly assume it is the most predictive feature. This can create ethical conflicts even if some overall fairness metrics improve.
Can fairness interventions reduce interpretability, and how do you balance both?
Some fairness interventions—especially complex ones like adversarial debiasing or multi-task objectives—can create complicated model architectures. As complexity grows, interpretability often suffers.
Potential resolutions:
Model distillation: After training a more complex “fair” model, distill it into a simpler or more interpretable model that approximates its decisions. This can retain some fairness properties while improving transparency.
Layer-wise interpretability: Use interpretability techniques (e.g., attention maps, feature importance) at various stages of the pipeline. If adversarial debiasing is used, examine how the representation changes as it moves through the adversarial layers.
Local explainability: Provide local instance-level explanations. Even if the overall architecture is complex, instance-level explanation methods (e.g., SHAP or LIME) can help users or auditors see how the model arrived at a particular output for that instance.
Human-centered design: If stakeholders need to understand the model’s decisions, incorporate domain experts in the design of interpretability modules. They can guide which aspects of the model are most important to visualize or clarify.
A subtle pitfall is that forcing interpretability might undermine some fairness techniques that rely on high-dimensional hidden representations. Conversely, pushing for strong fairness might reduce the utility of standard interpretability methods if they do not account for fairness constraints in their explanation logic.
What is a “fairness threshold” in practice, and how do you decide where it should be?
A fairness threshold is often a target or boundary for how much disparity you are willing to tolerate between different subgroups. For example, you might say your system’s false negative rate must not differ by more than a certain percentage across groups.
Establishing such thresholds:
Stakeholder input: Align the threshold with stakeholder perspectives, domain regulations, or user expectations. For example, if a certain difference in false negative rates is legally prohibited, that sets a maximum allowable gap.
Statistical significance: Ensure the difference you measure is statistically significant. If you are dealing with small subgroups, wide confidence intervals might make it hard to fix a tight threshold.
Historical context: If a subgroup has faced historical discrimination, you might adopt a stricter fairness threshold. This can accelerate the model’s improvement for that group.
Continuous calibration: The threshold can be dynamic, updated as new data arrives or if social norms and expectations shift.
One pitfall is setting an arbitrary threshold without domain context—like 5% difference in false negative rates—when actual acceptable levels might be more stringent or flexible. Another edge case is that a single threshold might not be uniformly effective across multiple metrics (e.g., false positive vs. false negative rates). You may need multiple thresholds or multi-metric acceptance criteria.
How do you communicate fairness intervention decisions to non-technical stakeholders?
Non-technical audiences—management, customers, or the general public—often require plain language explanations of how fairness is being addressed without diving too deeply into technical details.
Effective communication:
Narrative approach: Describe the problem the system faced, how it impacted certain groups, and what steps were taken to remedy it. Highlight real-world implications (e.g., improving access, reducing misclassification).
Visual summaries: Provide charts showing performance metrics (e.g., confusion matrices, error rates) broken down by subgroup. Show the improvement after fairness interventions.
Transparent disclaimers: Acknowledge any trade-offs or limitations. If the fairness fix lowered overall accuracy slightly, explain why it was deemed acceptable.
Concrete examples: Demonstrate how the system improved for a typical user from the underrepresented subgroup. This can be more persuasive than abstract statistics alone.
Compliance framing: Emphasize that the approach aligns with regulatory requirements or ethical guidelines, providing reassurance that fairness is not just a technical afterthought.
A potential pitfall is oversimplifying the complexities of fairness, leading non-technical stakeholders to assume the model is now “fully fair” with no ongoing monitoring needed. Stressing the iterative nature of fairness can help maintain realistic expectations.
How do you handle dynamic subgroup definitions, where subgroups may split or merge over time?
In some contexts, what constitutes a subgroup can evolve. For example, a new demographic might emerge, or two existing subgroups might be merged based on changing data recording practices. If you baked in a certain grouping logic, the model’s fairness checks might become obsolete.
Techniques to manage this:
Flexible schema: Use data structures that allow for dynamic addition or merging of subgroup labels. Avoid hard-coding specific group categories in the training or evaluation pipeline.
Clustering plus labeling: Instead of having fixed subgroups, you could cluster the dataset periodically to discover emergent sub-populations. You can then label these new clusters for fairness checks if they correspond to real-world demographics.
Adaptive metrics: If new groups form, recalculate the fairness metrics to include those groups. This might require new weighting or constraint parameters in the training loop.
Continuous stakeholder engagement: Domain experts or user communities often best understand how subgroups are evolving in the real world. Engage them to define new subgroups or retire outdated ones.
An edge case occurs if the new subgroup has extremely small sample sizes. The fairness approach might produce large statistical variability. In such cases, specialized data collection or synthetic data generation might be needed to ensure stable performance measurements.
How can hierarchical or multi-level attributes complicate fairness (e.g., broad categories like “Asian,” which breaks down into many nationalities)?
In real datasets, attributes can be hierarchical. Treating “Asian” as a single subgroup might mask differences among distinct national or ethnic backgrounds. Fairness metrics could appear fine overall while certain subpopulations remain underserved.
Addressing multi-level attributes:
Granular labeling: If data is available, break down the broad category into its more specific subcategories (e.g., Chinese, Indian, Filipino). Evaluate fairness metrics at multiple granularities.
Hierarchical constraints: Some fairness frameworks allow hierarchical definitions of subgroups. You can aim for fairness at the highest level (e.g., “Asian” vs. “Non-Asian”) while also tracking fairness among subgroups within “Asian.”
Data sufficiency checks: In practice, many subgroups within a broad category might have too few samples for robust statistical estimates. If certain sub-subgroups are still large enough, targeted data collection or augmentation can help.
Intersection with other attributes: Multiple hierarchical attributes (e.g., geographical region + socio-economic status) can lead to extremely small intersectional groups. This complicates standard reweighting or constraint-based methods.
A potential pitfall is jumping to broad categories for simplicity, which can lead to incomplete solutions. Stakeholders from an underrepresented sub-subgroup might still encounter bias if they are lumped together with a broader category that does not reflect their reality.
How do you handle fairness in recommendation systems where historical feedback loops can embed prior discrimination?
Recommendation systems (e.g., product recommendations, social feed algorithms) often rely on historical user interactions. If a subgroup historically received fewer or lower-quality recommendations, the model might perpetuate that pattern.
Mitigation strategies:
Exploratory or randomization strategies: Incorporate exploration so that subgroups with limited historical data can still receive recommendations. This helps gather new data and break feedback loops.
Fairness-aware ranking: Use ranking algorithms that ensure each subgroup is sufficiently represented among top recommendations, balanced against user engagement metrics.
Counterfactual training: Simulate how the system would behave if certain subgroups had received different historical exposure. This can help correct for biased feedback loops in the training data.
Longitudinal analysis: Track user engagement and satisfaction over time to see if a particular subgroup’s outcomes improve or worsen. Without long-term tracking, short-term fairness fixes may not suffice.
A hidden challenge is that users might adapt their behavior in response to new recommendations, creating new feedback loops. Fairness strategies require iterative updates to keep pace with evolving user interactions.
In an ensemble model where different components are trained on different subsets or tasks, how do you ensure overall fairness?
Ensemble methods combine multiple models (e.g., bagging, boosting, or mixture-of-experts). Each component might have different biases. The final ensemble’s fairness depends on how these biases aggregate.
Techniques to address:
Fairness-constrained ensemble selection: If you are selecting a subset of models to include in the ensemble, pick combinations that balance overall accuracy and fairness metrics.
Diverse training data subsets: If each model in the ensemble is trained on a different data slice, ensure each slice is fairly representative of subgroups to avoid a specialized but biased model overshadowing others.
Weighted aggregation: Adjust ensemble weights based on each model’s subgroup performance. If a component performs poorly on a certain subgroup, reduce its influence on that subgroup’s predictions.
Adversarial gating networks: In mixture-of-experts models, a gating network decides which expert to invoke for a given input. You can train this gating network with fairness constraints so that it does not consistently send a particular subgroup’s inputs to a biased expert.
A subtlety is that an ensemble that looks fair in the aggregate might hide the fact that certain components are highly biased. This can matter if you must interpret or debug individual submodels. Additionally, interactions among ensemble components can introduce non-linear effects on fairness metrics.
How do you ensure that bias mitigations do not violate causal relationships that are genuinely important?
In some applications, certain attributes might causally affect outcomes (e.g., in healthcare, certain demographic factors might legitimately correlate with disease risk). Blinding the model to these factors or forcing equal outcomes could harm predictive utility or produce unethical results (like under-diagnosis for a group that is genuinely at higher risk).
Solutions:
Causal analysis: Use causal inference to differentiate between legitimate causal paths and spurious correlations. If a protected attribute is on a direct causal path to the outcome, removing it might degrade accuracy for that group.
Counterfactual fairness: Evaluate the model’s decisions under hypothetical scenarios where only the sensitive attribute changes, keeping other causal factors the same. If large outcome changes are observed, the model might be using the attribute in a way that is not justified by the causal structure.
Minimal necessary usage: If an attribute is causally relevant, ensure it is used only in the minimal sense needed for predictive accuracy. Avoid letting the model rely on correlated or downstream features that reintroduce indirect discrimination.
Domain input: Collaborate with domain experts (e.g., doctors in a healthcare context) to confirm whether certain attributes are medically relevant. This helps decide whether fairness constraints should be partial (limiting certain kinds of discrimination) or relaxed when a causal necessity exists.
A potential pitfall is ignoring the fact that the causal structure might vary across subgroups. A factor could be causal in one subgroup but not another. Detailed domain-specific analysis is often required to navigate these complexities.