
ML Interview Q Series: Probability via Sample Space: Solving the Three Balls, One Empty Box Problem

Browse all the Probability Interview Questions here.
Question: Three balls are randomly dropped into three boxes, where any ball is equally likely to fall into each box. Specify an appropriate sample space and determine the probability that exactly one box will be empty.
Short Compact solution
Label the balls and boxes as 1, 2, and 3. Consider the ordered sample space of all 3-tuples (b1, b2, b3), where b i denotes the box chosen by ball i. There are 3^3 = 27 equally likely outcomes. Let A i be the event that box i is the only empty box. Then P(A1 ∪ A2 ∪ A3) = 3 P(A1) by symmetry. To compute P(A1), we want exactly two balls in box 2 or box 3 and one ball in the other of those two boxes (but none in box 1). The count of ways to place the balls so that box 1 is empty and the other two boxes have all three balls between them, with at least one ball in each, is 6. Thus P(A1) = 6/27 = 2/9. Consequently, the probability of exactly one empty box is 3 × (2/9) = 2/3.
Comprehensive Explanation
Sample Space Construction
We label each ball distinctly as ball 1, ball 2, and ball 3, and likewise label each box distinctly as box 1, box 2, and box 3. Each ball can land in any one of the three boxes with equal probability. An outcome in the sample space is then an ordered triple (b1, b2, b3), where b i ∈ {1, 2, 3} represents the box chosen by ball i. Since there are 3 choices for ball 1, 3 choices for ball 2, and 3 choices for ball 3, the total number of outcomes is 3^3 = 27, each equally likely.
Defining the Events
Let A1 be the event that only box 1 is empty (meaning no ball lands in box 1, but boxes 2 and 3 each have at least one ball). Similarly, define A2 and A3 for boxes 2 and 3 being the only empty box, respectively. These three events are mutually disjoint because only one box can be the unique empty box in any given outcome.
By symmetry, each of these events A1, A2, and A3 has the same probability. Hence, the probability that exactly one box is empty is the sum:

Computing P(A1)
To find P(A1), we must count all outcomes in which box 1 is empty, and boxes 2 and 3 contain all three balls in such a way that each has at least one ball. Specifically, we can split the three labeled balls between box 2 and box 3 in two ways:
Two balls go into box 2 and one ball goes into box 3.
Two balls go into box 3 and one ball goes into box 2.
Given three distinct balls, we can choose which two go together in (3 choose 2) = 3 ways for each of the two scenarios above. Hence, total valid outcomes for A1 is 2 × 3 = 6. Since the entire sample space has 27 equally likely outcomes, we have:
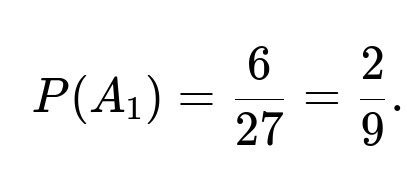
Final Probability
Because of the symmetry argument, P(A2) = P(A1) and P(A3) = P(A1). So the probability of exactly one box being empty is:
Thus, the probability that there is exactly one empty box is 2/3.
A Quick Python Enumeration (Optional)
Below is a small Python snippet showing how one could confirm this result by enumerating all outcomes:
count_exactly_one_empty = 0
total_outcomes = 0
boxes = [1, 2, 3] # labeled boxes
for b1 in boxes:
for b2 in boxes:
for b3 in boxes:
total_outcomes += 1
# Track occupancy
occupancy = {1: 0, 2: 0, 3: 0}
occupancy[b1] += 1
occupancy[b2] += 1
occupancy[b3] += 1
# Check how many boxes are empty
empty_count = sum(1 for k in occupancy if occupancy[k] == 0)
if empty_count == 1:
count_exactly_one_empty += 1
probability = count_exactly_one_empty / total_outcomes
print(probability) # Should output 0.6666666667 (i.e. 2/3)
Follow-up Question 1
How would the probability change if the three balls were indistinguishable (but the boxes are still distinct)?
When balls are indistinguishable, we no longer treat (b1, b2, b3) differently from permutations of the same distribution. The distinct sample space size changes accordingly. Instead of 3^3 labeled outcomes, we would classify outcomes by counts (how many balls go in each box). Possible distributions of 3 indistinguishable balls into 3 distinct boxes are:
(3, 0, 0), (0, 3, 0), (0, 0, 3)
(2, 1, 0), (2, 0, 1), (1, 2, 0), (1, 0, 2), (0, 2, 1), (0, 1, 2)
(1, 1, 1)
Each distribution has a certain number of micro-states if we were to re-label the balls, but for indistinguishable balls, each distinct distribution is considered one outcome. For exactly one box to be empty, we need a distribution that is of the form (2,1,0) in some permutation. There are 3 permutations of that pattern (since any one of the three boxes can be the empty box). Thus, we would see 3 ways. Meanwhile, the total number of ways to distribute 3 indistinguishable balls among 3 distinct boxes is 1 (for 3,0,0) + 3 (for 2,1,0) + 1 (for 1,1,1) = 5. So the probability in a purely “indistinguishable-balls” sense, if each distribution is considered equally likely, would be 3/5.
However, in many real-world scenarios, it is more natural that each ball is equally likely to go into any box independently (making them effectively labeled in terms of probability). Hence the original 2/3 result stands under that usual assumption.
Follow-up Question 2
What if the boxes were not all equally likely for each ball (i.e., each ball lands in box i with some probability p i that may differ)?
If each ball has a different probability of falling into each box, the sample space and event definitions still hold, but outcomes are no longer equally likely. Instead of 1/27 for each triple, the probability of (b1, b2, b3) becomes p(b1) × p(b2) × p(b3), where p(b i ) is the probability a single ball falls in box b i. In that case, computing “exactly one box is empty” typically requires summing over all patterns that yield zero occupancy in one box and non-zero occupancy in the other two boxes. The result depends on the exact probabilities p1, p2, p3. One would typically do:
Compute probability that box 1 is empty and boxes 2, 3 are non-empty.
Do the same for box 2 empty, and for box 3 empty.
Sum these mutually exclusive events.
The counting approach needs to be replaced by direct probability multiplication across each valid (b1, b2, b3) triple.
Follow-up Question 3
What is the probability that no box is empty (i.e., every box has at least one ball)?
From the original 27 equally likely outcomes (when balls and boxes are all labeled and each ball is equally likely to go into each box), we just need to exclude any arrangement where at least one box is empty. It is often easier to compute this via complementary events:
Probability(at least one box is empty) = Probability(exactly one box is empty) + Probability(two boxes are empty).
We know Probability(exactly one box is empty) = 2/3 from above.
Probability(two boxes are empty) occurs only if all three balls go into one box. There are 3 ways for that (all in box 1, or box 2, or box 3), each with probability 1/27, so Probability(two boxes are empty) = 3/27 = 1/9.
Hence Probability(no box is empty) = 1 − (2/3 + 1/9) = 1 − (6/9 + 1/9) = 1 − 7/9 = 2/9.
Follow-up Question 4
Could we generalize this result to n balls and m boxes?
Yes. For n balls randomly dropped into m boxes (all equally likely), the probability that exactly k boxes end up empty can be computed using combinatorial reasoning:
Choose which k boxes are empty.
Distribute all n balls into the remaining (m − k) boxes in such a way that each of those (m − k) boxes has at least one ball.
Divide by the total number of ways to place n balls into m boxes, which is m^n.
When k = 1 specifically for m = 3, it matches the original question. For larger n and m, the process is typically handled with the inclusion-exclusion principle or a straightforward occupancy-based approach.
All these variations show how general combinatorial or probabilistic arguments adapt to different constraints, a common technique in probability and many branches of machine learning (particularly in distribution-based problems or occupancy models).
Below are additional follow-up questions
Follow-up Question 5
What if we are asked to find the expected number of empty boxes after dropping the three balls?
When each of the three balls is equally likely to go into any of the three boxes (with probability 1/3 per box for each ball independently), we can define a random variable X to be the number of empty boxes. To find E(X), one intuitive approach is to use indicator random variables:
Let I1 be the indicator that box 1 is empty, I2 for box 2, and I3 for box 3.
Then X = I1 + I2 + I3, and the linearity of expectation gives E(X) = E(I1) + E(I2) + E(I3).
Because of symmetry, E(I1) = E(I2) = E(I3). So E(X) = 3 * E(I1).
To compute E(I1), we need the probability that box 1 is empty. That probability is (2/3)^3, because for box 1 to be empty, each of the three balls must go to either box 2 or box 3. Specifically:
Probability(box 1 is empty) = (2/3)^3 = 8/27.
Hence E(I1) = 8/27, and
E(X) = 3 * (8/27) = 24/27 = 8/9.
Therefore, the expected number of empty boxes after dropping three balls into three boxes (with uniform probability) is 8/9. A common pitfall is to think we should only consider the events of “exactly one empty box” or “two boxes empty” but ignoring the linearity of expectation can lead to confusion. Even though the result 8/9 might look non-integer, it is perfectly valid for an expectation of a discrete variable.
Follow-up Question 6
How does the probability of exactly one empty box change if the experiment is repeated multiple times and we look at the proportion of trials where exactly one box is empty?
If we repeat the experiment T times (T large) under the same conditions—each ball is equally likely to fall into any box independently—the Law of Large Numbers implies that the fraction of trials in which exactly one box is empty will converge (with high probability) to 2/3, which we previously computed for the single trial. The conceptual pitfall is to assume some “regression to the mean” scenario might alter single-trial probabilities. However, each trial is independent, so the probability remains 2/3 for each new trial, and the empirical proportion will stabilize around 2/3 as T grows.
Follow-up Question 7
What if each box can hold at most 2 balls? Does the probability of exactly one empty box remain the same, or change?
In this scenario, we must exclude any outcomes where more than 2 balls end up in the same box. Since we have only 3 balls, the only invalid outcome is the one with all 3 balls in the same box. We would proceed as follows:
Original sample space size is 27 equally likely outcomes.
Subtract the 3 outcomes where all 3 balls go to the same box (because that violates the capacity constraint). So the valid sample space has 24 outcomes.
Exactly one box empty means: one box gets 0 balls, and the other two together hold 3 balls without exceeding the capacity of 2 per box.
If box 1 is empty, we need boxes 2 and 3 to share the 3 balls in a pattern that does not exceed 2 in one box. Possible distributions: (2,1) or (1,2).
Count the ways to choose which 2 balls go together if we have a (2,1) split. That is 3 ways to choose the pair, and similarly 3 ways for (1,2). In total 6 ways if box 1 is empty.
Because of symmetry, the same count of 6 applies when box 2 is empty or box 3 is empty. Thus we have 3 * 6 = 18 valid outcomes that produce exactly one empty box. Given the valid sample space (24 equally likely outcomes), the probability is 18/24 = 3/4. A subtle pitfall is forgetting to remove the configurations with 3 balls in one box from the sample space or incorrectly counting them as part of the event. Once we properly exclude them, we see that the probability of exactly one box being empty increases to 3/4 under this capacity constraint.
Follow-up Question 8
What if the probability of a box being empty is partially observed, and we want to use Bayesian updating after seeing some outcomes?
Imagine we drop the balls repeatedly in some real environment, but we suspect that one of the boxes might be “defective” (e.g., it is closed sometimes, so p1 < 1/3). After each trial, we observe which box is empty (if any) and update our beliefs about p1, p2, p3 using Bayesian inference. The main pitfall is to treat each observed distribution as if it occurs with probability 1/3^3 without updating the box probabilities. In reality, we would set a prior distribution over (p1, p2, p3), and each new observation—like “exactly one box is empty and it happens to be box 1”—would affect the posterior distribution of p1, p2, p3. Over many trials, we converge to a maximum a posteriori or Bayesian estimate of the actual probability distribution. This underscores how real-world sampling might differ from the pure mathematical setting where p1 = p2 = p3 = 1/3 is assumed known upfront.
Follow-up Question 9
What if we allow for a dynamic scenario where the probability distribution over boxes changes after each ball is dropped (e.g., a box becomes more or less likely as balls accumulate)?
In such a dynamic or adaptive system, the sample space approach (where each outcome is equally likely) no longer applies because each ball’s probability distribution depends on prior placements. For example, the mechanism might give an advantage to boxes that currently hold fewer balls. To compute the probability that exactly one box is empty at the end:
We would need the transition probabilities from one state (the partial distribution of balls so far) to the next.
A state is described by how many balls are currently in each box.
We track all possible paths through these states from 0 total balls placed to 3 total balls placed.
A possible pitfall is to keep using “1/3 chance for each box” incorrectly. Instead, the correct approach is a Markov chain: each new ball’s distribution depends on the state of occupancy. Then we sum over the probabilities of reaching a final state with exactly one empty box. This often requires a more elaborate approach, such as dynamic programming or direct enumeration of state transitions.
Follow-up Question 10
What if the labeling of balls only matters at the end for certain sets of balls (e.g., we have two identical red balls and one distinct blue ball)?
This partial indistinguishability can lead to a tricky scenario:
We have 2 red balls (indistinguishable from each other) and 1 blue ball (distinct).
The total sample space no longer has 3^3 labeled outcomes for the red balls, because the two red balls are identical. However, for the single blue ball, it does matter which box it goes into.
A naive pitfall is to treat all three balls as fully labeled or as fully indistinguishable. The correct approach is:
Enumerate ways the two red balls can be placed, taking into account they are identical.
For each arrangement of the red balls, place the blue ball in any of the three boxes.
We then see which configurations yield exactly one empty box. The counting is typically done by distinguishing “blue ball’s box” vs. “red ball distribution” patterns. We have to be careful not to double-count or omit valid configurations. This kind of semi-distinguishability often arises in real-world problems (e.g., “two identical sensors and one special sensor”).
When done carefully, the probability might turn out to be different from the 2/3 that we get when all balls are labeled.
Follow-up Question 11
How does one handle continuous generalizations, such as randomly placing intervals or shapes into container intervals?
A more advanced generalization is to imagine continuous analogs—like randomly placing intervals on a line segment (representing boxes in a 1D sense) or shapes in a 2D plane. The notion of “empty box” extends to “empty region,” and the combinatorial count is replaced by integrals or geometric probability arguments. For instance, you might ask: “What is the probability that exactly one interval on a line remains uncovered after placing three smaller intervals randomly?” A real-world pitfall is to assume the discrete approach directly transfers. Instead, we would define a uniform measure over positions (and possibly lengths) of the intervals, then compute continuous measure for the event “exactly one region is uncovered.” Such problems typically require more sophisticated tools like order statistics or geometric probability integration.
Follow-up Question 12
What if each ball chooses its box in a dependent manner, e.g., the second ball avoids the box chosen by the first ball with some probability?
Once we introduce dependence among the ball placements, the standard counting approach (3^3 equally likely outcomes) is invalid. We would need to condition the choice for each ball on the previous balls’ choices. For instance, if the second ball is “more likely” to avoid the box used by the first ball, that modifies the probability distribution. The probability of a given final arrangement of (b1, b2, b3) no longer factors as 1/3 * 1/3 * 1/3. Instead, we have:
P(b1) = 1/3 (assuming the first ball is equally likely).
P(b2 | b1) depends on some conditional rule, e.g., “if box b1 is used by the first ball, avoid it with probability α, otherwise pick among the other two boxes.”
P(b3 | b1, b2) further depends on the new arrangement.
We then must sum over all possible ways that exactly one box is empty, using the chain rule for probabilities. A pitfall is to keep using a simplistic uniform assumption. Real systems (like load balancing, for example) might indeed direct subsequent items away from heavily loaded boxes.