
ML Interview Q Series: Powering TikTok's 'For You': Deep Learning for Candidate Generation and Ranking.

Browse all the Probability Interview Questions here.
1. Design the 'For You' page on TikTok.
Understanding the Core Objective of TikTok's 'For You' Page
The 'For You' page on TikTok is fundamentally about personalized content discovery. TikTok’s success rests on delivering short-form videos that users find engaging, so the system must:
Identify relevant videos for each user from a huge content pool. Rank these videos to ensure the user sees the most engaging content first. Continuously adapt and refine recommendations based on user interactions and changing content inventory.
A strong solution involves a candidate generation stage to filter the broad content set into a smaller set of potentially interesting videos, followed by a sophisticated ranking model that orders these candidates in a way that maximizes user satisfaction and long-term engagement.
Data Pipeline and Feature Representation
When building the 'For You' page, the recommendation process depends heavily on data. The system must continuously collect user-video interaction data and transform it into meaningful features that can feed into a machine learning model.
User-related features might include user demographics, watch history, content interaction history, temporal patterns, device and network attributes, and any explicit user preferences. Video-related features might include category or topic embeddings, textual or audio attributes, engagement metrics (likes, shares, comments), content age, and cluster-level features (e.g., the typical audience that engages with such content). Contextual features might include the time of day, day of the week, geolocation (if relevant), or recent viral trends.
Many real-world systems rely on embedding representations for both users and items. These embeddings are usually learned by a neural network that ingests user attributes, item attributes, and historical interaction signals.
For example, one might create an embedding vector that captures user interests gleaned from watch histories, or a fine-tuned language-based or video-based embedding for each piece of content. By aligning user and content embeddings in a shared latent space, you can quickly compute relevance scores.
Candidate Generation (Retrieval) Component
Because TikTok has a massive corpus of videos, the system typically splits the recommendation procedure into two steps: candidate generation (also known as retrieval) and ranking. Candidate generation retrieves a small subset (e.g., a few hundred) of videos from a potential pool of millions or billions.
One popular approach is to use approximate nearest neighbor search on embeddings. The user’s embedding (representing user preferences) is matched with item embeddings (representing videos). The top-N most similar item embeddings become the candidate set.
At large scale, this is often done using vector similarity search libraries or tools such as FAISS, ScaNN, or Annoy. The user embedding can be constructed in real-time based on the user’s short-term activity or a combination of short-term and long-term features. The item embeddings are typically precomputed or updated frequently based on a trained model. By restricting the candidate set to items whose embeddings are relatively close to the user embedding, we filter out most irrelevant content.
Ranking Component
After generating a manageable set of candidate videos, a more elaborate ranking model predicts how each candidate matches the user’s interest. This model typically considers features that are more expensive to compute or more elaborate to store. It outputs a score or probability that the user will engage (like, comment, watch fully, or share).
A frequent design pattern is to use a deep learning approach that combines user embedding, item embedding, and contextual features into a single multi-layer neural network. The model might output multiple signals—probability of watching to the end, probability of liking, probability of re-watching, and probability of sharing. These signals can then be combined into a single ranking score using business logic or a learned weighted combination.
Below is an illustrative (though simplified) example of how you might define such a ranking model in PyTorch:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TikTokRankingModel(nn.Module):
def __init__(self, user_dim, video_dim, hidden_dim):
super(TikTokRankingModel, self).__init__()
# Embedding transformations
self.user_embed_transform = nn.Linear(user_dim, hidden_dim)
self.video_embed_transform = nn.Linear(video_dim, hidden_dim)
# Combine user+video embeddings and context
self.fc1 = nn.Linear(hidden_dim*2, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
# Output layer for multiple engagement probabilities
self.fc_out_watch = nn.Linear(hidden_dim, 1)
self.fc_out_like = nn.Linear(hidden_dim, 1)
self.fc_out_share = nn.Linear(hidden_dim, 1)
def forward(self, user_embedding, video_embedding, context_vector):
# Transform embeddings
user_rep = F.relu(self.user_embed_transform(user_embedding))
video_rep = F.relu(self.video_embed_transform(video_embedding))
# Combine them
x = torch.cat([user_rep, video_rep], dim=1)
# Optionally incorporate context in a similar manner
# x = torch.cat([x, context_vector], dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
# Compute different engagement tasks
watch_prob = torch.sigmoid(self.fc_out_watch(x))
like_prob = torch.sigmoid(self.fc_out_like(x))
share_prob = torch.sigmoid(self.fc_out_share(x))
return watch_prob, like_prob, share_prob
The final ranking score might be a combination of these probabilities. You could, for example, define a composite function that emphasizes watch probability heavily, with smaller contributions from like and share probabilities. Alternatively, you can train a single output that directly optimizes an objective function capturing watch time, user satisfaction, or business metrics.
Below is a conceptual ranking formula:


Handling Cold Start for Users and Content
Systems must handle new users with little to no historical data, and new videos that haven’t accumulated engagement signals. For new users, the platform might rely on demographic data, device attributes, or short-term active signals (e.g., the first few videos they watch) to bootstrap the user embedding. For new videos, the system might rely on video-level signals like textual or audio embeddings and early watchers’ engagement patterns.
As users start interacting with content, the system quickly updates the user embedding or reweights the user representation, so the recommendations rapidly adapt. This is crucial for retaining new users and ensuring fresh content distribution.
Training and Evaluation
To train the ranking model, you might use historical interaction logs. For each user-video interaction, the training data can capture whether the user watched to completion, liked the video, shared it, commented on it, or scrolled away quickly.
A typical training scheme could be:
Construct training examples from historical logs. Use a binary or multi-label approach for different engagement signals. For instance, watch to completion could be one label, like is another label, share is another label, and so on. Minimize a weighted sum of cross-entropy losses or another differentiable loss function.
Offline evaluation usually relies on metrics like AUC, cross-entropy loss, or multi-class metrics that reflect how accurately the model predicts engagement. Online evaluation is performed using A/B tests on live traffic. Eventually, online metrics (watch time, user retention, dwell time) carry the most weight.
System Design Considerations for 'For You' Page
Real-time responsiveness is critical. TikTok must surface new videos quickly, keep track of ephemeral trends, and update the user’s recommended content rapidly when user taste shifts.
Scalability is essential since the system is expected to handle a large number of active users and a massive library of videos. This typically requires distributed systems for both data processing (e.g., streaming logs, feature computation) and for online inference (model serving, caching).
Fairness and diversity are increasingly important. The algorithm should not concentrate the distribution of views too heavily on a narrow set of creators or topics. Techniques like controlling item-level frequency capping, applying content diversification, or re-ranking to ensure a broad range of topics might be used.
Feedback loops and popularity bias are relevant issues. If the system only shows extremely popular content, it might overshadow niche or fresh content. A well-designed exploration strategy can be introduced to allow new or specialized videos to be tested with relevant user segments, balancing exploitation of known popular content with exploration of novel candidates.
User satisfaction and well-being also must be considered. For instance, regulators and users might demand transparency and control over recommended content. This can mean providing user settings to tune or filter recommendations, or applying guardrails to avoid harmful content.
How do we handle user embeddings for new users or those with sparse data?
When data is sparse, one can initialize the user with a demographic-based or interest-based prior. Basic ideas include:
Relying on device type, user-supplied age range, or geolocation. Even if these are broad, they can guide initial recommendations. Observing immediate short-term behavior. For the first session, track how the user interacts with a random or lightly personalized set of videos. Update the user embedding in real-time using these signals. Using a larger context of lookalike modeling. If new user u shares profile attributes or initial engagement patterns with existing users, you can infer that u might like similar content to those user clusters.
Pitfalls include incorrectly assuming a new user’s demographic or device-based preferences. Real-time recalibration can mitigate that. Ensuring the system is not slow or unresponsive during these updates is essential for retaining new users.
How do we incorporate additional signals like content quality or user community interests?
Systems can integrate auxiliary signals by learning new features or refining existing embeddings. For content quality:
Use a pretrained model (e.g., a transformer that analyzes text or an audio model that identifies music genres or speech) to embed the core content. Use engagement-based proxies, like dwell time, watch completion, and user feedback. High watch completion can imply content quality or at least strong user interest.
For user communities or micro-trends:
Add cluster-based features that tag each video or user with a label representing a sub-community or topic cluster. Track trending hashtags or audio tracks. If a user frequently engages with a particular cluster, use that as an additional feature in the ranking model.
An important pitfall is conflating overall content quality with ephemeral popularity. Sometimes a trending piece of content is not necessarily “high-quality” for all users. The ranking model must learn to weigh ephemeral signals appropriately while still capturing user interests.
How do we prevent echo chambers or filter bubbles?
To avoid overly narrowing recommendations:
Inject diversity in candidate generation. Instead of only retrieving content similar to the user’s recent watch history, include random samples or content from adjacent clusters. Apply re-ranking post-model inference. The system can ensure a certain coverage of different content categories or topics, especially if a user has broad interests. Monitor metrics such as watch time or user satisfaction specifically for diverse or novel content. This helps calibrate how aggressively to push new categories.
A subtle point is balancing user preferences with exploration. If you push too much random content, user satisfaction might drop. If you push too little, you risk filter bubbles and missing out on potentially interesting content outside the user’s explicit preference space.
How do we handle the real-time streaming and high traffic in production?
To handle large scale in real-time:
Use a streaming architecture (e.g., Kafka, Flink, Spark Streaming) to collect, preprocess, and update features continuously. Maintain separate services for candidate retrieval and final ranking. The candidate retrieval system might rely on approximate nearest neighbor search in high-dimensional embeddings. The ranking layer could be a high-throughput, low-latency model inference service (e.g., TensorFlow Serving, PyTorch Serve, or a custom C++ inference engine). Cache partial results. For instance, user embeddings can be cached for short durations if they do not change significantly in real-time. Similarly, frequent or popular videos’ embeddings can be stored in memory.
Pitfalls arise if you do not manage caching carefully. Serving stale user embeddings or outdated trending signals can degrade user experience. The system must orchestrate updates to ensure embeddings are sufficiently fresh without overloading the servers.
How do we measure success and optimize for long-term user satisfaction?
Key metrics include average watch time per session, retention rates (whether users keep returning to the app), or direct engagement signals like likes, comments, shares. However, focusing only on immediate metrics might encourage addictive patterns or short-term success at the cost of user well-being. Some teams incorporate additional signals:
Long-term retention metrics, such as the probability of a user returning daily or weekly. Satisfaction surveys or explicit feedback forms. Balanced engagement that correlates with healthy usage patterns rather than purely addictive behaviors.
A pitfall is that short videos make it tempting to drive up watch counts. Real engagement can come from deeper user-video interactions. Calibrating the objective function to handle short-term and long-term signals is a major engineering and product challenge.
Below are additional follow-up questions
How do we incorporate monetization or ad-based content in the 'For You' feed while preserving user experience?
Ads are a critical revenue stream on TikTok, yet their placement must be handled delicately to avoid degrading user engagement. One approach is to integrate sponsored content directly within the ranking pipeline, treating ads or branded content as items that can be recommended. However, instead of ranking them purely on predicted engagement, a separate ad-serving policy might determine how frequently ads are injected.
A common strategy involves multi-slot ranking, where each content slot is either an organic video or an ad. The system uses separate models or distinct scoring functions for ads versus organic content. Balancing user experience with revenue can require constraints like maximum ad frequency, or a cap on consecutive ad impressions. For instance, the pipeline might allocate one ad slot per certain number of videos.
Pitfalls and edge cases include:
Over-insertion of ads that causes user churn. A system that doesn’t carefully track user tolerance to ads may push them away from the platform. Low relevance ads eroding user trust. If users feel ads are irrelevant or intrusive, they may develop negative sentiment toward the platform. Difficulty measuring direct revenue from short-form ads. The system might optimize short-term clicks instead of long-term brand or user loyalty. Regulatory constraints around how ads are disclosed. The app must ensure users can distinguish sponsored content from organic videos.
A practical example is to maintain an “ad score” for each candidate ad based on relevance and predicted conversion probability. The final pipeline can do a combined re-ranking step, ensuring an appropriate ratio of ads to organic content. If the predicted user dissatisfaction from seeing one more ad is too high (inferred from user dwell time or skip patterns), the system defers or reduces ad frequency.
How do we handle malicious or noisy user signals that might degrade the recommendation system's quality?
Malicious or noisy signals occur when user interaction data doesn’t reflect genuine content preferences. This may happen with bots, automated loops, or deliberate manipulations (e.g., large groups artificially inflating a video’s engagement counts).
One solution is to detect anomalous patterns that deviate from typical user engagement. Features such as the velocity of likes, suspicious watch patterns (e.g., extremely short watch times but high like counts), or repeated replays on multiple accounts from a single IP can flag suspicious activity.
Possible mitigation steps:
Filtering out or downweighting suspicious interactions during training and inference. The system might apply a filter or gating function that sets the weight of the suspicious data to zero if a threshold is exceeded. Using robust ranking objectives. For instance, the recommendation model might treat extremely high engagement velocity with suspicion, discounting it until it’s confirmed to be genuine. Applying adversarial or robust machine learning techniques to reduce the effect of abnormal signals.
Pitfalls:
False positives that exclude legitimate content. An overly aggressive filter might penalize authentic viral trends simply because they ramped up quickly. Evolving malicious behaviors that circumvent detection. Attackers or bots change their strategies when they realize how the platform detects them.
How would we introduce interpretability or transparency into the recommendation algorithm, especially to comply with regulations or user demands for explanation?
Interpretability can be provided at varying granularity. One approach is to surface to the user a simplified statement, such as “You’re seeing this video because you’ve shown interest in dance tutorials.” Under the hood, the platform can use model explainability techniques to identify which features most influenced the recommendation score.
Techniques like Integrated Gradients or SHAP can help measure feature importance in complex deep models. However, these are computationally expensive for real-time explanations. A typical compromise is precomputing local explanations for representative user segments or sampling.
In a regulated environment, the system might be required to offer user-facing controls that let them adjust certain aspects of their preference profile. For instance, a user can remove or downweight certain interest categories in their personalized feed.
Potential pitfalls:
Computational overhead, as generating explanations for each ranking at scale can be prohibitively expensive. Over-simplification, which may risk misrepresenting how the model truly works and could lead to confusion or mistrust if the explanation is too generic. Revealing too much about the model’s internal logic can open the door for adversarial manipulation.
How do we handle real-time trending events or ephemeral content that see rapid user engagement for a short time, then quickly fade?
Real-time trending is a prime driver of viral content on TikTok. The system must quickly recognize these surges and surface them to relevant users before trends fade. A typical approach is to maintain a streaming service that monitors engagement metrics (likes, shares, watch completions) for each piece of content or hashtag in near real-time.
The platform can assign a “trendiness” or “burstiness” score for content that exhibits unusual spikes in engagement. This score can be factored into candidate generation or ranking:
If a video is trending in a relevant user’s region or within a content cluster that user frequently engages with, the “trendiness” feature might boost it in the ranking. If a trend has cooled down, the system gradually reduces the boost to avoid stale content dominating feeds.
Pitfalls include:
Overly amplifying quick bursts that may not be genuinely high-quality or relevant for many users. System lag where the trending detection pipeline is slow and misses the prime window of user interest. Excessive trending diversity can overshadow each user’s more stable personal interests.
How do we manage multi-objective optimization for the recommendation (e.g. combining user engagement with brand safety or user well-being)?
In practice, platforms often juggle multiple, potentially conflicting objectives: maximizing watch time, ensuring brand safety, promoting healthy usage patterns, etc. One approach is to define a composite objective function that weights each metric. Another approach is multi-head neural networks, each predicting a different outcome (e.g., watch time vs. probability of harmful content), followed by a post-processing step that merges the predictions according to certain constraints.
For instance:
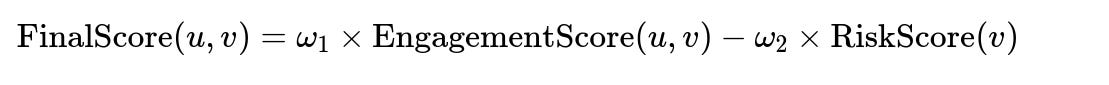
Here, “EngagementScore” might reflect predicted watch time or like probability, while “RiskScore” might capture brand safety or policy violations. We subtract risk from engagement since we want to penalize content that is borderline violating guidelines.
Pitfalls:

In what ways can we incorporate user-initiated feedback such as 'Not Interested' or 'Report' signals, and how do we weigh them relative to positive engagement signals?
Explicit negative feedback (like tapping “Not Interested”) is very informative but occurs less frequently compared to implicit signals (watch time, likes, shares). Because it’s a rarer signal, it typically gets a higher weight in the training data or inference pipeline. A single user-initiated negative signal might heavily reduce the probability of seeing similar content in the future.
Implementation details could include:
Tracking these signals in the user’s preference profile. For example, if the user clicks “Not Interested” in a certain topic or hashtag, reduce that topic’s weight in the user embedding. In the training set, label videos for which a user indicated “Not Interested” as strong negative samples to help the model learn which content to avoid.
Pitfalls:
Users might occasionally tap “Not Interested” by accident, or do so for reasons unrelated to genuine disinterest. Overreacting to these signals might degrade personalization. A small subset of users might overuse the negative feedback button, skewing the data distribution.
What is the approach to handle harmful or sensitive content in the ranking system while balancing free expression and brand safety concerns?
Platforms must detect harmful content, such as hate speech, violent or sexual content, or misinformation. Common practice involves a combination of:
Automated detection. Models trained on textual, visual, and audio cues. Human review for borderline or flagged content. Policy-driven thresholds that remove or downrank content classified above a certain risk level.
When content is borderline but not explicitly disallowed, the system might downrank it to limit its distribution. The tension between free expression and brand safety arises because stricter filters might remove legitimate content, potentially angering some users or stifling creativity.
Pitfalls:
False positives that suppress normal user expression. Evolving definitions of harmful or sensitive content across cultural contexts. Sophisticated adversaries who adapt their strategies to bypass detection, such as coded language or subtle variations of harmful content.
What strategies can we use for cross-platform synergy, i.e. how do we leverage user behavior from sister apps or websites to refine recommendations on TikTok?
If a company owns multiple platforms, cross-platform data can significantly enrich user embeddings. For instance, if a user interacts heavily with cooking tutorials on a sister site, TikTok can infer the user might like short-form cooking videos as well. The synergy might involve:
Unified user IDs or identity resolution across platforms. Aggregating content category preferences from sister apps into the user’s TikTok profile. Periodically retraining embeddings with combined logs.
Challenges and pitfalls:
Data privacy: sharing data across platforms may require explicit user consent, especially in regions with strict privacy regulations. Data mismatch: user behavior on a news-focused site may not translate perfectly to short-form video preferences. Synchronization overhead: if cross-platform data is updated too slowly, it might not capture the user’s latest shift in interests.
Are there any potential benefits to employing reinforcement learning for the ranking algorithm, and how might we implement it in a short-form video environment?
Reinforcement learning (RL) allows an agent to optimize decisions based on long-term rewards, such as user retention or daily return rate. Traditional recommendation systems often maximize immediate signals (like watch time on the next video), while RL can incorporate delayed rewards.
To implement RL:
Define the state as the user’s profile, watch history, or short-term context. Define actions as which video to show next (or which set of videos). Define a reward signal that reflects short-term engagement plus long-term user retention or satisfaction.
An offline approach might involve training on historical logs, simulating a policy that would have shown different content. Online, an RL agent can conduct limited exploration to discover better policies.
Pitfalls:
High exploration risk. Serving random or suboptimal content can harm user experience if done excessively. Sparse or delayed rewards. A user’s decision to leave or return the next day might be influenced by many external factors. Complex implementation. RL-based recommender systems are harder to debug and require advanced infrastructure to handle real-time feedback loops.
How do we handle A/B testing at scale for a large user base to measure the impact of ranking updates, and what pitfalls should we avoid?
A/B testing is vital for iterating on the recommendation system in a data-driven way. With a massive user base, TikTok can run numerous experiments simultaneously, but it must ensure that experiment segments do not overlap or confound each other.
Key considerations:
Randomization. Users should be randomly assigned to test or control groups in a way that ensures statistical fairness. Sufficient test duration. Let each experiment run long enough to capture a stable signal and avoid novelty effects. Robust metrics. Look beyond short-term engagement, track retention and other success metrics.
Pitfalls:
Interaction effects among multiple experiments. If the same user is in two or more overlapping experiments, it becomes harder to isolate the impact of each. Unstable or drifting user population. If large events or marketing campaigns drastically change the user base mid-test, the results may be skewed. Unobserved biases in random assignment. In practice, random assignment can fail if user segments are inadvertently correlated with assignment logic.