
ML Interview Q Series: Monitoring Deployed ML Models: Tracking Performance, Drift, and System Health Post-Deployment.

📚 Browse the full ML Interview series here.
Monitoring Deployed Models: Once a model is deployed as a service, what would you monitor to ensure it’s performing well and remains healthy over time? *Include both model-specific metrics (prediction confidence distributions, error rates against ground truth when available, drift in input feature distributions) and system metrics (inference latency, throughput, memory/CPU usage). How would you set up alerts or dashboards for these?*
Model Performance often degrades over time due to evolving data distributions, changing user behavior, or concept drift. Additionally, the environment in which the model runs can shift—for example, system hardware might become overloaded. Hence, monitoring a deployed model involves observing both the model’s predictive performance metrics and a suite of system performance metrics. Capturing real-time or near real-time statistics, analyzing them, and triggering alerts when anomalies occur ensures that any performance degradation or system instability can be swiftly addressed.
Model-Specific Metrics
One key aspect of monitoring a deployed model is continually assessing how well its predictions align with business or user needs. This often involves careful tracking of error rates, confidence scores, drift, and downstream user feedback.
Prediction Confidence Distributions
Monitoring the distribution of predicted probabilities or scores can reveal shifts in model behavior. If confidence values begin clustering around extremes, or if a model that previously produced well-spread confidence scores now always outputs very high confidence, it might indicate overfitting to recent data or a systematic input anomaly. One approach is to keep a statistical baseline of how these confidence distributions looked shortly after deployment. Real-time or batch-based monitoring compares new distributions with the baseline.
Accuracy and Error Rates
When ground truth labels are accessible (fully or partially), measuring error rates is vital. For classification tasks, quantities like accuracy, precision, recall, or F1 can be logged. For regression tasks, metrics such as mean squared error or mean absolute error can be recorded. In some cases, ground truth might arrive with a delay (as in delayed labeling scenarios). The moment these labels become available, the model’s predictions made at inference time can be evaluated.
To illustrate, accuracy for classification can be represented in center-latex as:
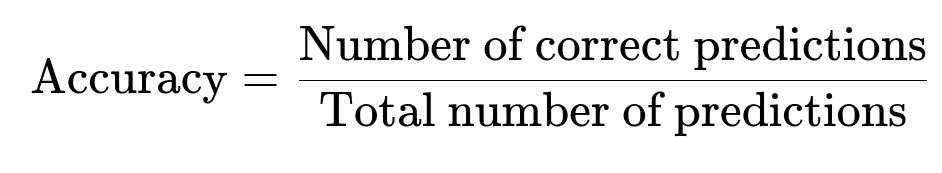
This expression can help anchor the concept that one must have predicted labels and the corresponding ground truths to evaluate the fraction of correct outcomes. Once a baseline accuracy is established, daily or hourly accuracy can be compared to ensure the model is not drifting from its expected performance.
Input Feature Distribution and Data Drift
Monitoring the distributions of input features is crucial to detect data drift. If the model was trained on data drawn from one statistical distribution but is now receiving data with different means or variance in key features, the model’s performance can degrade. Tools or frameworks that track distributional shifts in real-time (or in daily batches) can warn of potential drift. For instance, if the training set had an average of 10 for a particular feature, but the live data distribution starts averaging 20, then the model’s training assumptions might no longer hold.
Concept Drift
Concept drift occurs when the relationship between features and labels changes over time. For example, the meaning of certain events, user behaviors, or textual expressions might evolve in ways the model was never exposed to. This often requires additional monitoring logic, such as performance metrics that track segments of the data individually. Real-time drift detection strategies, or scheduled re-evaluations of the model on newly labeled data, can identify concept drift. Once discovered, a plan for retraining, fine-tuning, or collecting fresh data may be required.
System Metrics
A healthy production system hosting a machine learning model needs to meet performance and reliability service-level objectives (SLOs) or service-level agreements (SLAs). Observing these metrics allows for timely responses to prevent downtime or resource saturation.
Inference Latency
Inference latency measures how long it takes to generate a prediction once a request is received. Low latency is often critical for real-time applications. Monitoring the distribution of latencies (e.g., p50, p95, p99 latency) helps identify whether the system remains within acceptable response times. When latencies begin to spike, it could imply that servers are overloaded, the model has become too large for the allocated hardware, or other bottlenecks like network delays are occurring.
Throughput
Throughput refers to how many requests the system can serve in a given time window. A drop in throughput (or an inability to serve new requests) can indicate infrastructure constraints or concurrency issues. Tracking throughput over time also provides insight into traffic patterns, enabling capacity planning.
Memory and CPU Usage
Resource usage statistics should be tracked to avoid performance bottlenecks, OOM (out-of-memory) errors, or CPU saturation. If memory usage grows steadily over time, this can hint at memory leaks in the inference service. Similarly, if CPU usage continually approaches maximum capacity, it can degrade the model’s response latency and throughput.
Setting Up Alerts and Dashboards
Dashboards typically consolidate real-time metrics in easily interpretable visualizations. They are built using platforms like Grafana, Kibana, or custom UIs. Monitoring services like Prometheus can scrape model and system metrics, store them, and then define alert rules.
When setting up these dashboards:
A separate graph or chart for each metric category can facilitate quick identification of anomalies or correlation across metrics. For example, a sudden drop in accuracy might correlate with a spike in memory usage if the system is discarding requests or returning default predictions.
Alerts are triggers based on thresholds or anomaly-detection algorithms. For example, if accuracy drops below some baseline threshold for more than a specified time, or if inference latency’s 95th percentile surpasses an acceptable limit, an automated alert is sent via email, Slack, or pager systems. Advanced monitoring setups may use anomaly detection on the metric timeseries to account for day-night traffic patterns or cyclical changes. The system can compare incoming data to a historical rolling average plus tolerance bounds and only raise alerts if it detects unusual spikes or dips.
Code Example for Logging Metrics and Triggering Alerts
Below is a small illustrative Python snippet that shows how one might record metrics and push them to a monitoring backend. In practice, specialized libraries like Prometheus Python Client or StatsD might be used.
import time
import random
# Simulated function to get current accuracy or error rate from a monitoring script
def get_current_accuracy():
# Replace with actual computation from predictions vs. ground truth
return 0.95 + random.uniform(-0.01, 0.01)
def push_metric_to_monitoring_system(metric_name, value):
# This might use an HTTP request to push to a service like Prometheus, Graphite, etc.
print(f"Recording: {metric_name} -> {value}")
while True:
accuracy = get_current_accuracy()
push_metric_to_monitoring_system("model_accuracy", accuracy)
if accuracy < 0.90:
# Potential alert logic
print("ALERT: Model accuracy below threshold")
time.sleep(60) # Sleep for 1 minute
This is obviously simplified, but it demonstrates how a real monitoring loop might gather metrics in regular intervals, push them to a centralized store, and trigger an alert if thresholds are violated.
How to Interpret Spikes or Drops
If an alert triggers indicating a spike in error rate or a drop in accuracy, the immediate steps could include:
Checking whether the input data distribution has recently changed. Examining system logs to see if there is a memory, CPU, or disk bottleneck. Inspecting upstream data pipelines to ensure data is being generated and transmitted correctly. Investigating production changes: new code deployments, dependencies updates, or configuration changes.
Ensuring that these factors are systematically tracked allows for more rapid root-cause analysis.
Follow-up Question: What is the difference between data drift and concept drift, and how would you detect each in a live system?
Data drift refers to changes in the distribution of input features over time. Even if the meaning or relationship between those features and labels does not change, the model might see different ranges or statistical properties of the data than it was trained on. Concept drift specifically occurs when the underlying relationship between features and labels changes—meaning that even if the features look the same, they no longer map to the same ground truth labels in the way they did during training.
Detecting data drift can be done by monitoring the statistical properties of incoming features (mean, variance, histograms, etc.) and comparing them to training-time or recent baseline distributions. Some solutions use distance measures such as the Jensen-Shannon divergence or the Kolmogorov-Smirnov test to quantify the shift.
Detecting concept drift often necessitates checking performance metrics (accuracy, precision, recall) using newly available ground truth labels. If performance deteriorates while the input features’ distribution remains unchanged, that signals a possible concept drift. Additional methods involve building online drift detectors that continuously look for a drop in the consistency of predictions with known outcomes.
Follow-up Question: How do you handle scenarios where ground truth is delayed or only partially available?
Certain domains (like e-commerce fraud detection) might not get ground truth (fraud vs. non-fraud) until several weeks after the transaction. In this situation, metrics like accuracy or precision cannot be computed in real-time. Two major strategies help:
Short-term proxy metrics: If a partial or surrogate metric is available (e.g., a fraction of samples are manually labeled, or there is some weak label that arrives sooner), it can still detect major deviations.
Delayed evaluation: Once the real ground truth is available, batch re-evaluation is run on historical predictions. This yields a more accurate performance metric. Even though it is delayed, it still shows if a slow drift was happening over time.
Additionally, confidence distribution monitoring can be used as a real-time warning system. If the confidence distribution suddenly changes, that may prompt an investigation or partial manual labeling for verification.
Follow-up Question: What strategies exist for setting threshold-based vs. anomaly-based alerts? When should you prefer one over the other?
Threshold-based alerts are straightforward: if a metric crosses a specified boundary (for instance, accuracy < 0.90 or latency > 500ms), an alert is triggered. This approach is simple to implement but requires manually deciding on suitable thresholds. It may fail to capture subtle deviations if the chosen threshold is too lenient or may cause excessive false alarms if the threshold is too strict.
Anomaly-based alerts (using methods such as statistical process control or machine learning-based anomaly detectors) learn normal patterns in the metrics. They generate alerts when new observations deviate significantly from this normal pattern. This can be more sensitive to unusual behaviors and adapt to seasonality or trends in the data. However, anomaly-based alerts can sometimes be more complex to tune or interpret, and false positives might require additional overhead in investigating benign anomalies.
In practice, organizations often combine the two approaches, using well-understood thresholds for critical metrics (like total downtime or extremely low accuracy) while employing anomaly-based techniques for more complex or nuanced metrics.
Follow-up Question: If you see a sustained drop in model accuracy but your system metrics look fine, what might be the cause?
This situation often suggests that the model itself is encountering data or concept drift rather than a system resource issue. Possible causes include:
A shift in the incoming data distribution, where new data points differ from the training set. An evolution of user behavior that changes the meaning of certain features. Broken or changed upstream data pipelines that feed the model incomplete or malformed features. A sudden surge of edge cases (for example, unique seasonal data the model never saw in training).
Since system metrics (CPU, memory, network usage) remain normal, it is less likely that the hardware or infrastructure is at fault. The next step would be to check the input features more closely. Observing the distribution of these features or cross-referencing with domain experts can help confirm if the data has drifted.
Follow-up Question: How would you set up canary or shadow deployments for safe model rollouts?
A canary deployment involves deploying a new model version to a small percentage of the traffic while the existing model continues to serve the majority. This limited scope helps gather performance metrics in production without risking the entire user population. If the new model performs adequately based on your monitoring (accuracy, latency, user feedback), you gradually ramp up its traffic share.
A shadow deployment sends live traffic to both the current model and the new model, but the new model’s predictions are not returned to the user. Instead, they are logged for offline analysis. This approach prevents user experience issues if the new model is untested. The final step is to compare the performance of both models on the same real-world inputs. This is particularly useful if you want to track advanced or newly introduced metrics.
Follow-up Question: Could you discuss how you might integrate user feedback into a monitoring loop?
User feedback is a powerful indicator of real-world model performance. For example, in a recommendation system, users might explicitly or implicitly signal dissatisfaction by skipping or downvoting recommendations. Integrating such feedback can be done through:
Logging user actions as an additional performance signal. Surveying a subset of users to manually label whether predictions are correct or helpful. Analyzing behavior-based metrics like click-through rates, dwell times, or bounce rates.
When feedback is consistent and robust, thresholds can be set for alerting if negative feedback spikes or if engagement metrics drop significantly. This user feedback can supplement standard model metrics, especially in domains where ground truth labels are sparse or lagged.
Follow-up Question: What are some common pitfalls or edge cases when monitoring models in real-world deployments?
One pitfall is ignoring segments of data that might behave differently from the overall population. Monitoring only the global average accuracy could miss the fact that accuracy is deteriorating for certain subpopulations.
Another challenge is that monitoring can become excessively noisy if thresholds and anomaly detectors are not carefully tuned. Too many alerts can lead to “alert fatigue,” causing teams to miss the truly critical warnings.
Additionally, real data pipelines in production can break or produce partial data (e.g., null values for certain features). Without robust data validation and monitoring for these issues, the model might receive unexpected input distributions, potentially decreasing performance.
Insufficient logging can also hamper debugging. If important context about each inference request is not stored, diagnosing a drop in performance becomes difficult.
Finally, model version control and logging which model version served which request is essential for any root-cause analysis when multiple model variants coexist.
Follow-up Question: How often should models be retrained or recalibrated based on monitored metrics?
Retraining frequency depends on the rate of data change, the severity of any discovered drift, and the cost of frequent retraining. Some organizations might have a daily or weekly pipeline if the domain changes fast (e.g., real-time fraud detection). Others might only retrain quarterly when the domain is relatively stable.
A good practice is to define triggers based on monitored metrics: if error rates or drift indicators consistently exceed a threshold, an automated workflow can trigger a new training job. This approach combines the best of reactive measures (retrain upon performance drop) and proactive measures (periodic refresh of the model to incorporate new data).
Below are additional follow-up questions
How do you handle incremental data updates in continuous training pipelines for online learning scenarios?
Online learning involves updating a model in near real-time (or on a frequent schedule) with new data as it arrives. This is common in use cases such as user behavior prediction, recommendation systems, or fraud detection where the data distribution can change quickly.
To implement this in a production environment, you might:
Track Data Volumes and Velocity
If data arrives too quickly, ensure that the pipeline can handle the ingestion rates. Monitor the throughput of your data ingestion process.
Watch for spikes in incoming data—an unexpected batch of data arriving might overwhelm the system or distort the model if not handled properly (e.g., data from a single unusual event).
Validate New Data Before Incorporation
Monitor data integrity: Are feature distributions for each new batch consistent with historical patterns?
Flag anomalies in data format or missing feature values. If a large portion of new data contains invalid entries, incremental updates might degrade the model.
Set Up Incremental Training Schedules
You could update the model daily, hourly, or even in real-time, depending on how critical it is to capture the latest patterns.
Monitor performance metrics (like accuracy, precision, recall) on a rolling window of the latest data. If the model’s performance starts dropping before the next scheduled retrain, you might consider triggering an immediate retrain.
Pitfalls and Edge Cases
Overfitting to the most recent data, especially if certain short-term anomalies appear in the incoming streams.
In situations where the incoming data distribution momentarily deviates from the long-term average (e.g., a large short-term event), an online learning model might become biased.
Latency constraints in the training step—frequent retraining can be computationally expensive. Ensure you monitor resource utilization to avoid straining CPU, GPU, or memory.
In multi-model production environments, how do you measure overall system health across all models?
Many production systems deploy multiple models simultaneously. Some may handle different segments of traffic, or each model could address a different use case. Monitoring each model independently is often insufficient. Instead, combine those metrics to create a holistic view of system health.
Composite or Aggregated Metrics
You can create a weighted average of error rates across models, weighting by the traffic or criticality of each model.
Summaries of resource usage across all running models can reveal if the entire system is nearing capacity even if each individual model is within its own limits.
Unified Logging and Dashboards
A single dashboard that displays key performance indicators (KPIs) (e.g., accuracy, throughput, latency) for all models side by side.
Alerting rules can be more sophisticated: triggering an alert only if multiple models exhibit correlated anomalies suggests a platform-wide issue.
Pitfalls and Edge Cases
A single model spike in latency might not affect the overall system, but it could degrade user experience for that subset of traffic. Ensure that individual model-level metrics are still monitored and not drowned out by aggregate metrics.
If each model has a different business goal, combining metrics might obscure the significance of domain-specific KPI changes.
In a multi-tenant system, how would you separately monitor performance for each client if data distributions differ across tenants?
A multi-tenant system serves multiple customers or clients using the same model, but each tenant’s data distribution might be unique. A single global accuracy metric can miss tenant-specific degradation.
Tenant-Specific Slicing of Metrics
Partition predictions, confidence scores, and errors by tenant ID. This helps identify if the model underperforms specifically for one tenant.
Monitor memory/CPU usage in the context of tenant load. If certain tenants drive large traffic, you can track resources correlated with their usage.
Custom Thresholds per Tenant
Each tenant might have a different acceptable latency or performance target. Configure separate alert thresholds so that if tenant A experiences a severe drop in accuracy (but remains within an overall global threshold), you still detect it.
Pitfalls and Edge Cases
The data volume from some tenants may be small, making the metrics noisy or statistically unreliable.
Maintaining distinct dashboards for each tenant can become cumbersome as the number of tenants grows. Aggregation and prioritization strategies become essential.
What strategies can you use to debug mislabeled ground truth data in production, and how does it impact monitoring?
Mislabeled ground truth (e.g., incorrect or noisy labels) can degrade model performance metrics and lead to misleading monitoring results.
Identification of Potential Mislabeled Data
Analyze disagreements: If your model output consistently conflicts with certain ground truth labels, investigate potential label errors.
Use consensus from multiple models or crowd-sourced verification. If multiple strong models repeatedly disagree with the official label, it suggests label quality issues.
Impact on Monitoring Metrics
Error or accuracy metrics can be artificially inflated or deflated by poor label quality.
Drifts in performance might reflect changing labeling processes rather than actual model issues.
Pitfalls and Edge Cases
In some domains, the notion of “correct” label might be ambiguous. For instance, in subjective tasks (sentiment analysis on borderline text) or tasks with evolving criteria.
Automatic detection of mislabels can lead to incorrectly discarding data if the model is itself biased. Consider a second or third source of truth to confirm labeling accuracy.
How do you manage dependencies and third-party libraries that might affect performance or reliability?
A production ML system typically has multiple dependencies—databases, feature stores, message queues, or third-party APIs. If these dependencies fail, your model performance might drop even though your model code remains unchanged.
Dependency Health Checks
Implement synthetic queries or small-scale canary requests to third-party services to monitor response times and error rates.
Keep track of version changes in your dependencies. If the environment is containerized (e.g., Docker), pinned versions can provide consistency.
Resource and Integration Testing
Run integration tests before deployment to ensure your application logic and third-party dependencies remain compatible.
Perform load tests that mirror real-world concurrency, revealing performance bottlenecks in external APIs.
Pitfalls and Edge Cases
A dependency might silently degrade performance (e.g., a caching layer not invalidating properly, leading to outdated data).
Unexpected cost if a third-party service changes billing policies or usage limits.
How does a champion/challenger (or A/B testing) approach integrate with monitoring, and how is it managed in practice?
A champion/challenger strategy involves keeping the current “champion” model live for most traffic while a new “challenger” model runs on a smaller percentage of traffic or as a shadow. This approach helps safely evaluate newer models.
Routing and Comparison
The champion receives production traffic and continues to be the primary metrics reference.
The challenger runs in parallel, and its predictions are monitored side by side. If the challenger outperforms the champion on relevant metrics (accuracy, business KPIs), it can replace the champion.
Monitoring Differences
Maintain separate dashboards for champion vs. challenger. Compare key metrics such as error rates, latency, or user engagement.
A/B testing frameworks can automate statistical significance checks to see if the challenger’s observed performance improvement is robust or within margin of error.
Pitfalls and Edge Cases
Data segmentation errors (incorrectly routing certain users or sessions) can corrupt the A/B comparisons.
The champion might have built-in heuristics or post-processing steps that the challenger lacks, resulting in a skewed comparison if the new model is used raw.
How do you adapt your monitoring metrics when the business objective changes?
Over time, business requirements may shift—for instance, focusing on a new user segment or optimizing for different metrics (e.g., from click-through rate to user retention).
Updating Metric Definitions
Identify how the new business objective translates into measurable indicators. Perhaps you switch from pure accuracy to a weighted cost-sensitive error metric.
Remove or reduce the focus on outdated metrics if they no longer align with the objective.
Retrospective Analysis
Compare the historical data under the new metric definition to understand how the model would have performed in the past.
This helps you establish a baseline for the new objective.
Pitfalls and Edge Cases
Changing the objective might require a retraining process that yields a different model architecture. The new model’s performance can’t always be directly compared to the old objective.
Existing alert thresholds might no longer be valid, leading to false positives or missed problems.
How do you incorporate a controlled rollout for new hyperparameter settings in a continuous integration pipeline, and how do you detect suboptimal changes through monitoring?
Frequent hyperparameter tuning can automate the search for improved performance. But incorrectly tuned settings might degrade performance in production.
Automated Experimentation
Tools like Optuna or Ray Tune can run experiments offline on recent data.
Once a winning set of hyperparameters is found, they are moved into a staging environment or a small-scale production environment for further testing.
Monitoring in Staging
Mirror production data in a staging environment or run shadow traffic.
Evaluate metrics (latency, memory usage, accuracy, etc.) to confirm that the new hyperparameters work under real load.
Pitfalls and Edge Cases
Overfitting to a recent subset of data during hyperparameter tuning—only to discover that performance on a broader time window actually regresses.
Inadequate test coverage for large-scale concurrency, leading to suboptimal memory usage or timeouts when hyperparameter changes introduce a different model size or computational complexity.
When might you incorporate synthetic or backfilled data for testing reliability and performance in production, and how do you ensure it does not pollute real metric data?
Sometimes real data might be limited or lacks coverage for rare edge cases. Synthetic or backfilled historical data can help test how the system handles unusual scenarios.
Use Cases for Synthetic/Backfilled Data
Generating rare events (e.g., security breaches, high-value fraud cases) so the model’s edge-case behavior can be tested.
Stress testing and load testing: send large volumes of synthetic requests to measure system throughput limits.
Avoid Polluting Real Metrics
Tag synthetic requests with a special label or use separate endpoints. Then you can filter them out of production metrics dashboards.
Use separate clusters or staging environments to test with synthetic data. Keep the production environment for real traffic only, ensuring that aggregated metrics remain accurate.
Pitfalls and Edge Cases
Synthetic data might not perfectly match real-world complexities. Over-reliance on it can lead to false confidence in the model’s ability to generalize.
If synthetic data accidentally leaks into the main data pipeline, it may skew performance metrics, making the model appear more (or less) accurate than it truly is.
What issues arise from version control in model artifacts or data schemas, and how do you monitor and mitigate them?
Versioning is critical for reproducibility and rollback. Nonetheless, mismatch between model versions, data schemas, or feature extraction code can cause subtle production failures.
Model Artifacts Versioning
Use a consistent naming scheme or a dedicated artifact repository (e.g., MLflow, DVC).
Annotate each version with metadata: hyperparameters, training data timeframe, library dependencies.
Data Schema Control
Maintain a “contract” between the feature extraction pipeline and the model. If new features are added, older models might break.
Automated schema validation can detect new or removed columns in real time.
Monitoring Version-Related Issues
Track which model version serves each request. Log these version identifiers alongside request and inference results.
If performance suddenly changes, verifying which version caused the change is straightforward.
Pitfalls and Edge Cases
Production environment might not be fully updated with the new code for feature processing, leading to mismatches between the training-time features and real-time features.
Rolling back to an older model version but forgetting to revert the feature engineering pipeline can create silent but catastrophic mismatches (e.g., data shape changes that produce erroneous inputs).