
ML Interview Q Series: Network Path Reliability Analysis using the Inclusion-Exclusion Principle

Browse all the Probability Interview Questions here.
Consider a communication network with four nodes n₁, n₂, n₃ and n₄ and six directed links l₁ = (n₁, n₂), l₂ = (n₁, n₃), l₃ = (n₂, n₃), l₄ = (n₃, n₂), l₅ = (n₂, n₄) and l₆ = (n₃, n₄). A message must be sent from source node n₁ to destination node n₄. Each link lᵢ has probability pᵢ of functioning independently of the others. A path is considered functioning only if all its links function. Use the inclusion-exclusion principle to find the probability that there exists at least one functioning path from n₁ to n₄. Also simplify the result when pᵢ = p for all i.
Short Compact solution
By labeling the four distinct paths from n₁ to n₄ as: • Path 1: (l₁, l₅) • Path 2: (l₂, l₆) • Path 3: (l₁, l₃, l₆) • Path 4: (l₂, l₄, l₅)
and using the inclusion-exclusion formula on these path events A₁, A₂, A₃, A₄, the probability that at least one path is functioning is

When pᵢ = p for all i, it simplifies to
Comprehensive Explanation
Inclusion-Exclusion Principle for Probability of “At Least One Path Functions”
We define the events Aⱼ to be “Path j functions,” for j in {1, 2, 3, 4}. A path functions if and only if all of its links function. The probability that there is at least one functioning path from n₁ to n₄ is P(A₁ ∪ A₂ ∪ A₃ ∪ A₄).
To compute P(A₁ ∪ A₂ ∪ A₃ ∪ A₄), we apply the inclusion-exclusion principle:
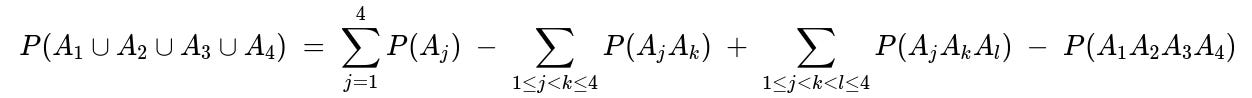
In words: • Add all single probabilities. • Subtract the probabilities of all pairwise intersections. • Add back the probabilities of all triple intersections. • Subtract the probability that all four occur together.
Computing Single-Path Probabilities
Each link lᵢ has probability pᵢ of functioning. If a path is composed of links lᵢ₁, lᵢ₂, …, then its probability of functioning is pᵢ₁ × pᵢ₂ × …. For the four paths we have:
A₁ corresponds to path (l₁, l₅). Probability(A₁) = p₁ p₅.
A₂ corresponds to path (l₂, l₆). Probability(A₂) = p₂ p₆.
A₃ corresponds to path (l₁, l₃, l₆). Probability(A₃) = p₁ p₃ p₆.
A₄ corresponds to path (l₂, l₄, l₅). Probability(A₄) = p₂ p₄ p₅.
Computing Pairwise, Triple, and Four-Way Intersections
AⱼAₖ means “Path j and Path k both function.” This can only happen if all links used in both paths simultaneously function.
Similarly for triple intersections AⱼAₖAₗ and the four-way intersection A₁A₂A₃A₄.
When we write out all these terms carefully and sum them up with the appropriate + and – signs from inclusion-exclusion, we arrive at
p₁p₅ + p₂p₆ + p₁p₃p₆ + p₂p₄p₅ minus all pairwise overlaps such as p₁p₂p₅p₆, p₁p₃p₅p₆, and so on plus or minus higher-order intersections (up to p₁p₂p₃p₄p₅p₆).
Collecting like terms, we get exactly:

This is the probability that at least one of the four paths is functioning.
Special Case: pᵢ = p for All i
When every link lᵢ has the same reliability p, we replace each pᵢ by p in the above expression. After factoring and simplifying, all identical terms with factors of p combine appropriately. The final simplified form is:

This expression is derived by systematically grouping terms to show how powers of p factor out from each summand.
Why Inclusion-Exclusion?
In many network-reliability or path-availability questions, directly counting “at least one path” can lead to overcounting intersections of events (where multiple paths might function simultaneously). Inclusion-exclusion is a systematic way to account for those overlaps correctly.
Potential Pitfalls
One common pitfall is to naively sum probabilities of path events without subtracting overlaps, leading to an overestimation of the probability. Another subtlety is to ensure that all paths are accounted for, especially in directed networks where loops or cross-links (like l₃ and l₄ connecting n₂ ↔ n₃) can complicate the analysis.
Practical Example with Code
In practice, if the number of paths is small, one could brute-force compute the probability by enumerating each subset of links that function. Below is a Python snippet that demonstrates enumeration for this small example:
import itertools
# Suppose p = [p1, p2, p3, p4, p5, p6]
def probability_of_some_path(p):
# Probability that a subset of links is up
# is product(p_i^1 * (1 - p_i)^0) for each link that is "up",
# times product((1 - p_i)^1 * p_i^0) for each link that is "down".
# We'll sum over all subsets that cause at least one path to work.
links = range(6) # indexes 0..5 correspond to p1..p6
total_prob = 0.0
# All possible states: 2^6
for state in itertools.product([0, 1], repeat=6):
# state[i] = 1 means link i is functioning, 0 means down
# compute the probability of this state
prob_state = 1.0
for i in links:
if state[i] == 1:
prob_state *= p[i]
else:
prob_state *= (1 - p[i])
# check if any path from n1->n4 is up
# path 1: l1, l5 -> indexes (0, 4)
# path 2: l2, l6 -> indexes (1, 5)
# path 3: l1, l3, l6 -> (0, 2, 5)
# path 4: l2, l4, l5 -> (1, 3, 4)
path1 = (state[0] == 1 and state[4] == 1)
path2 = (state[1] == 1 and state[5] == 1)
path3 = (state[0] == 1 and state[2] == 1 and state[5] == 1)
path4 = (state[1] == 1 and state[3] == 1 and state[4] == 1)
if path1 or path2 or path3 or path4:
total_prob += prob_state
return total_prob
This brute-force approach can confirm the derived algebraic expression for a given numeric set of probabilities.
Possible Follow-Up Questions
How does one deal with more complicated networks with many possible paths?
In larger networks, the principle is the same, but direct inclusion-exclusion quickly becomes unwieldy because of many overlaps. Often, techniques like minimal path sets, minimal cut sets, or specialized reliability polynomials are used. One might also rely on efficient algorithms or even Monte Carlo simulation for approximate solutions.
What if the links are not independent?
If the links’ functioning are correlated (for example, if l₃ is more likely to fail when l₁ fails), the simple product pᵢ × pⱼ × … would not be valid. We would need to incorporate the joint probability distribution of the link failures, and the algebraic approach would become more involved.
How do we ensure numerical stability in a real implementation?
When p is very close to 1 or 0, floating-point precision might cause errors in direct summation of small or large probabilities. Techniques like summation in log space can help maintain stability.
How would this generalize if different nodes had multiple links leaving them?
The same method applies: enumerate all distinct paths from the source to the destination, define each path event, and apply inclusion-exclusion. In practice, one often uses more advanced methods (like factoring out common link sets or applying cut-set expansions) to avoid summing over an exponential number of path events.
These details show how the inclusion-exclusion principle is both powerful and can be generalized. For small networks like the one in the question, we can handle the computations directly and verify correctness by brute force or by carefully enumerating all intersections.
Below are additional follow-up questions
How does the approach change if the network can have cycles that create infinitely many distinct paths?
When there are cycles in a directed network, it is theoretically possible for a path to loop around and then proceed to the destination, generating infinitely many simple path variants. From a reliability perspective, an “infinite number of paths” seems problematic. However, in practice, we usually focus on “simple paths” (i.e., paths that do not revisit nodes). A path that loops back to the same node multiple times typically does not contribute additional distinct routes in terms of reliability because it involves extra links that all need to be functioning simultaneously.
One common way to handle cycles is:
Identify all simple paths (those that visit each node at most once) using a depth-first search that tracks visited nodes.
Use these simple paths in an inclusion-exclusion approach.
Potential pitfalls or edge cases:
If the graph has complex cycles, enumerating all simple paths can still grow exponentially in the worst case. You might adopt more advanced algorithms, such as minimal path set generation, to avoid explicit enumeration of every path.
In real networks where loops can provide failover or alternative paths, the reliability might actually improve. But you must be cautious about double-counting path events if you try to consider every looped path.
Some networks allow repeated traversals of a node with incremental cost or risk, which may be relevant if each pass through a node or link increases chance of failure. In standard reliability theory, though, each link is typically considered independently and used once in a functioning route.
Is there a way to exploit minimal path sets or cut sets to handle large graphs more efficiently?
Yes. Instead of enumerating all possible paths, many reliability analyses use concepts like minimal path sets or minimal cut sets:
A minimal path set is a smallest collection of links that forms a functioning path from source to destination. “Smallest” means that removing any link from that subset would cause the path to fail. Once you have these minimal path sets, you can apply inclusion-exclusion to just those sets.
A minimal cut set is a smallest set of links whose failure disconnects the source from the destination. By enumerating these minimal cut sets, you can sometimes invert the problem and compute the system’s probability of failing to have a path.
Potential pitfalls or edge cases:
Identifying minimal path sets or cut sets can still be exponential in the worst case. However, in many practical network topologies, the total number of minimal path (or cut) sets is far smaller than the total number of paths.
Implementation details can be tricky. One must ensure that all minimal sets are found without duplicates and that partial or non-minimal sets are not included.
If dependencies exist among links (e.g., common-mode failures), the usual minimal path or cut set formulas need adjustment to account for correlated behaviors.
How do we handle situations where link probabilities are time-dependent or where link states can change over time?
When link probabilities vary over time, the concept of a single, static probability pᵢ for each link is no longer valid. Instead, you might have pᵢ(t), a function giving the link’s reliability at a specific time t. Analyzing the probability of a path functioning from t=0 to some deadline T then becomes a question of time-integrated or time-based reliability.
In such scenarios, approaches may include:
Markov processes: Model each link as a state machine (up or down) with transition rates, creating a continuous-time Markov chain for the entire network. You then compute the probability that the network is connected from node n₁ to node n₄ at or before time T.
Discretized intervals: Approximate the system’s state at discrete points in time and estimate the probability of path availability.
Potential pitfalls or edge cases:
The number of states in a Markov model grows exponentially with the number of links, so this can quickly become infeasible for large networks.
Correlations might increase if link failures are triggered by external events or if repair processes restore some links faster than others.
Simplistic approaches that assume independence at each time step can lead to unrealistic reliability calculations if actual data show strong correlations over time.
What if the cost or weight on each link matters, for example if we want the most reliable path rather than just any functioning path?
In many real-world scenarios, each link may have both a reliability probability and a cost metric (such as bandwidth, latency, or expense). Simply having any functioning path might not be sufficient; we often want the path with the highest end-to-end reliability or the lowest cost while meeting a reliability threshold.
Handling it typically requires:
A dynamic programming or graph search approach (like Dijkstra’s algorithm) where edges have “weight” related to reliability in a logarithmic form (because log(probability) transforms products into sums).
Alternatively, multi-objective optimization can be done if the problem is to maximize reliability and minimize cost.
Potential pitfalls or edge cases:
Converting probabilities to “costs” using log(1/pᵢ) can cause numerical issues if pᵢ is extremely close to 0 or 1.
Multi-objective optimization might yield a set of Pareto-optimal solutions rather than a single unique solution, so one must decide how to trade off reliability and cost.
If the network’s reliability must be computed across multiple potential paths simultaneously (like load balancing or multi-path routing), the analysis gets more complicated because multiple routes may share links and thereby share failure modes.
How does the reliability calculation change if each link can be in partial failure states (multi-state reliability) rather than just up or down?
In multi-state reliability models, each link can have several discrete performance levels (for instance, fully functional, partially functional with reduced capacity, or completely failed). The probability distribution then is over those states, not a single up/down variable.
To adapt inclusion-exclusion or path-based analysis, you must:
Define what it means for a link to “function” at a required level. For example, you may need a certain throughput or bandwidth threshold.
Translate partial states into an event “this link meets or exceeds the required performance.”
Potential pitfalls or edge cases:
If partial failures lead to different capacities, you might have to consider whether the entire path can carry the required data rate. This is more akin to a flow problem where each link state affects its capacity, and you need a minimum end-to-end flow.
The number of states and the complexity of the intersection events grows quickly. Simply enumerating states for each link and summing them might become intractable.
You might need advanced reliability or flow-based methods that incorporate multi-state edges, such as specialized network flow reliability techniques or Markov reward models.
Can we validate these reliability formulas with real data or empirical network measurements?
Yes, empirical validation is often crucial for confirming whether the theoretical model matches real-world behavior:
Collect link failure/availability logs over a period and estimate pᵢ from historical data.
Compare the theoretical formula’s predicted “probability of at least one functioning path” to the observed frequency of successful transmissions from n₁ to n₄.
Potential pitfalls or edge cases:
The assumption of link independence may not hold in practice (e.g., concurrent storms or power outages that affect multiple links).
Rare events can be hard to measure accurately in real data. A link that rarely fails might require an extremely long observation period to get a reliable failure rate estimate.
Network conditions often change over time (equipment upgrades, new routing policies, traffic patterns), so the historical data might not remain valid.
How do we extend this approach to scenarios where the network needs more than one path simultaneously?
If the requirement is that the network must have at least two distinct functioning paths (for instance, to ensure redundancy), then:
You redefine your target event to be “at least two disjoint paths exist that are both functioning at the same time.”
You might need to consider link-disjoint or node-disjoint paths, depending on whether a shared node or link violates the redundancy requirement.
Inclusion-exclusion then must be applied to events that represent “two or more disjoint paths function.”
Potential pitfalls or edge cases:
Counting disjoint paths that simultaneously function can be challenging, because some disjoint paths may overlap in certain nodes or links (depending on the definition of “disjoint”).
If partial overlap is allowed, you have to track exactly which links are shared. The problem complexity increases significantly.
In practice, a simpler approach might be to measure the reliability of each pair of disjoint paths using specialized algorithms (e.g., flow-based or minimal cut-based methods) rather than enumerating all path combinations.
What if the number of links or nodes is large but we still want an exact solution?
When the network scales up, enumerating all paths via inclusion-exclusion or even enumerating all minimal path sets can become computationally infeasible. Yet, sometimes an exact solution is still desired for mission-critical systems. Possible methods:
Use algebraic decomposition techniques, such as factoring out certain cut vertices or cut edges. This partitions the network into sub-networks.
Use symbolic reliability calculators or specialized graph decomposition algorithms that exploit repeated patterns in large networks.
Potential pitfalls or edge cases:
Decomposition approaches can miss certain cross-connections if the decomposition is not done carefully.
Symbolic methods might have worst-case exponential blow-up if the network does not have a structure amenable to factorization.
If exact solutions are too expensive, fallback methods like Monte Carlo simulation or bounding techniques (upper/lower bounds) are often used, but these might not provide exact results.
How can we incorporate repair rates or downtime into the reliability model?
In many real-world settings, links are not permanently failed once they go down; they can be repaired with some rate. This introduces a process over time rather than a static snapshot. Common approaches:
Continuous-time Markov chains: Each link is up or down, and repairs transition a down link to up.
Discrete-time availability models: A link’s availability is the fraction of time it is up in steady state, given some mean time to failure and mean time to repair.
Potential pitfalls or edge cases:
Building a Markov chain for the entire network can lead to a huge state space if each of the L links can be up or down independently (2^L states).
If repairs have significant correlations (e.g., shared maintenance crews or limited spare parts), independence assumptions break down.
In high-availability environments, it might be more relevant to measure metrics like “mean time to first path failure” or “probability that at least one path is up at a random point in time in steady state,” both of which require more specialized formulas.
What if the directionality or orientation of links can change over time (dynamic direction)?
Some advanced wireless networks or networks with directional antenna setups can “reverse” link direction based on conditions. If a link lᵢ can either be (nᵢ, nⱼ) or (nⱼ, nᵢ) depending on external factors, reliability must consider the probability distribution over which orientation is active, as well as whether it is functioning:
You might define states for each link that combine orientation and up/down status, each with its own probability.
Then the question “is there a functioning path from n₁ to n₄?” depends on the actual orientation and state distribution.
Potential pitfalls or edge cases:
The number of states per link doubles (up-left, up-right, down). If multiple links can reorient, states compound, complicating enumerations.
In real implementations, orientation changes might correlate with environmental conditions (like wind or interference), violating the independence assumption.
These additional scenarios highlight the many complexities that can arise when analyzing network reliability in real-world situations and how specialized methods or approximations are often required once you move beyond a simple, static, independent-link model.